你正在做的大模型评测,可能有一半都是无用功 | 上海AI Lab&上交&浙大出品
你正在做的大模型评测,可能有一半都是无用功 | 上海AI Lab&上交&浙大出品评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!
来自主题: AI技术研报
10461 点击 2025-03-19 10:37
 搜索
搜索
评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!

近日,记者发现,国内权威医疗大模型评测平台MedBench在官网更新了榜单。多个医疗AI产品及研究团队入榜,其中蚂蚁AI健康管家团队研发的蚂蚁医疗大模型以评测榜单97.5、自测榜单98.2的高分再度夺得双料冠军。

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)

先说结论: 多数模型,是色盲

2024年快要结束了,世界大模型究竟孰强孰弱?刚刚,智源研究院发布了下半年大模型综合评测结果,涵盖了开源闭源100+模型,横跨文本、语音、图像和视频等多个领域。
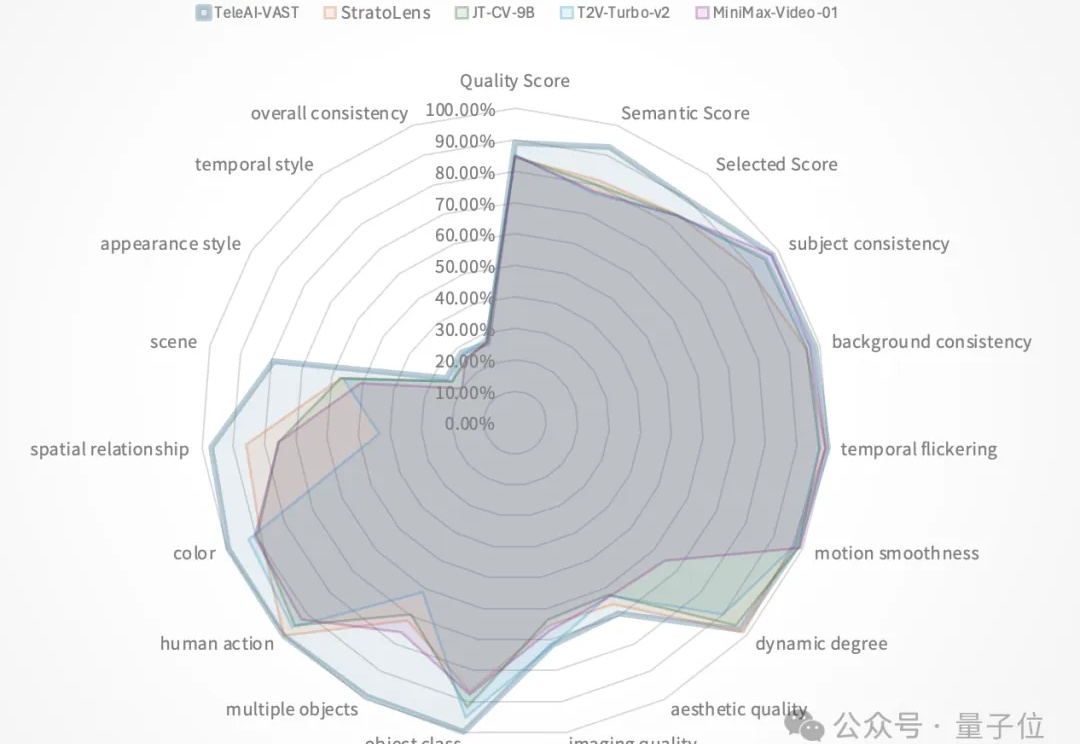
视频生成模型评测权威榜单VBench,突遭“屠榜”。

