

性能提升、成本降低,这是分布式强化学习算法最新研究进展
性能提升、成本降低,这是分布式强化学习算法最新研究进展分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。
来自主题: AI技术研报
3151 点击 2024-02-13 14:05
分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。

最近,UIUC苹果华人提出了一个通用智能体框架CodeAct,通过Python代码统一LLM智能体的行动。

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。
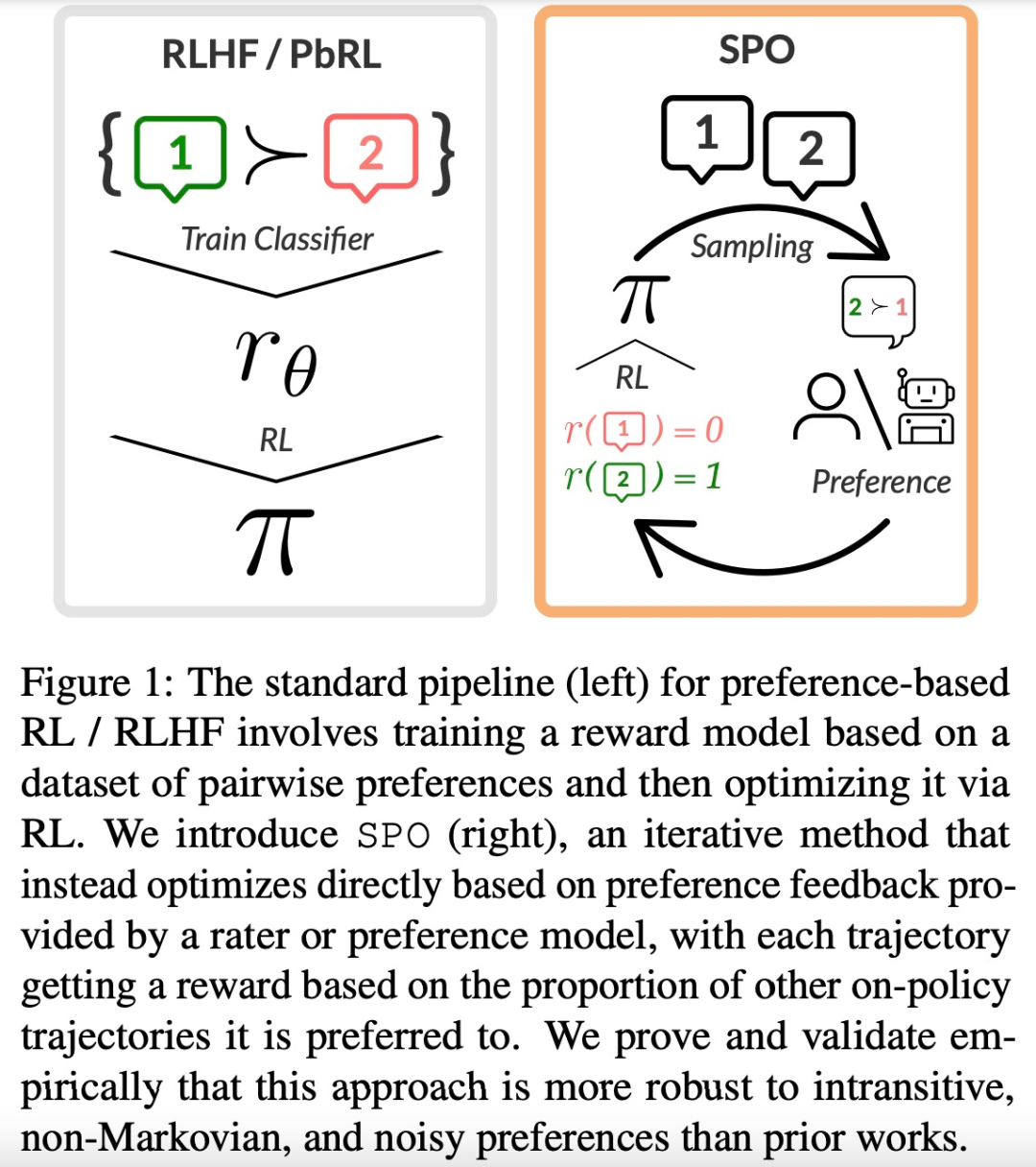
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
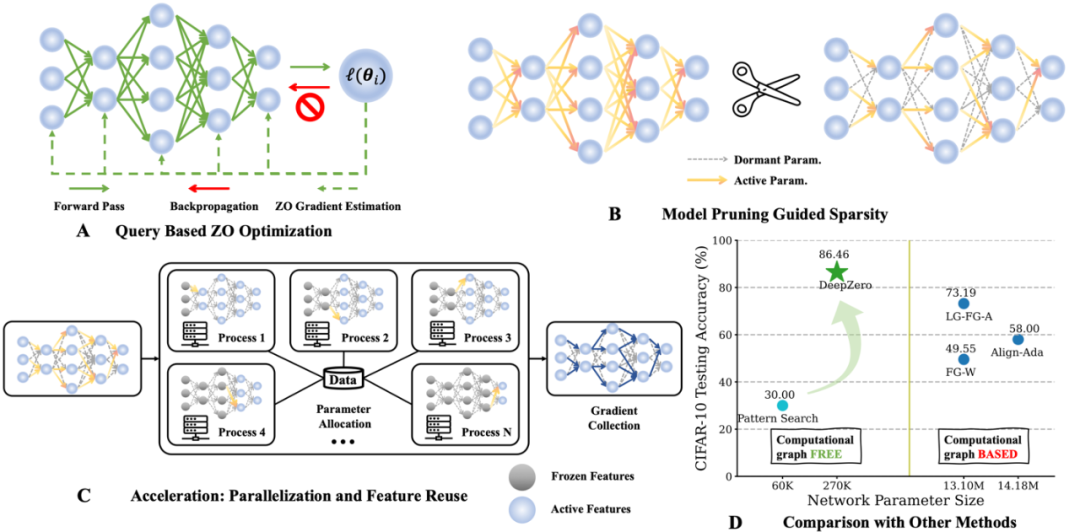
今天介绍一篇密歇根州立大学 (Michigan State University) 和劳伦斯・利弗莫尔国家实验室(Lawrence Livermore National Laboratory)的一篇关于零阶优化深度学习框架的文章 ,本文被 ICLR 2024 接收,代码已开源。

2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。
