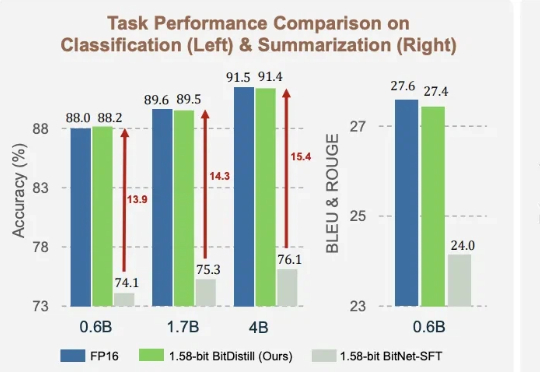
1.58bit不输FP16!微软推出全新模型蒸馏框架,作者全是华人
1.58bit不输FP16!微软推出全新模型蒸馏框架,作者全是华人1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
来自主题: AI技术研报
7235 点击 2025-10-20 14:35
 搜索
搜索
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。
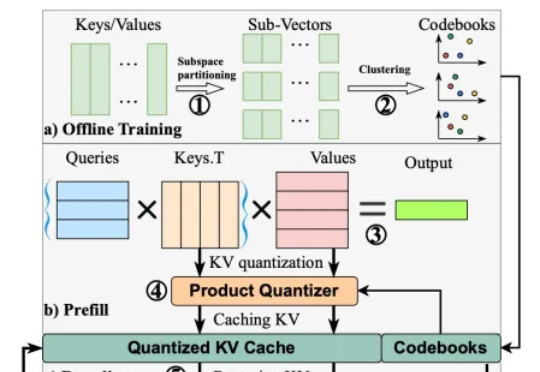
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。
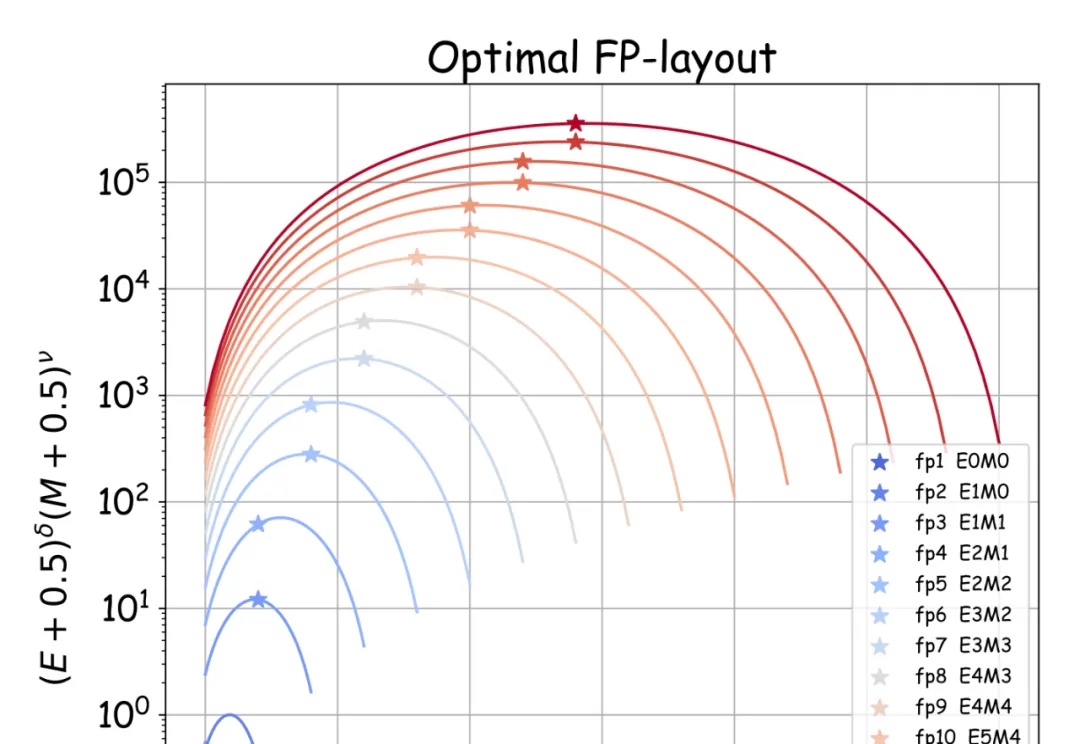
大模型低精度训练和推理是大模型领域中的重要研究方向,旨在通过降低模型精度来减少计算和存储成本,同时保持模型的性能。因为在大模型研发成本降低上的巨大价值而受到行业广泛关注 。
将扩散模型量化到1比特极限,又有新SOTA了! 来自北航、ETH等机构的研究人员提出了一种名为BiDM的新方法,首次将扩散模型(DMs)的权重和激活完全二值化。

