大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力
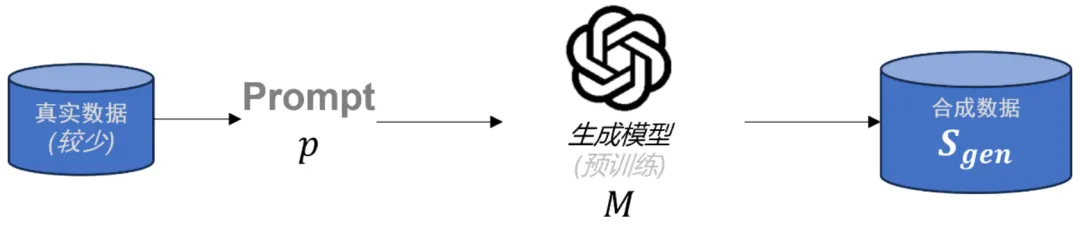
大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。
来自主题: AI技术研报
8263 点击 2024-10-15 18:38
 搜索
搜索
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

在用模拟环境训练机器人时,所用的数据与真实世界存在着巨大的差异。为此,李飞飞团队提出「数字表亲」,这种虚拟资产既具备数字孪生的优势,还能补足泛化能力的不足,并大大降低了成本。

最近,ByteDance Research 的第二代机器人大模型 —— GR-2,终于放出了官宣视频和技术报告。GR-2 以其卓越的泛化能力和多任务通用性,预示着机器人大模型技术将爆发出巨大潜力和无限可能。

大语言模型市场的整合与差异:大语言模型市场存在整合的趋势。一方面,人工智能发展的基础产业是资本密集型的,市场整合对于大语言模型市场的资本支撑是必要的。另一方面,为尽可能提高算法的泛化能力,单个大语言模型也需要集成多种创新功能。市场集中度的提高使得企业需要进一步考虑大语言模型的差异化。

全自动驾驶系统的纯视觉方案如特斯拉 “Tesla Vision”,仅依赖于摄像头收集的图像数据,旨在实现高效且成本效益高的自动驾驶技术。

在机器人研究领域,抓取任务始终是机器人操作中的一个关键问题。这项任务的核心目标是控制机械手移动到合适位置,并完成对物体的抓取。近年来,基于学习的方法在提高对不同物体的抓取的泛化能力上取得了显著进展,但针对机械手本身,尤其是复杂的灵巧手(多指机械手)之间的泛化能力仍然缺乏深入研究。由于灵巧手在不同形态和几何结构上存在显著差异,抓取策略的跨手转移一直存在挑战。

Skild AI 是一家位于匹兹堡的初创公司,由两位前 CMU 教授创立,旨在打造具身智能的通用大脑。Skild 宣称其模型展示了无与伦比的泛化和涌现能力,并且有多于竞争对手 1000 倍的训练数据。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。

近日,香港大学发布最新研究成果:智能交通大模型OpenCity。该模型根据参数大小分为OpenCity-mini、OpenCity-base和OpenCity-Pro三个模型版本,显著提升了时空模型的零样本预测能力,增强了模型的泛化能力。