

如何训练VLA?丰田研究院发布史上最大实验规模「保姆级」教程
如何训练VLA?丰田研究院发布史上最大实验规模「保姆级」教程是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚
来自主题: AI技术研报
8780 点击 2026-03-08 10:38
是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

现在,一篇来自 CISPA 亥姆霍兹信息安全中心的最新论文《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》为我们揭开了一点谜底:那些你花真金白银购买的「第三方 API」,有可能偷偷把前沿大模型换成了廉价的替代品。
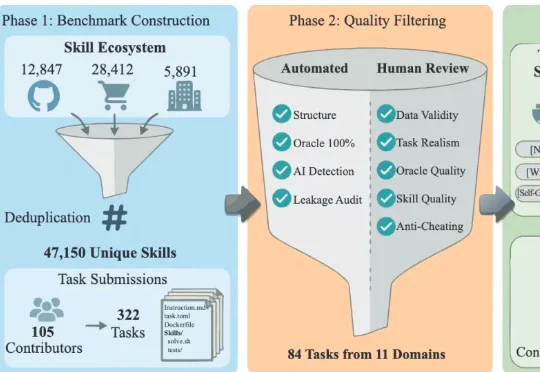
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1,

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
昨天,Thinking Maching Lab 研究者、斯坦福大学博士生 Zitong Yang 正式完成了他的博士论文答辩,课题为「持续自我提升式 AI」(Continually self-improving AI),并且他在答辩完成后很快就放出了自己的答辩视频,从中我们可以看到他对未来 AI 发展路径的系统性探索。
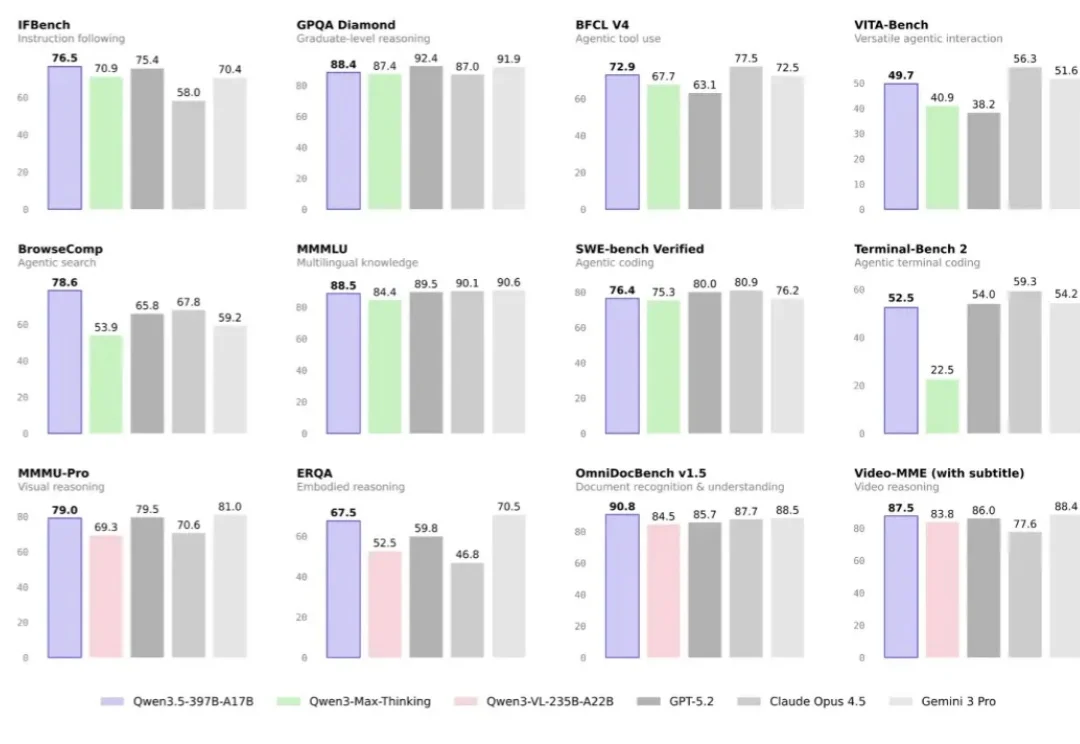
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。

AI 搜索引擎正逐渐取代传统搜索入口,「问 AI」已经成为日常习惯。随着 OpenAI 宣布在 ChatGPT 中引入商业推荐,搜索与内容分发的边界正在被重新定义。在这样的环境下,你的内容能否在 AI 搜索中成为「爆款」,不再只取决于标题和流量,而是更大程度取决于 AI 本身的引用偏好。
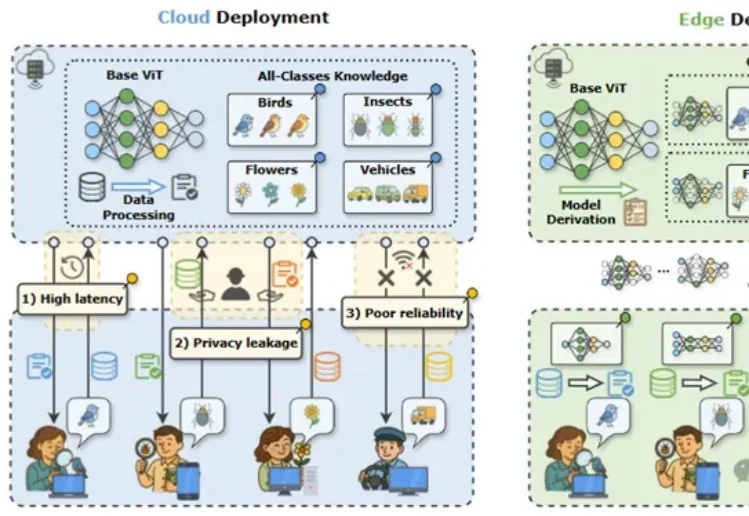
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。