经验记忆黑科技:LightSearcher让AI工具调用减39.6%、推理快48.6%
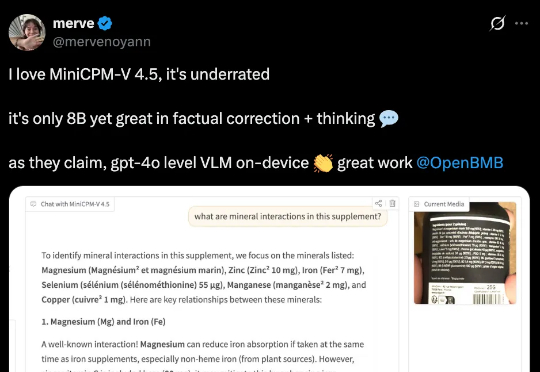
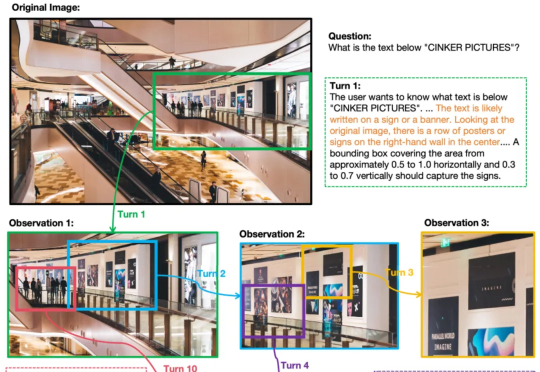
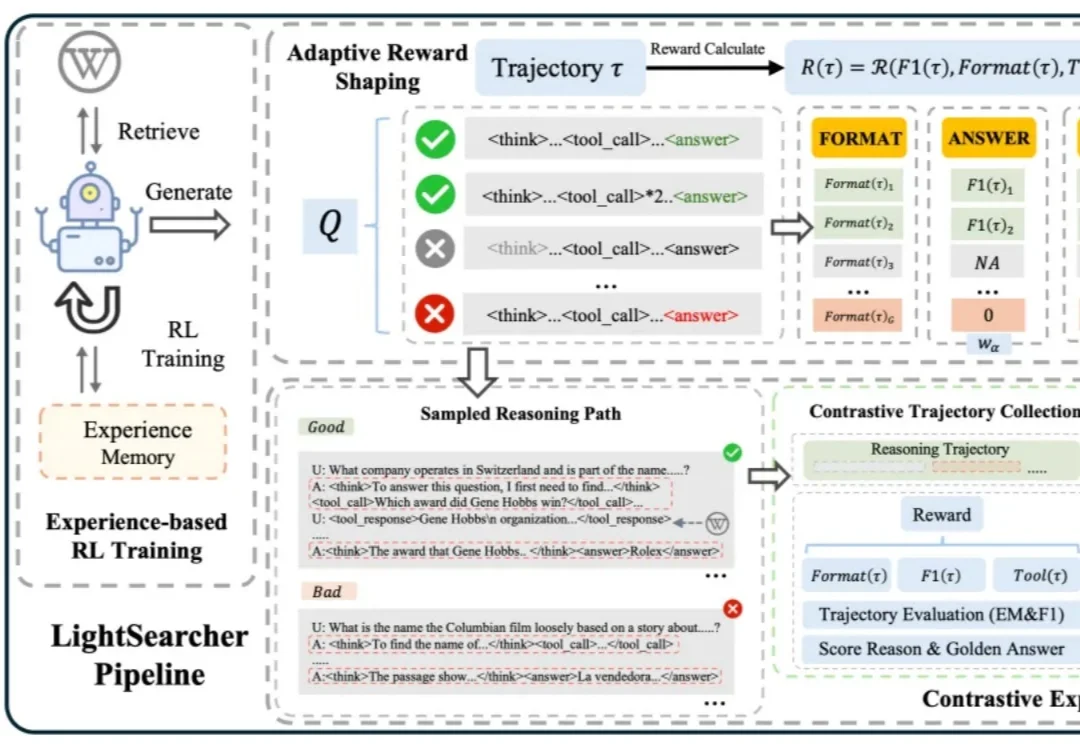
经验记忆黑科技:LightSearcher让AI工具调用减39.6%、推理快48.6%如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。
来自主题: AI技术研报
7524 点击 2025-12-18 09:46