

视频上下文学习!大模型学会“照猫画虎”生成,结合模拟器还能精准控制真实环境交互,来自MSRA
视频上下文学习!大模型学会“照猫画虎”生成,结合模拟器还能精准控制真实环境交互,来自MSRA视频生成也能参考“上下文”?!
来自主题: AI技术研报
9645 点击 2024-07-17 19:17
视频生成也能参考“上下文”?!
AI侵权又来了……
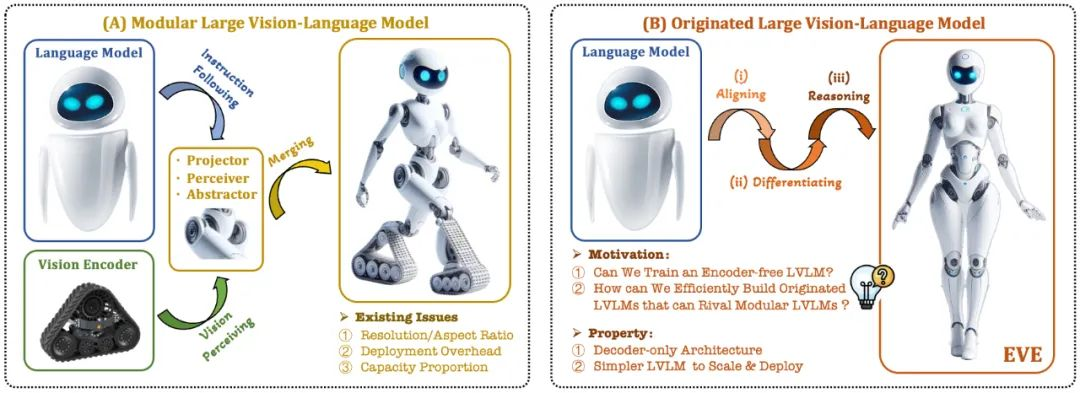
近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。

假如你有闲置的设备,或许可以试一试。
最核心的Claude 3.5编码系统提示,火遍Reddit社区。就在刚刚,原作者发布了进化后的第二版,有的网友已经将其加入工作流。

MoE已然成为AI界的主流架构,不论是开源Grok,还是闭源GPT-4,皆是其拥趸。然而,这些模型的专家,最大数量仅有32个。最近,谷歌DeepMind提出了全新的策略PEER,可将MoE扩展到百万个专家,还不会增加计算成本。

无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

HBM因AI大模型训练需求爆增,市场火热。
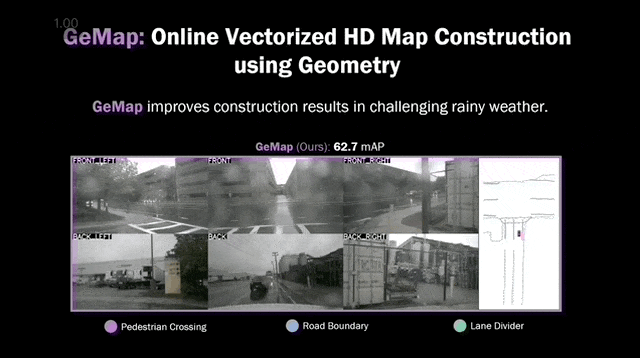
用几何图形来实时构建高精地图,真香!

最近,多个机构学者合著的一篇研究为AI的规模化指了一条新路:物理神经网络(PNN),这一新兴的前沿领域还鲜少有人涉足,但绝对值得深耕!AI模型再扩展1000倍的秘密可能就藏在这里。