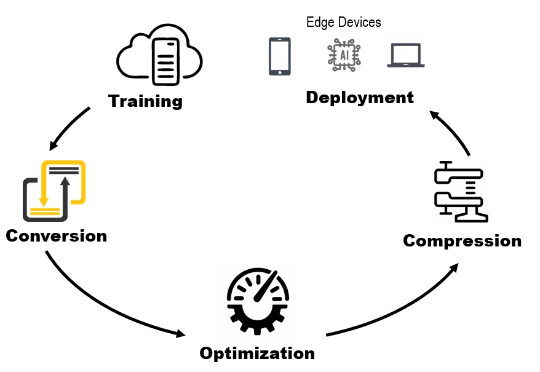
为什么 DeepSeek 大规模部署很便宜,本地很贵
为什么 DeepSeek 大规模部署很便宜,本地很贵为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?
来自主题: AI技术研报
9997 点击 2025-07-08 11:14
 搜索
搜索
为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?

AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。
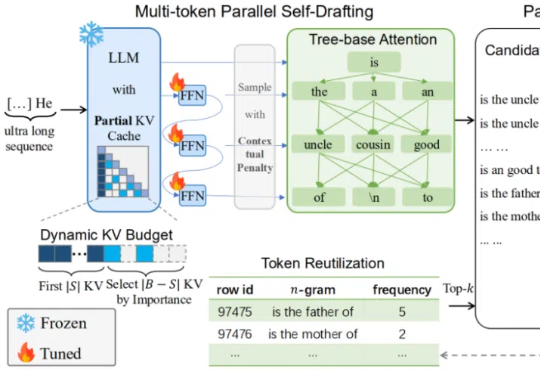
在当前大模型推理愈发复杂的时代,如何快速、高效地产生超长文本,成为了模型部署与优化中的一大核心挑战。
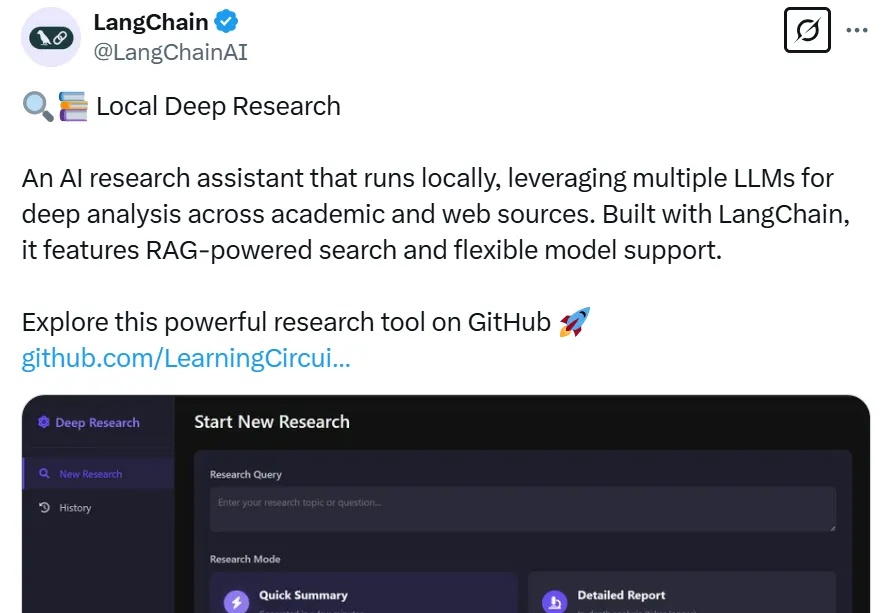
今年年初,OpenAI 上线 Deep Research,开启了智能体又一新阶段,其能根据用户需求自主进行网络信息检索、整合多源信息、深度分析数据,并最终为用户提供全面深入的解答。

号称地表最强的M3 Ultra,本地跑满血版DeepSeek R1,效果到底如何?

