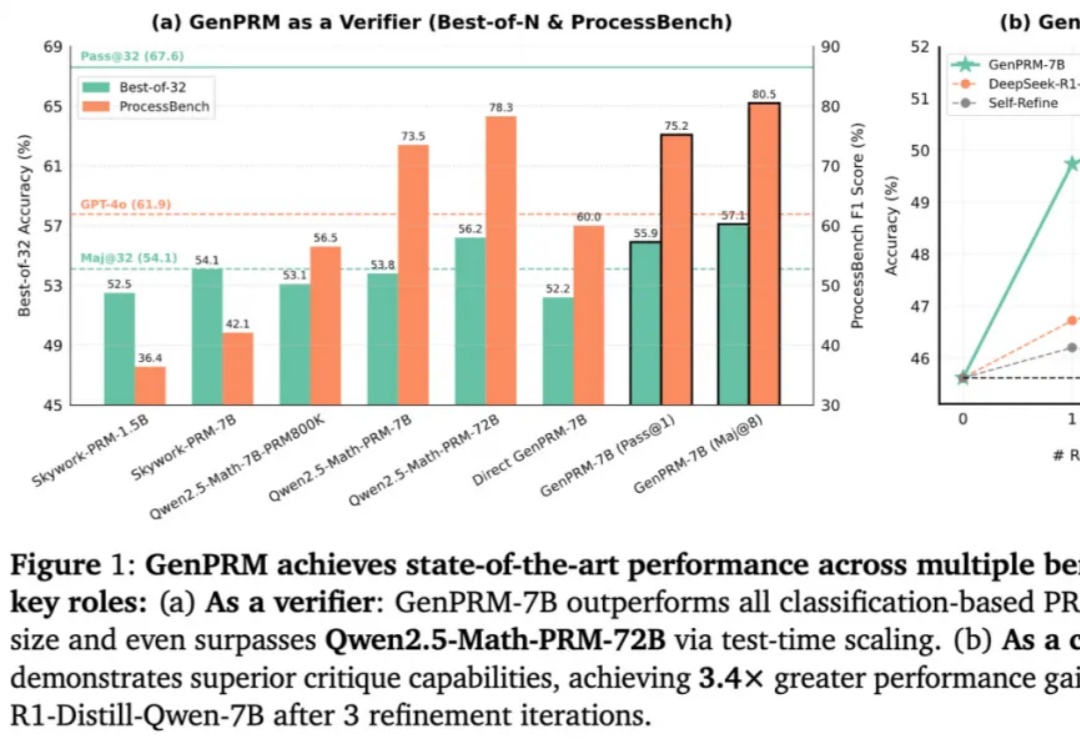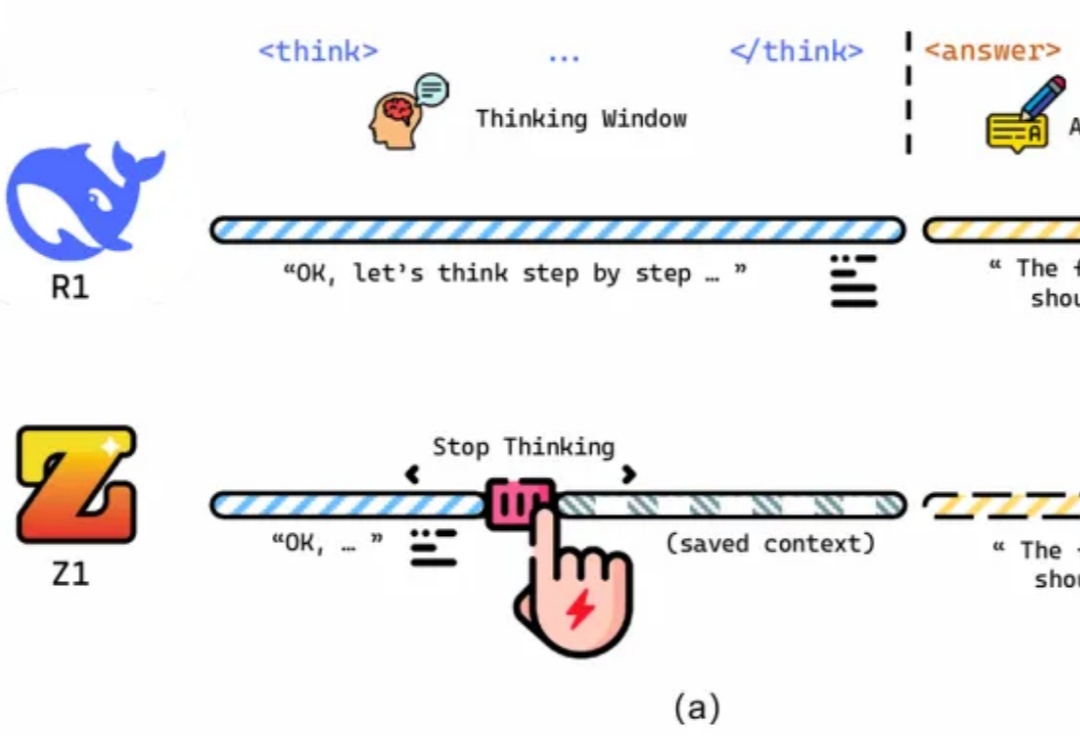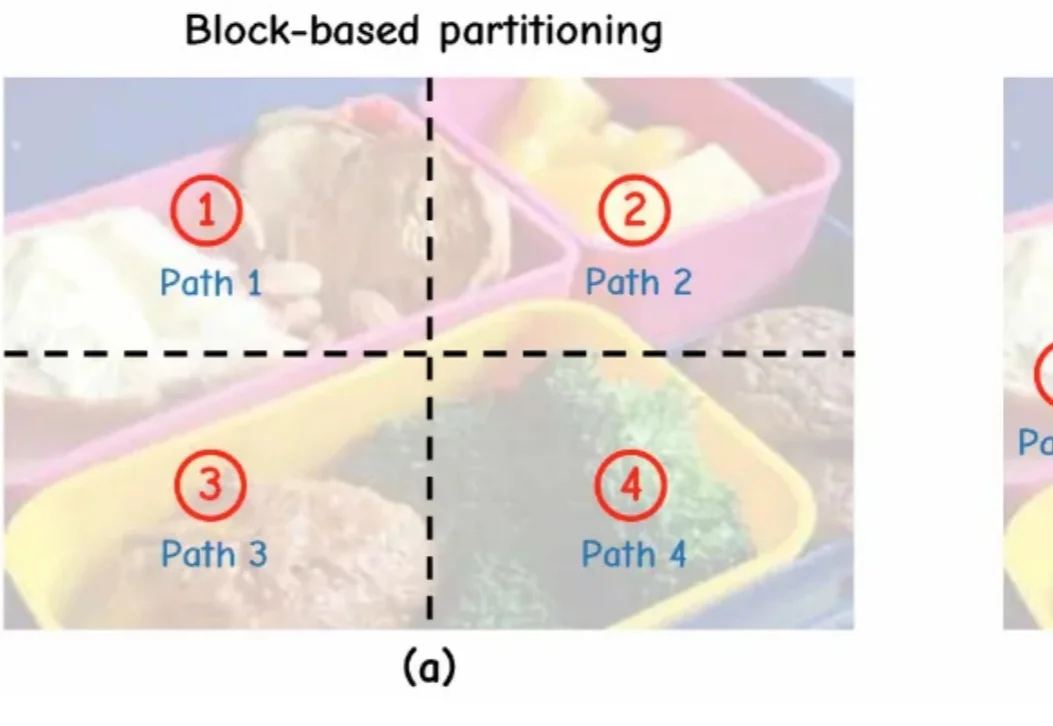
