

模型融合、混合专家、更小的LLM,几篇论文看懂2024年LLM发展方向
模型融合、混合专家、更小的LLM,几篇论文看懂2024年LLM发展方向在过去的 2023 年中,大型语言模型(LLM)在潜力和复杂性方面都获得了飞速的发展。展望 2024 年的开源和研究进展,似乎我们即将进入一个可喜的新阶段:在不增大模型规模的前提下让模型变得更好,甚至让模型变得更小。
来自主题: AI技术研报
6237 点击 2024-02-22 15:31
在过去的 2023 年中,大型语言模型(LLM)在潜力和复杂性方面都获得了飞速的发展。展望 2024 年的开源和研究进展,似乎我们即将进入一个可喜的新阶段:在不增大模型规模的前提下让模型变得更好,甚至让模型变得更小。
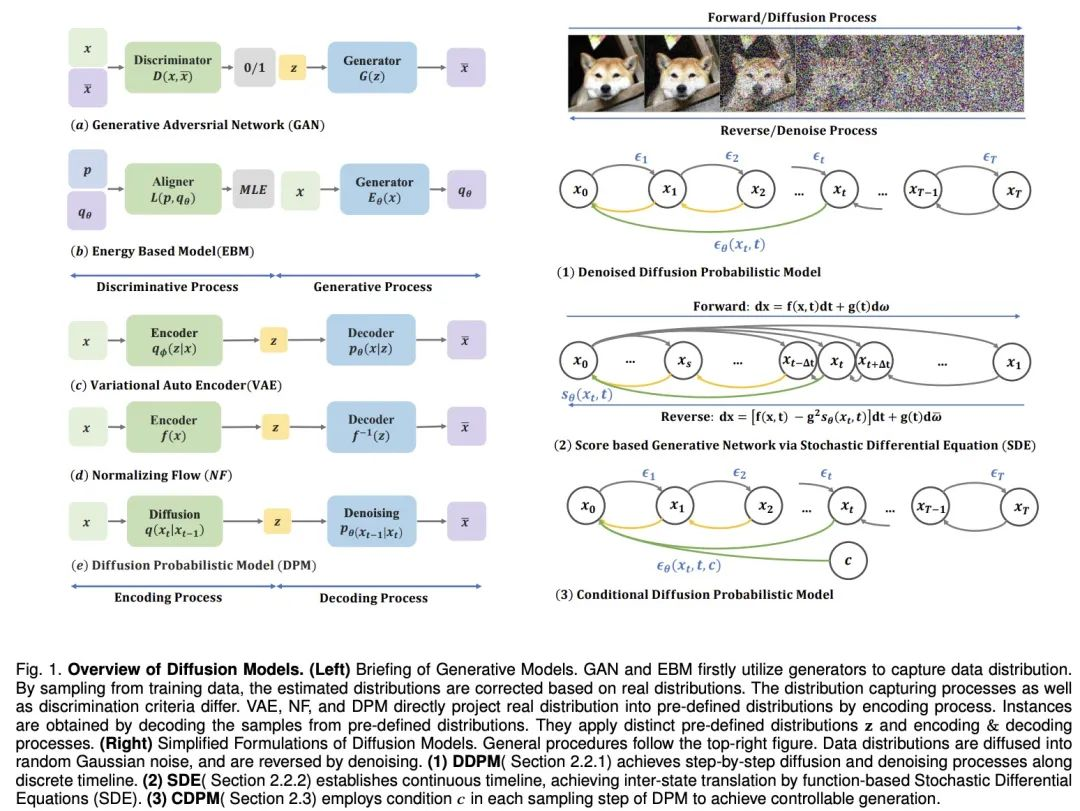
为了使机器具有人类的想象力,深度生成模型取得了重大进展。这些模型能创造逼真的样本,尤其是扩散模型,在多个领域表现出色。扩散模型解决了其他模型的限制,如 VAEs 的后验分布对齐问题、GANs 的不稳定性、EBMs 的计算量大和 NFs 的网络约束问题。

大语言模型之大,成本之高,让模型的稀疏化变得至关重要。

在微调大型模型的过程中,一个常用的策略是“知识蒸馏”,这意味着借助高性能模型,如GPT-4,来优化性能较低的开源模型。这种方法背后隐含的哲学理念与logos中心论相似,把GPT-4等模型视为更接近唯一的逻辑或真理的存在。
过去几天,OpenAI 非常热闹,先有 AI 大牛 Andrej Karpathy 官宣离职,后有视频生成模型 Sora 撼动 AI 圈。

视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。

尽管收集人类对模型生成内容的相对质量的标签,并通过强化学习从人类反馈(RLHF)来微调无监督大语言模型,使其符合这些偏好的方法极大地推动了对话式人工智能的发展。

普林斯顿大学和DeepMind的科学家用严谨的数学方法证明了大语言模型不是随机鹦鹉,规模越大能力一定越大。

检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。
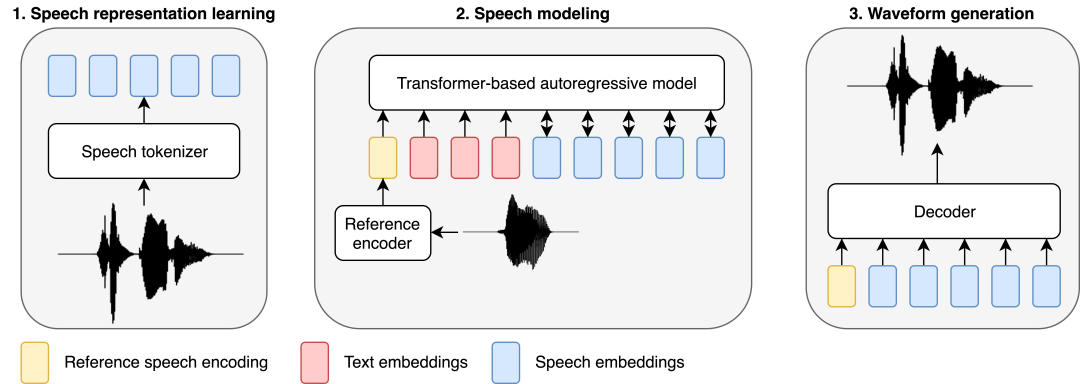
伴随着生成式深度学习模型的飞速发展,自然语言处理(NLP)和计算机视觉(CV)已经经历了根本性的转变,从有监督训练的专门模型,转变为只需有限的明确指令就能完成各种任务的通用模型