开启 AI 自主进化时代,普林斯顿Alita颠覆传统通用智能体,GAIA榜单引来终章
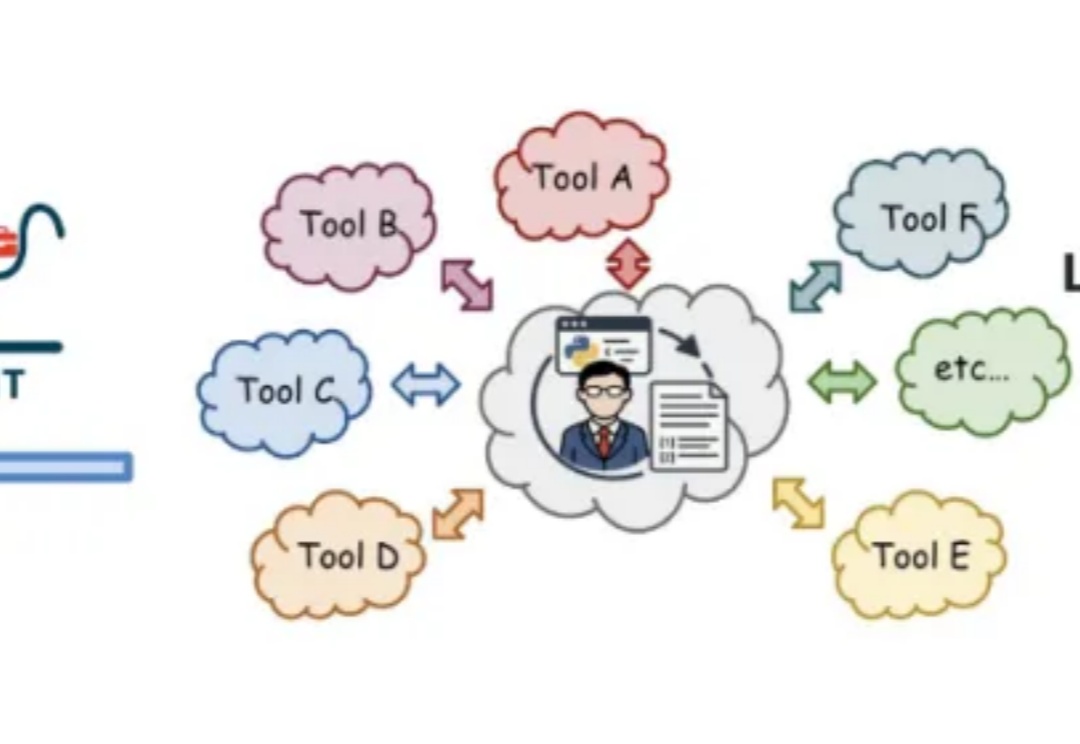
开启 AI 自主进化时代,普林斯顿Alita颠覆传统通用智能体,GAIA榜单引来终章智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。
来自主题: AI技术研报
8424 点击 2025-06-05 11:50
 搜索
搜索
智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。
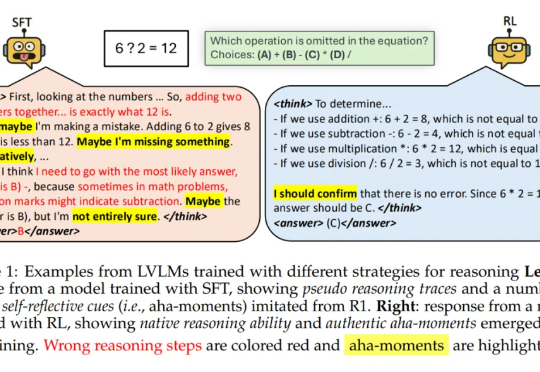
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」

「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!

近日,腾讯 PCG 社交线的研究团队针对这一问题,采用强化学习(RL)训练方法,通过分组相对策略优化(Group Relative Policy Optimization, GRPO)算法,结合基于奖励的课程采样策略(Reward-based Curriculum Sampling, RCS),将其创新性地应用在意图识别任务上,

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。
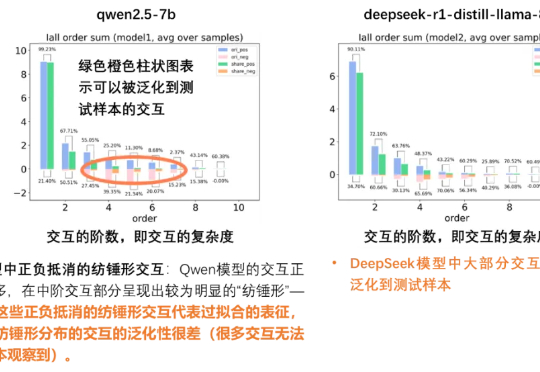
当以端到端黑盒训练为代表的深度学习深陷低效 Scaling Law 而无法自拔时,我们是否可以回到起点重看模型表征本身——究竟什么才是一个人工智能模型的「表征质量」或者「泛化性」?我们真的只有通过海量的测试数据才能抓住泛化性的本质吗?或者说,能否在数学上找到一个定理,直接从表征逻辑复杂度本身就给出一个对模型泛化性的先验的判断呢?

具身智能最大的挑战在于泛化能力,即在陌生环境中正确完成任务。最近,Physical Intelligence推出全新的π0.5 VLA模型,通过异构任务协同训练实现了泛化,各种家务都能拿捏。
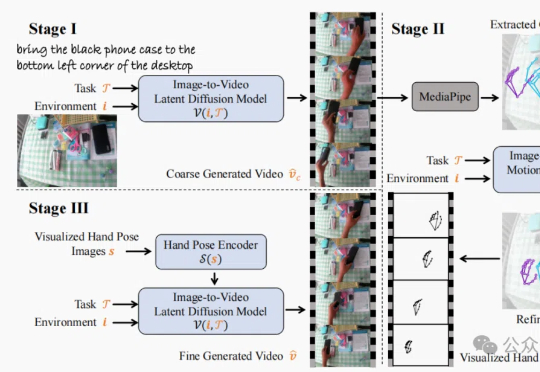
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
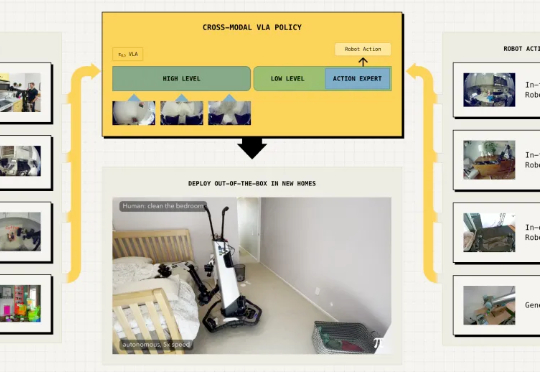
今天,美国具身智能公司 Physical Intelligence 推出了一个基于 π0 的视觉-语言-动作(VLA)模型 π0.5,其利用异构任务的协同训练来实现广泛的泛化,可以在全新的家中执行各种任务。