

田渊栋等人新作:突破内存瓶颈,让一块4090预训练7B大模型
田渊栋等人新作:突破内存瓶颈,让一块4090预训练7B大模型3 月 6 日,田渊栋又一项研究出炉,这次,他们主攻 LLM 内存效率。除了田渊栋本人,还有来自加州理工学院、德克萨斯大学奥斯汀分校以及 CMU 的研究者。
来自主题: AI技术研报
11513 点击 2024-03-08 15:07
3 月 6 日,田渊栋又一项研究出炉,这次,他们主攻 LLM 内存效率。除了田渊栋本人,还有来自加州理工学院、德克萨斯大学奥斯汀分校以及 CMU 的研究者。

牛津大学 VGG 实验室 Andrew Zisserman 团队最新工作系统性解决了任意物体的遮挡补全问题,并且为这一问题提出了一个新的更加精确的评估数据集。该工作受到了 MPI 大佬 Michael Black、CVPR 官方账号、南加州大学计算机系官方账号等在 X 平台的点赞。

半年多来,Meta 开源的 LLaMA 架构在 LLM 中经受了考验并大获成功(训练稳定、容易做 scaling)。

模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。

虽然 AI 生图领域,看似百花齐放,但论资排辈,Midjourney、Stability AI 还是很受用户欢迎的。就算是竞争对手,Midjourney 也不至于禁止 Stability AI 员工使用其软件吧。

在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,

去年 12 月,新架构 Mamba 引爆了 AI 圈,向屹立不倒的 Transformer 发起了挑战。如今,谷歌 DeepMind「Hawk 」和「Griffin 」的推出为 AI 圈提供了新的选择。

近期,清华大学和哈尔滨工业大学联合发布了一篇论文:把大模型压缩到 1.0073 个比特时,仍然能使其保持约 83% 的性能!
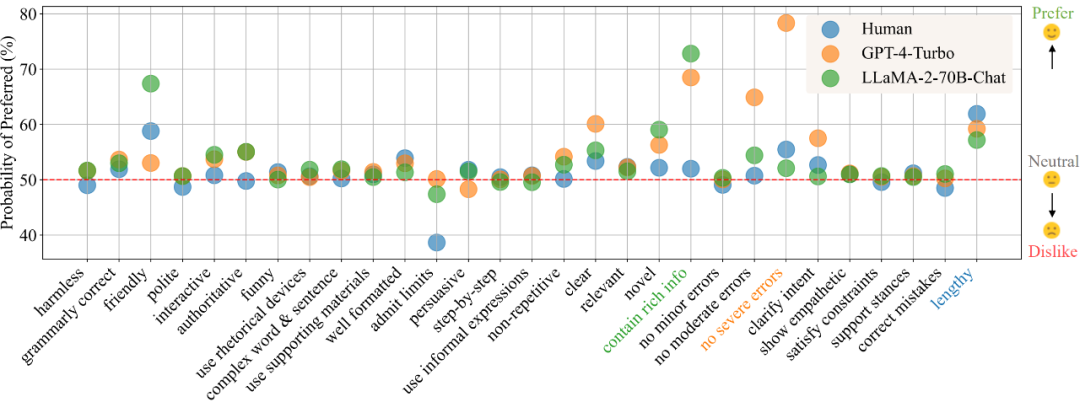
在目前的模型训练范式中,偏好数据的的获取与使用已经成为了不可或缺的一环。在训练中,偏好数据通常被用作对齐(alignment)时的训练优化目标,如基于人类或 AI 反馈的强化学习(RLHF/RLAIF)或者直接偏好优化(DPO),而在模型评估中,由于任务的复杂性且通常没有标准答案,则通常直接以人类标注者或高性能大模型(LLM-as-a-Judge)的偏好标注作为评判标准。
GPT早已成为大模型时代的基础。国外一位开发者发布了一篇实践指南,仅用60行代码构建GPT。