ICML 2026|首个视觉语言模型并行思考框架,一文解析内在机制
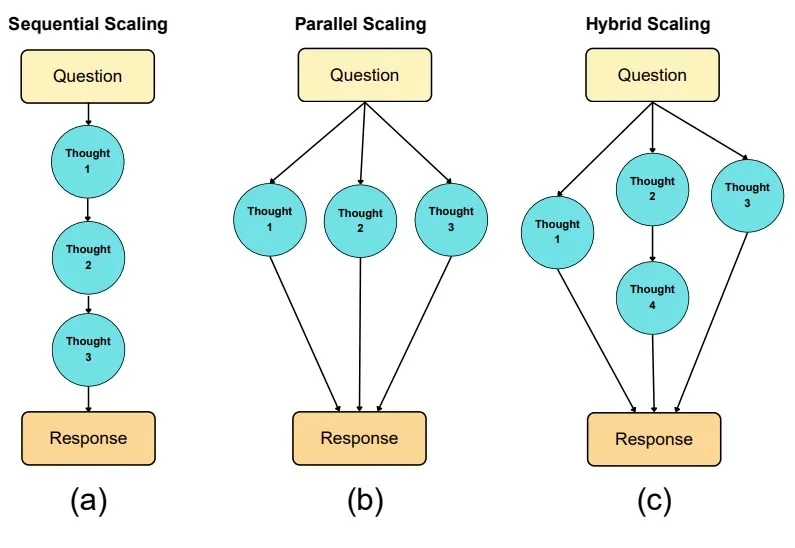
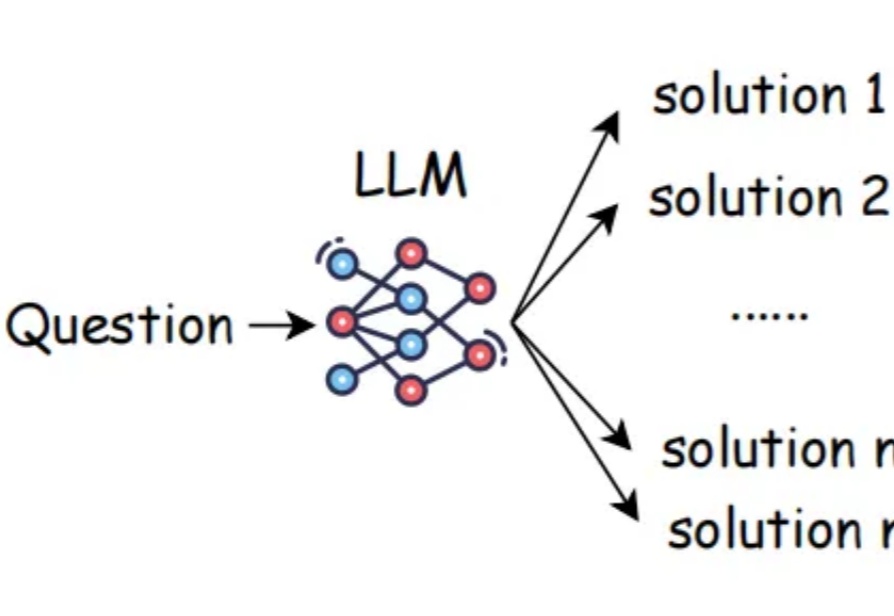
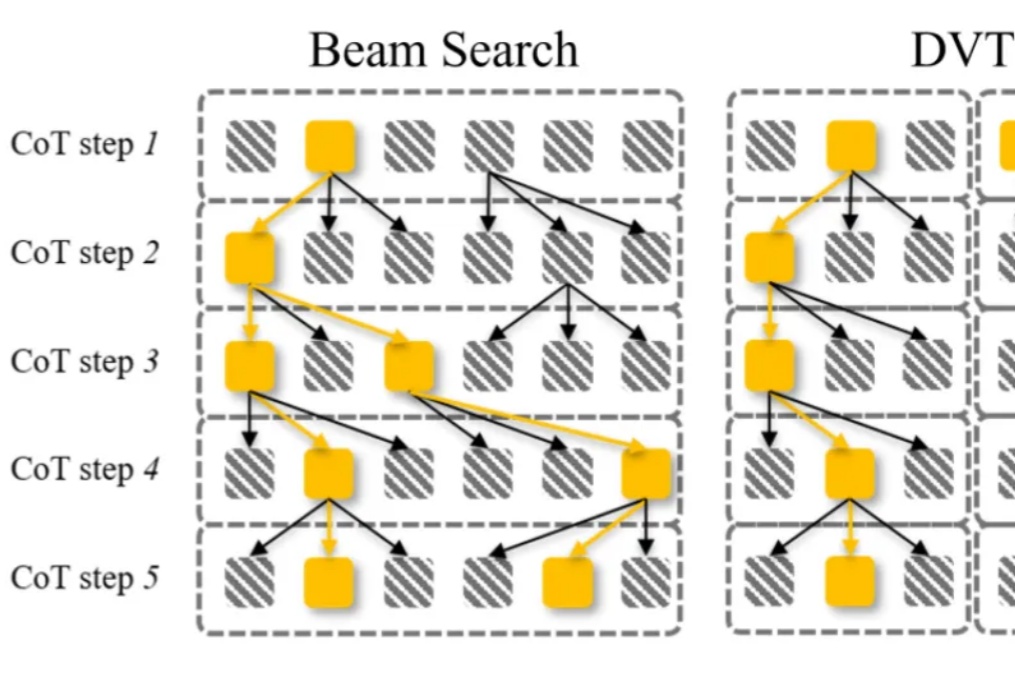
ICML 2026|首个视觉语言模型并行思考框架,一文解析内在机制当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。
来自主题: AI技术研报
8590 点击 2026-05-25 09:49