

7B最强长视频模型! LongVA视频理解超千帧,霸榜多个榜单
7B最强长视频模型! LongVA视频理解超千帧,霸榜多个榜单为什么说理解长视频难如 “大海捞针”?
来自主题: AI技术研报
10715 点击 2024-07-14 13:38
为什么说理解长视频难如 “大海捞针”?
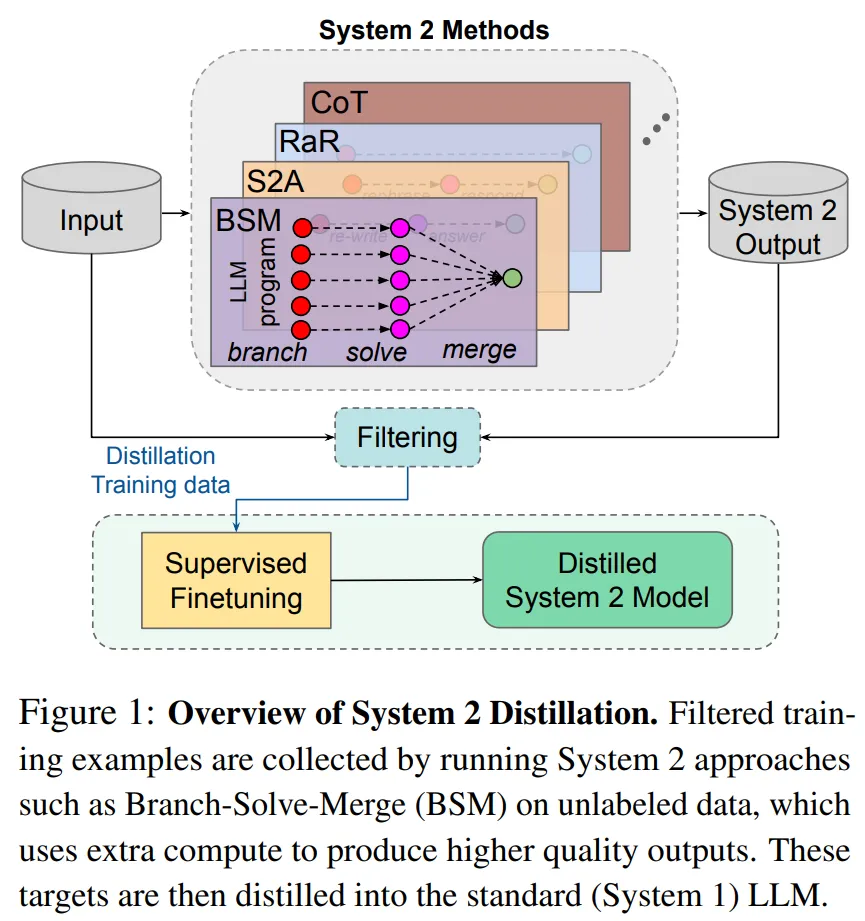
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。

AI 代理得越来越重要,能够实现自主决策和解决问题。为了有效运作,这些代理需要一个确定最佳行动方案的规划过程,然后执行计划的行动。

当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。

文生图、文生视频,视觉生成赛道火热,但仍存在亟需解决的问题。

自从大型 Transformer 模型逐渐成为各个领域的统一架构,微调就成为了将预训练大模型应用到下游任务的重要手段
论老黄卖铲子的技术含量。

生成式模型原本被设计来模仿人类的各种复杂行为,但人们普遍认为它们最多只能达到与其训练数据中的专家相当的水平。不过,最新的研究突破了这一限制,表明在特定领域,如国际象棋,通过采用低温采样技术,这些模型能够超越它们所学习的那些专家,展现出更高的能力。

时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。