
Claude 5史诗级泄露,史上最强编程模型评测炸裂!核心秘密曝光
Claude 5史诗级泄露,史上最强编程模型评测炸裂!核心秘密曝光Anthropic的新模型要来了!代号Fennec的Claude Sonnet 5马上要发布,性能吊打市面上所有编程大模型,价格还砍掉50%,还能比肩一整个人类开发团队,可以说达到编程领域的巅峰。
来自主题: AI资讯
9448 点击 2026-02-04 17:27
 搜索
搜索
Anthropic的新模型要来了!代号Fennec的Claude Sonnet 5马上要发布,性能吊打市面上所有编程大模型,价格还砍掉50%,还能比肩一整个人类开发团队,可以说达到编程领域的巅峰。
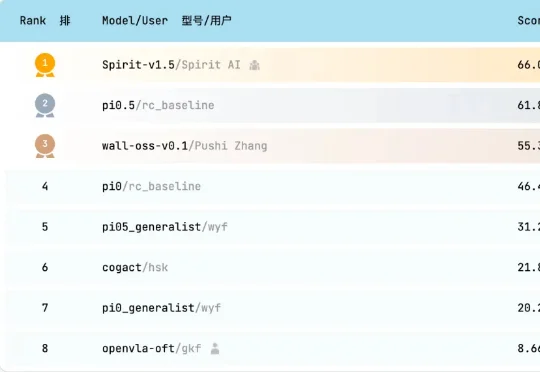
全球榜单中唯一成功率超过50%的模型。今日,千寻智能正式开源自研VLA基础模型Spirit v1.5,就在前一天,该模型在全球具身智能模型评测平台RoboChallenge上,综合评测斩获第一。

AI不仅会做PPT,写代码,它还能理解更深层次的问题。在美国的一项偏重于文化领域的新基准测试中,中国开源模型Qwen3夺冠,DeepSeek的R1跻身前六,力压多家全球顶级的明星模型。
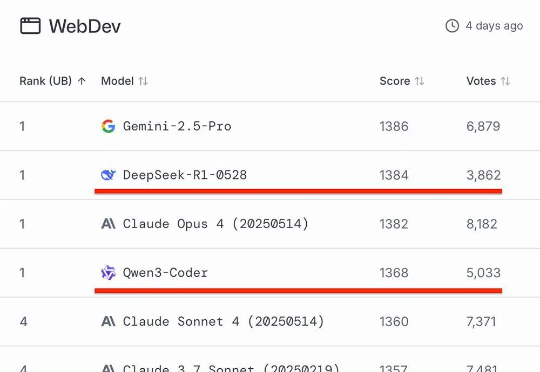
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

怎么快速判断一个生成模型好不好? 最直接的办法当然是 —— 去问一位做图像生成、视频生成、或者专门做评测的朋友。他们懂技术、有经验、眼光毒辣,能告诉你模型到底强在哪、弱在哪,适不适合你的需求。

今年2月DeepSeek爆火,震惊国内外。实际上,在此之前,中国信息通信研究院(下称:中国信通院)的大模型评测团队就观察到国内模型性能迅速提升的势头,他们当中就包括中国信通院人工智能研究所所长魏凯。
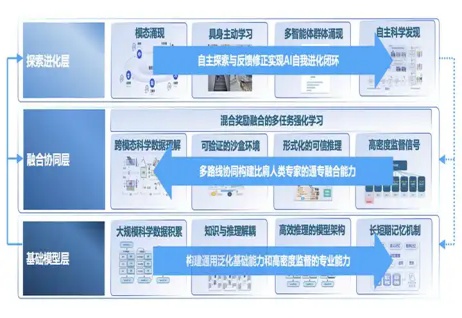
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
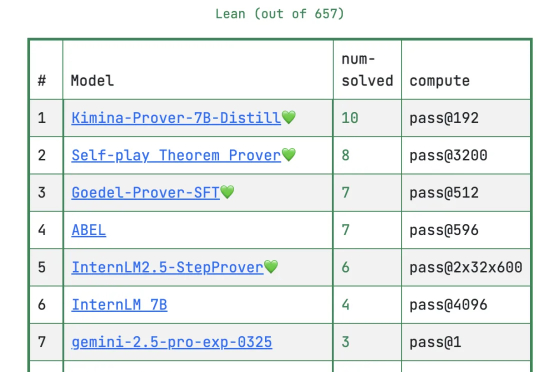
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。
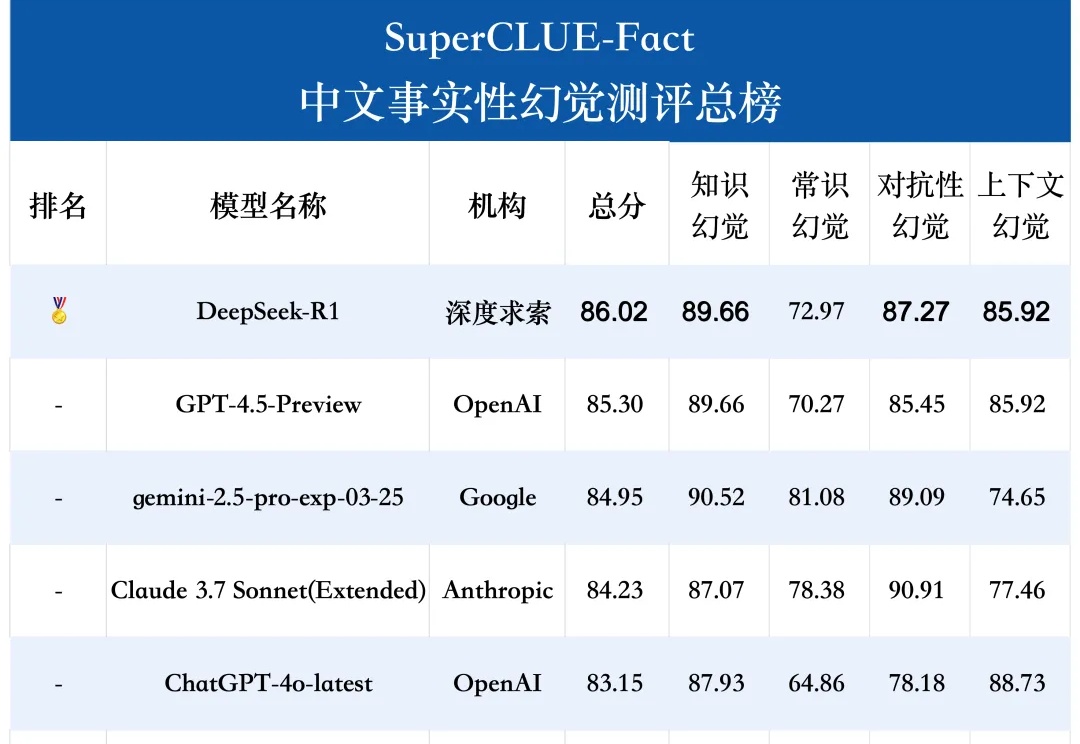
SuperCLUE-Fact是专门评估大语言模型在中文短问答中识别和应对事实性幻觉的测试基准。测评任务包括知识、常识、对抗性和上下文幻觉。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。