
AI作曲缺数据,浙大GTSinger数据集上线:适配所有歌声任务、带有真实乐谱
AI作曲缺数据,浙大GTSinger数据集上线:适配所有歌声任务、带有真实乐谱传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。
来自主题: AI技术研报
8263 点击 2024-10-14 10:38
 搜索
搜索
传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

Hinton在人工智能领域的贡献极其卓越,被誉为 “神经网络之父”、“人工智能教父”。他的主要贡献包括:反向传播算法的改进与推广、深度学习模型的创新(深度置信网络、卷积神经网络等多个深度学习网络结构)。Hinton还为AI行业培养了包括OpenAI前首席科学家伊尔亚・苏茨克维(Ilya Sutskever)在内的诸多人才。

2024 年 7 月,清华大学计算机系 PACMAN 实验室发布开源深度学习编译器 MagPy,可一键编译用户使用 Python 编写的深度学习程序,实现模型的自动加速。

Sutton 等研究人员近期在《Nature》上发表的研究《Loss of Plasticity in Deep Continual Learning》揭示了一个重要发现:在持续学习环境中,标准深度学习方法的表现竟不及浅层网络。研究指出,这一现象的主要原因是 "可塑性损失"(Plasticity Loss):深度神经网络在面对非平稳的训练目标持续更新时,会逐渐丧失从新数据中学习的能力。

昨天,OpenAI CEO 山姆阿尔特曼在新开的博客主页发了一篇长文《智能时代》。全文大致内容是:随着深度学习的发展,超级人工智能将在几千天后到来,到时候 AI 会改变人们的方方面面,人类也将进入智能时代。

今天,Sam Altman很罕见的在他的个人网站上发布了一篇推文:The Intelligence Age(智能时代)。
就在刚刚,奥特曼罕见发表长文,预言ASI将在「几千天内」降临!他肯定,深度学习已经奏效了,它能够真正学习任何数据的分布模式。如今人类奇点已经近在咫尺,我们眼看着就要迈进ASI的大门!

Transformer 是现代深度学习的基石。传统上,Transformer 依赖多层感知器 (MLP) 层来混合通道之间的信息。
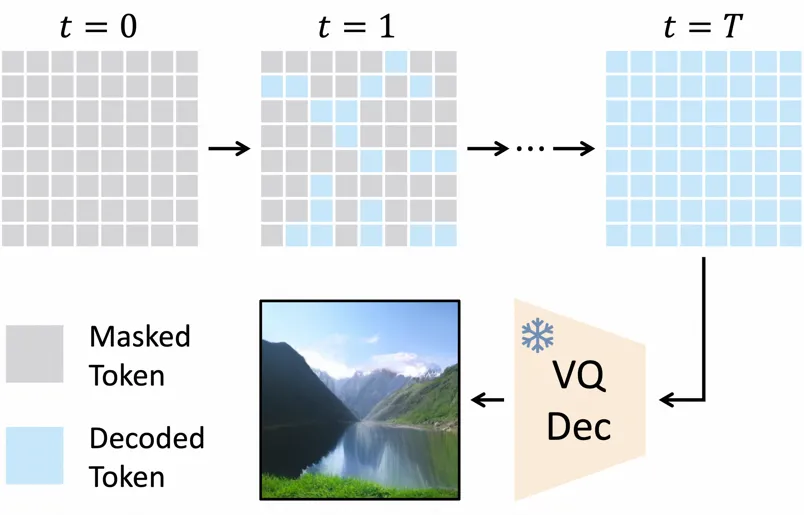
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
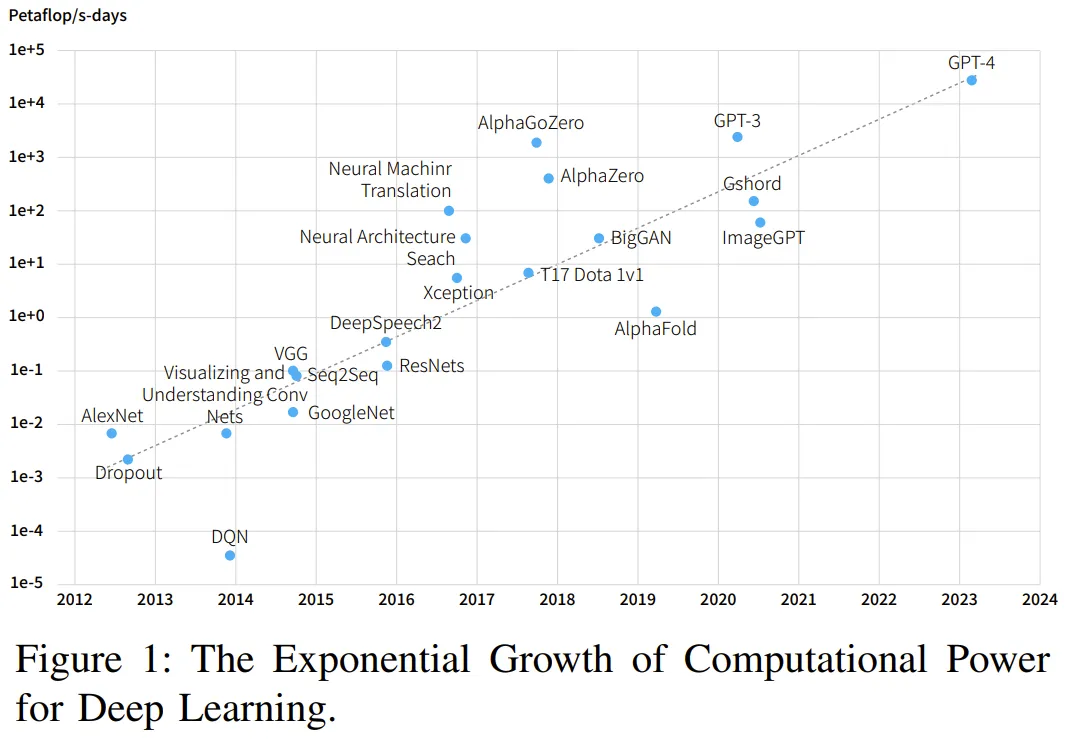
硬件发展速度跟不上 AI 需求,就需要精妙的架构和算法。