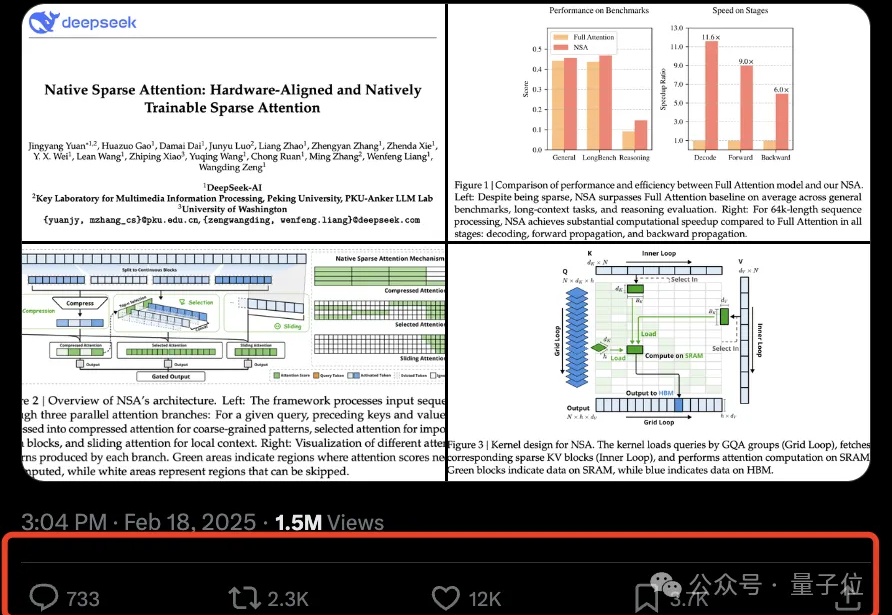
DeepSeek新注意力机制引热议!梁文锋亲自提交预印本,目标明确降低计算成本
DeepSeek新注意力机制引热议!梁文锋亲自提交预印本,目标明确降低计算成本DeepSeek新注意力机制论文一出,再次引爆讨论热度。
来自主题: AI技术研报
7651 点击 2025-02-19 14:38
 搜索
搜索
DeepSeek新注意力机制论文一出,再次引爆讨论热度。
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。

几个小时前,著名 AI 研究者、OpenAI 创始成员之一 Andrej Karpathy 发布了一篇备受关注的长推文,其中分享了注意力机制背后一些或许少有人知的故事。

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

RAG,AI,模型训练,人工智能

随着诺贝尔物理学奖颁给了「机器学习之父」Geoffrey Hinton,另一个借鉴物理学概念的模型架构也横空出世——微软清华团队的最新架构Differential Transformer,从注意力模块入手,实现了Transformer的核心能力提升。

注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。

视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。