如果给LLM做MBTI,会得到什么结果?UC伯克利的最新研究就发现,不同模型真的有自己独特的性格

10月25日,汽车行业AI产品和业务解决方案提供商易慧智能发布了汽车行业首个大模型评测集。此次评测旨在全面评估市面上主流大模型在汽车行业中的实际应用效果,特别关注于汽车营销场景的应用评估。在此基础上,易慧智能重磅推出创新的模型路由技术方案——基于多模型的YiAgent群体智能技术框架。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
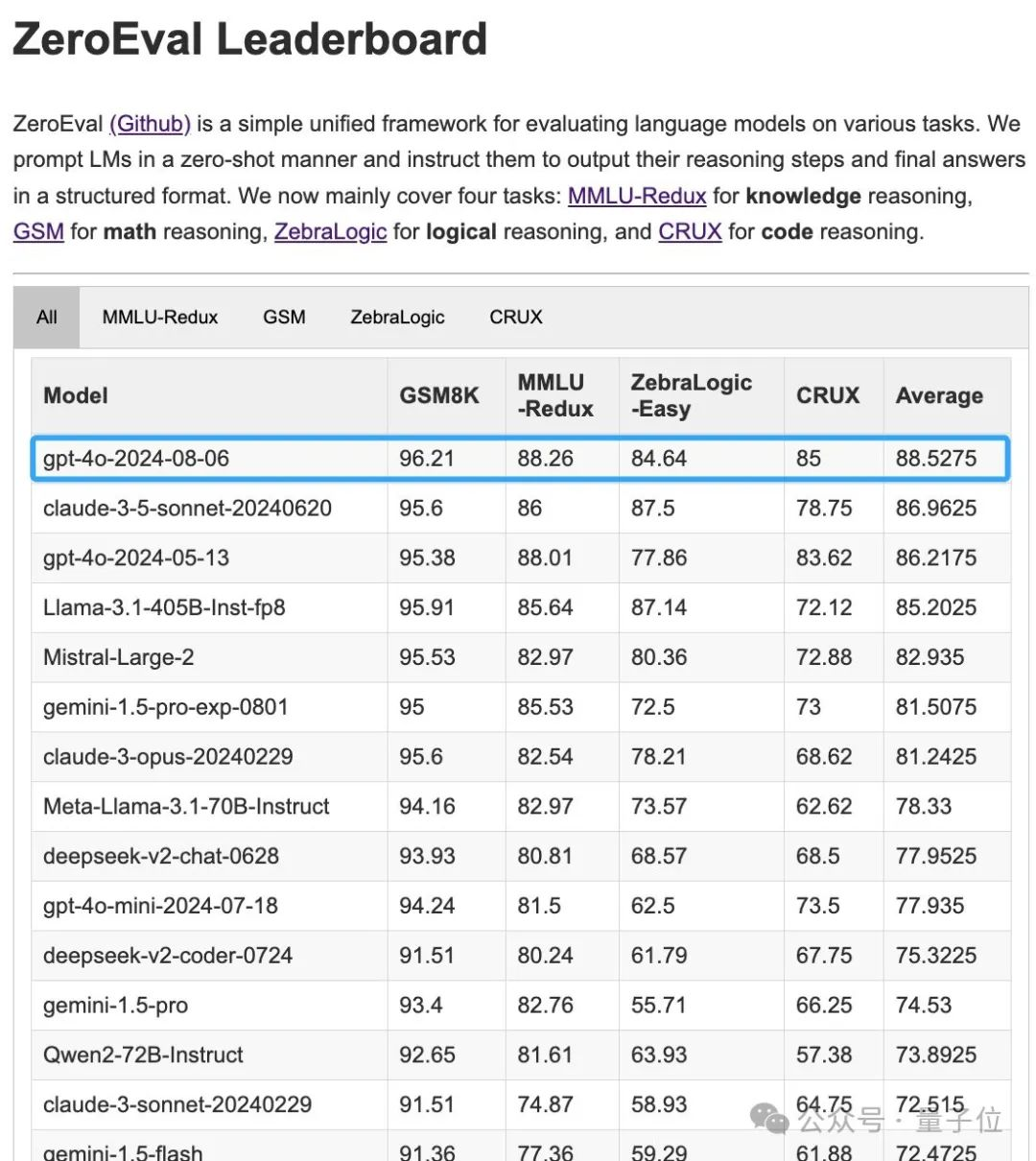
GPT-4o新版本突然上线,更强更便宜。