最近几天,AI 社区都在讨论同一篇论文。 UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。

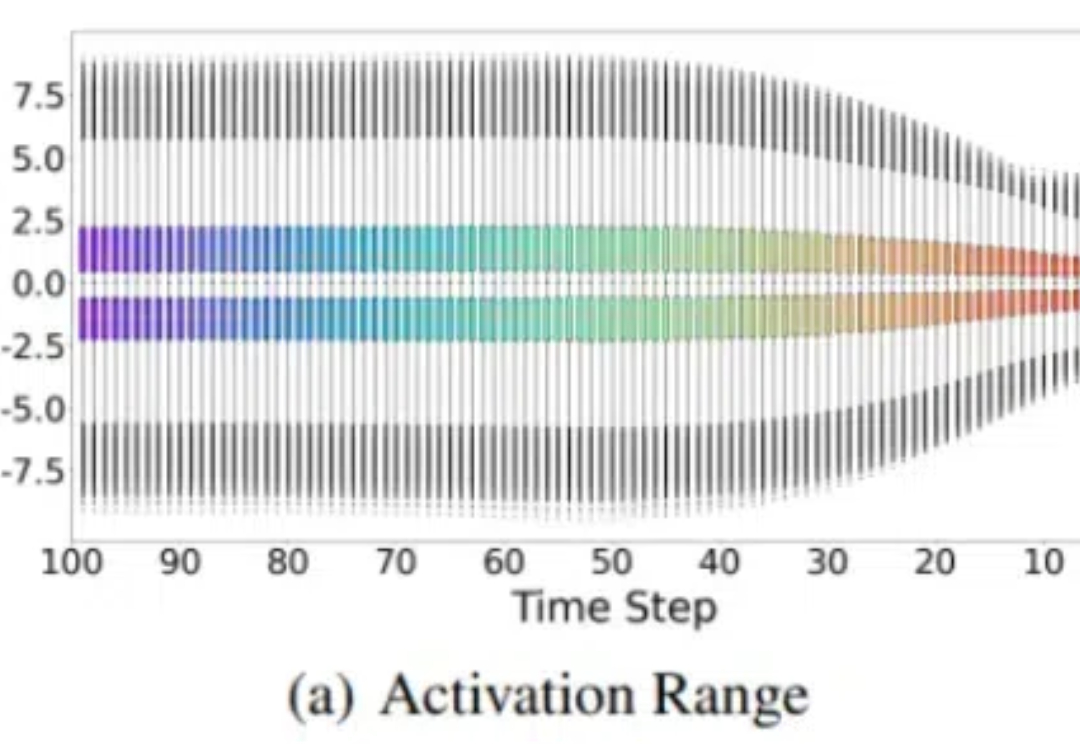
消除激活值(outliers),大语言模型低比特量化有新招了—— 自动化所、清华、港城大团队最近有一篇论文入选了NeurIPS 2024(Oral Presentation),他们针对LLM权重激活量化提出了两种正交变换,有效降低了outliers现象,达到了4-bit的新SOTA。

随着深度学习大语言模型的越来越火爆,大语言模型越做越大,使得其推理成本也水涨船高。模型量化,成为一个热门的研究课题。

模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。