从今天这个视角来看,DeepSeek 等国内外大模型能力是越来越强大了,大家都说 2025 年 AI 应用还会持续爆发。但对于企业来说,有了大模型,那场景都有啥,应用又长啥样?
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。
国家网络安全通报中心昨天扔了个"炸弹":大模型工具Ollama有安全漏洞! 相信不少人用ollama来跑DeepSeek、Llama等模型,确实很方便。可通报里说,它默认开放的11434端口跟没锁的大门似的,谁都能进。今天就和你就说一下 这到底是怎么回事?顺便手把手教你几招,保住你的算力和隐私。
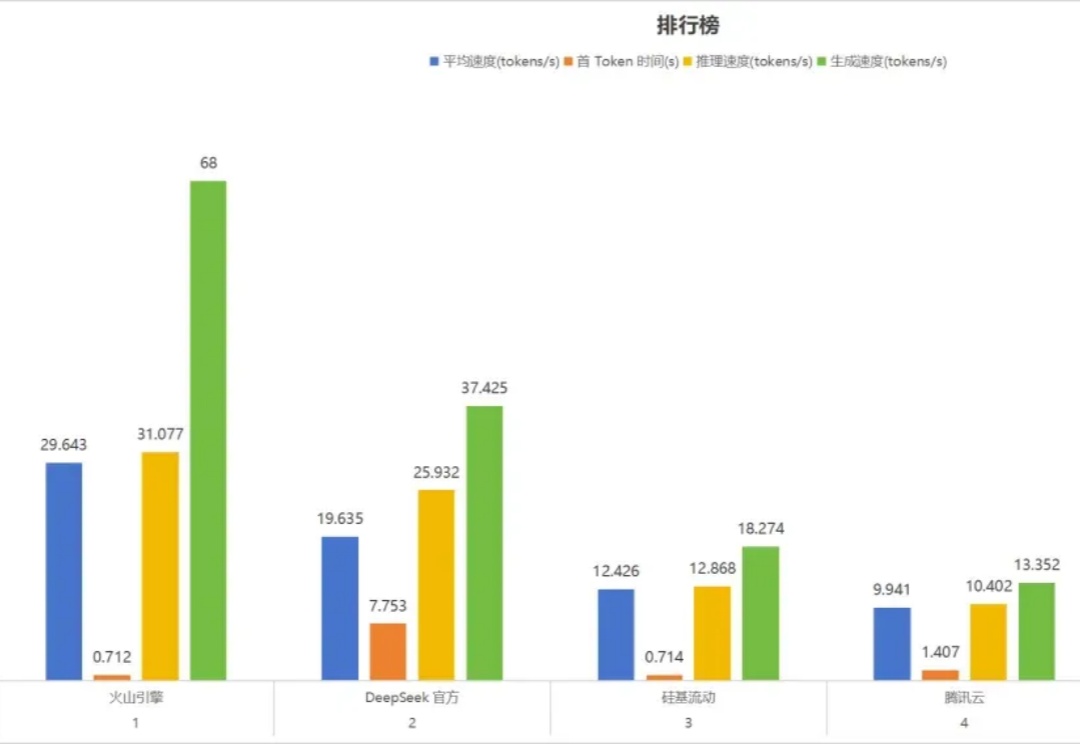
部署 DeepSeek 系列模型,尤其是推理模型 DeepSeek-R1,已经成为一股不可忽视的潮流。
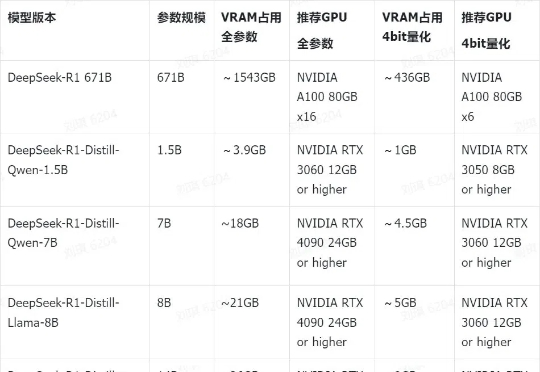
DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。