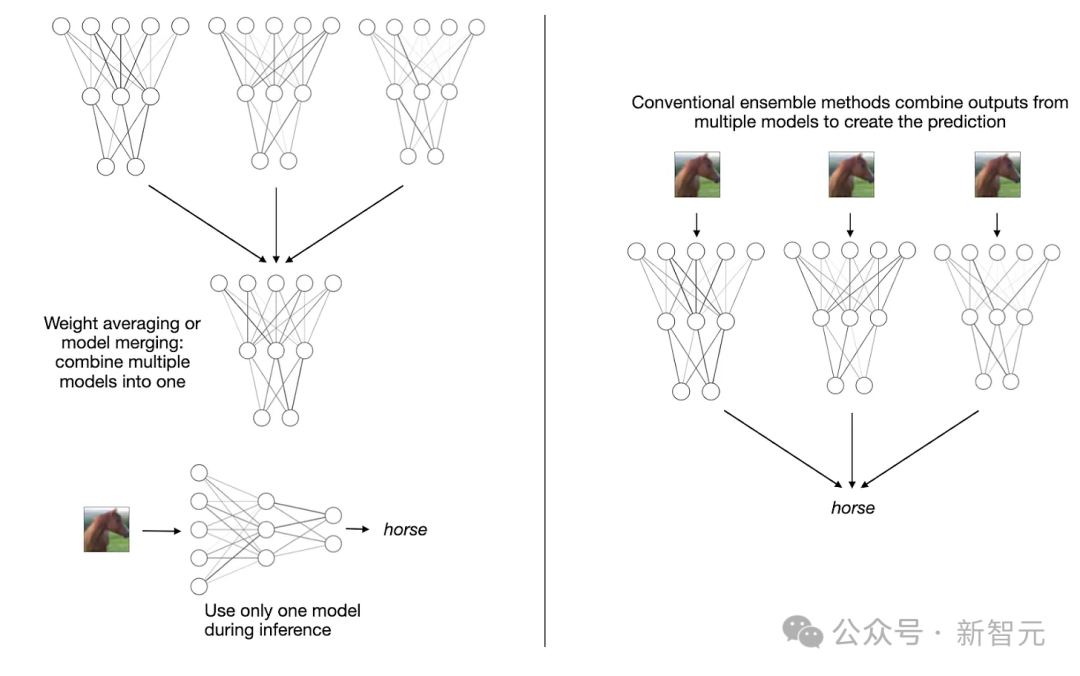
AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。
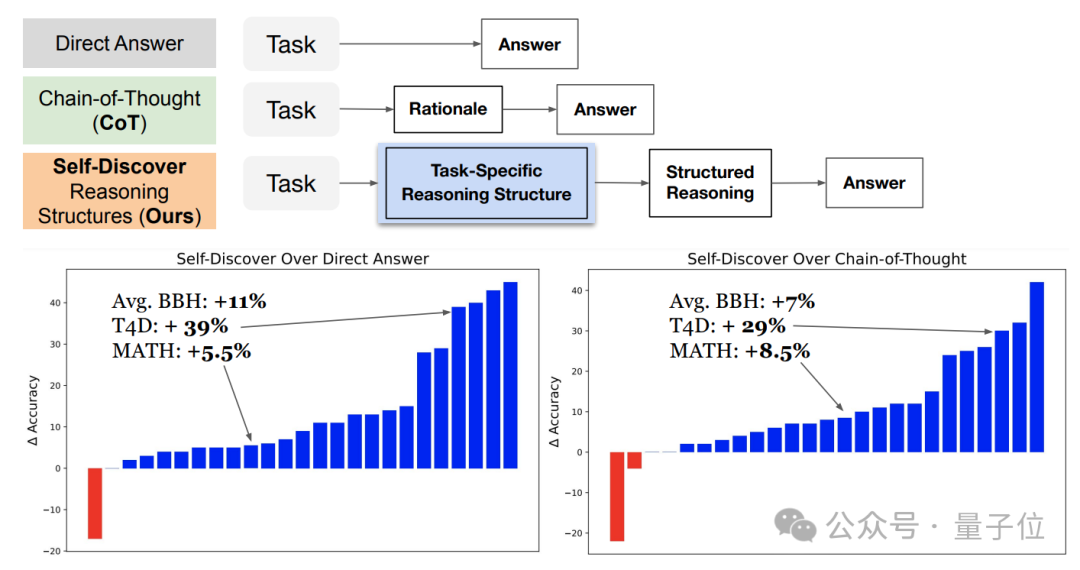
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。
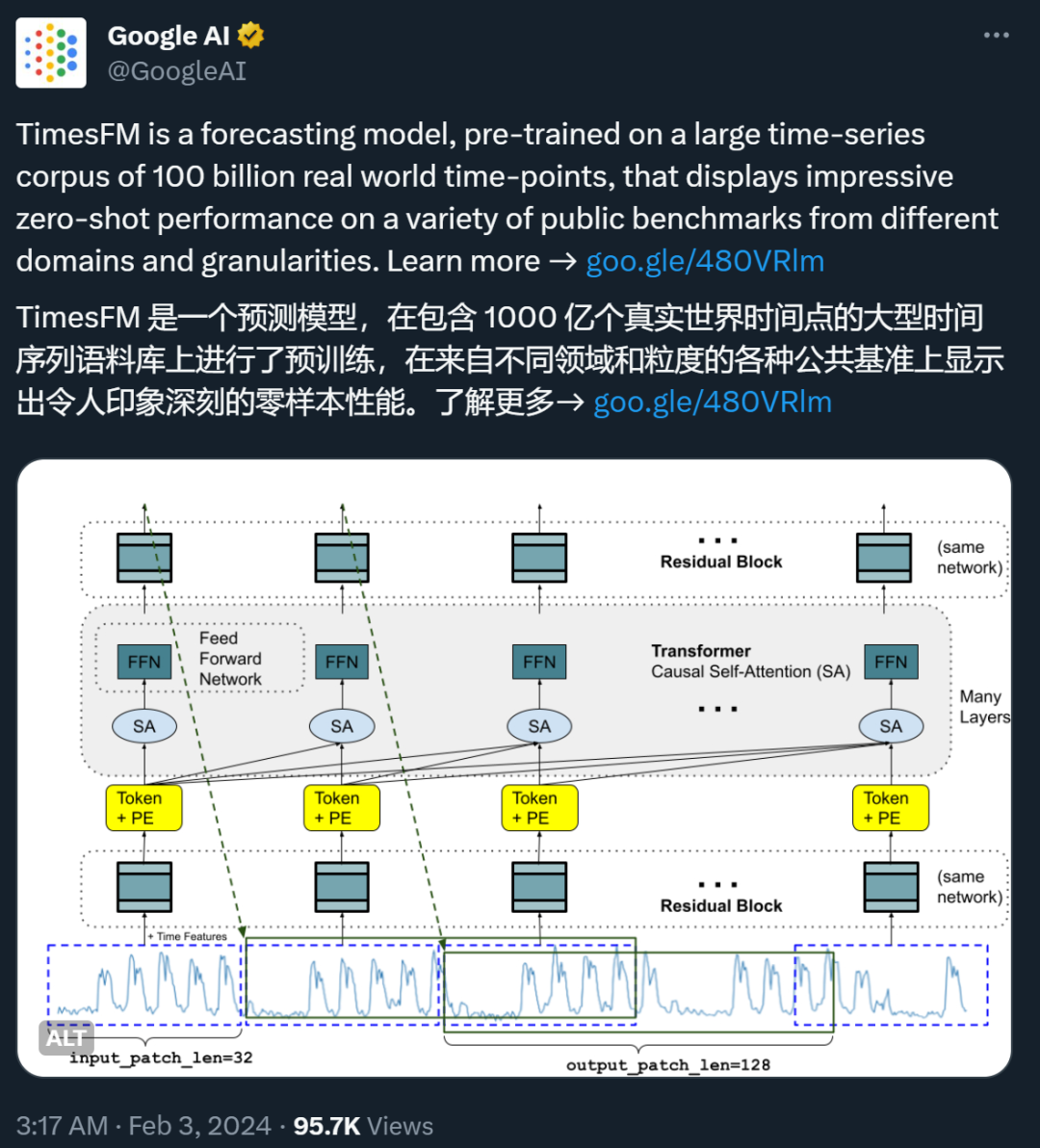
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。