
AMD新论文颠覆认知:FP4训练不稳定,原因不是随机性不足
AMD新论文颠覆认知:FP4训练不稳定,原因不是随机性不足众所周知,大模型训练成本极高。
来自主题: AI技术研报
6206 点击 2026-05-27 16:10
 搜索
搜索
众所周知,大模型训练成本极高。

为了降低大模型预训练成本,最近两年,出现了很多新的优化器,声称能相比较AdamW,将预训练加速1.4×到2×。但斯坦福的一项研究,指出不仅新优化器的加速低于宣称值,而且会随模型规模的增大而减弱,该研究证实了严格基准评测的必要性。
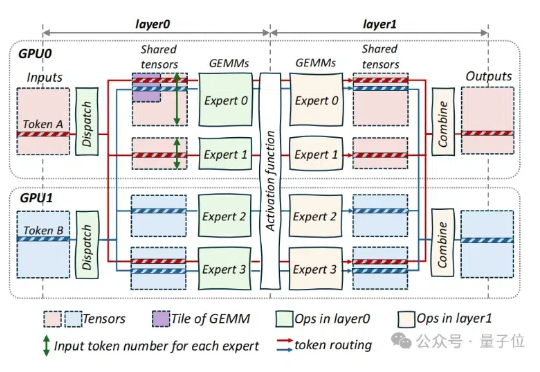
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。
卷赢大模型训练成本之后,DeepSeek正在重塑全球AI竞争格局。

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

Anthropic首席执行官表示,当前AI模型训练成本是10亿美元,未来三年,这个数字可能会上升到100亿美元甚至1000亿美元。要知道,GPT-4o这个曾经最大的模型也只用了1亿美元。千亿美刀,究竟花在了哪里?

AI发展驱动收入增长,但成本激增需大投资。

如何复盘大模型技术爆发的这一年?除了直观的感受,你还需要一份系统的总结