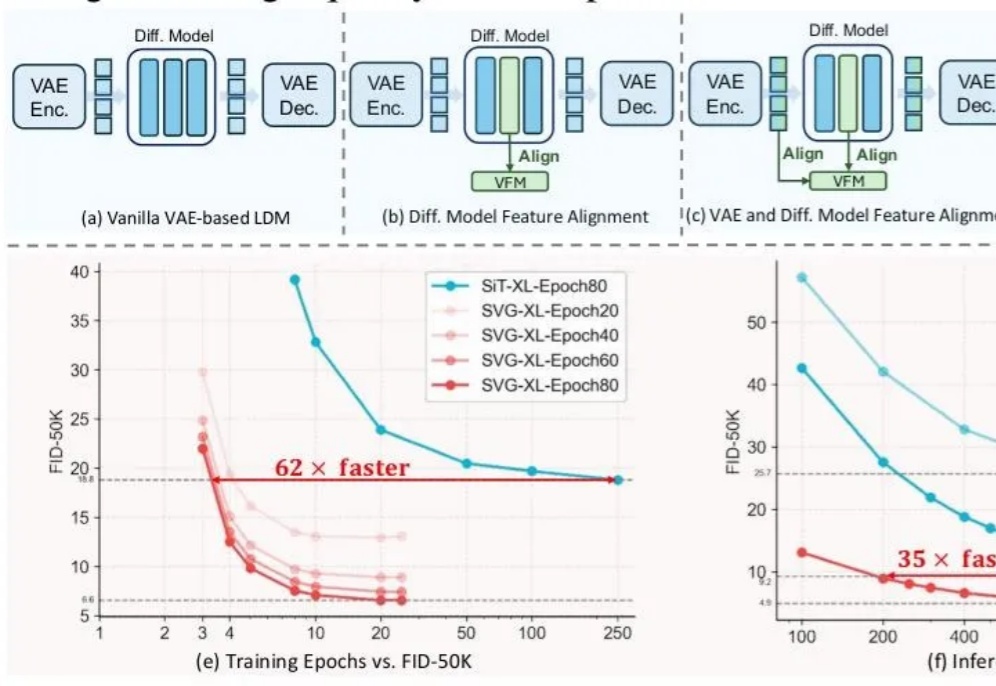
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
来自主题: AI技术研报
7598 点击 2025-10-29 16:28
 搜索
搜索
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。

亚马逊AI博士奖学金,正式公布了!两年共计6800万美金,计划将为全球「九所」顶尖大学,100多名博士生提供研究资金的支持。这九所顶尖大学,个个都是AI界的「扛把子」,主要包括:

长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练
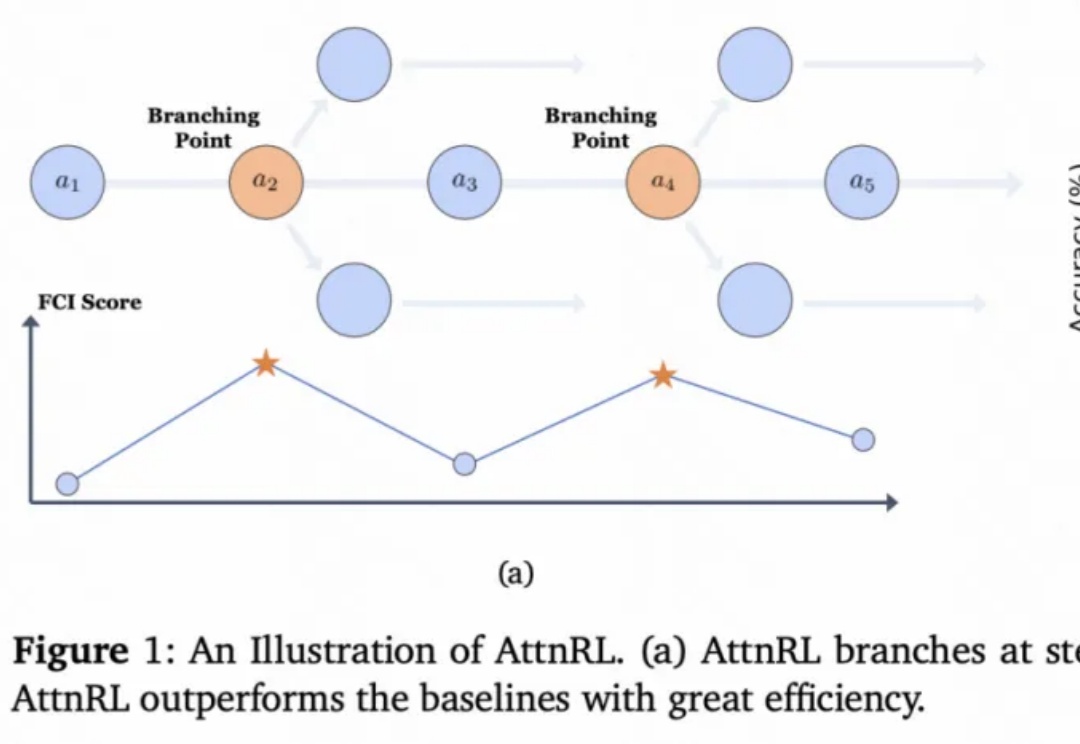
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。

生成式 AI 正在重写 3D 内容的生产流程:从“DCC 工具 + 外包”的线性供给,演进到“资产规模化生成 + 管线可用”的指数供给模式。过去五年,技术范式经历了从实时体积渲染,NeRF,到Score Distillation,3D扩散的快速迭代;需求侧则由游戏与影视,向3D 打印、电商样机、数字人、教育培训、以及AR/VR等长尾场景外溢。

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。
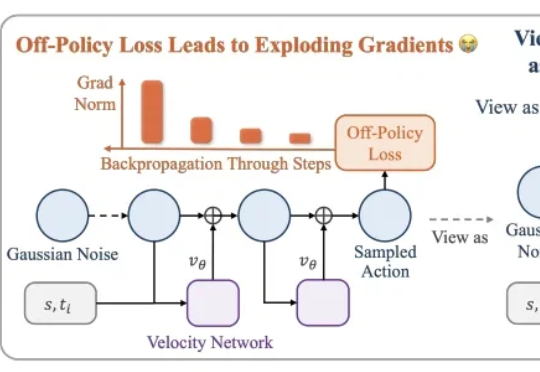
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。

当地时间 10 月 15 日,美国麻省理工学院的垂直氮化镓芯片衍生公司 Vertical Semiconductor 获得 1,100 万美元的种子轮融资,清华大学苏世民学院校友、前英国驻华大使馆气候变化与环境事务副主任 Cynthia Liao 是该公司的联合创始人兼 CEO。
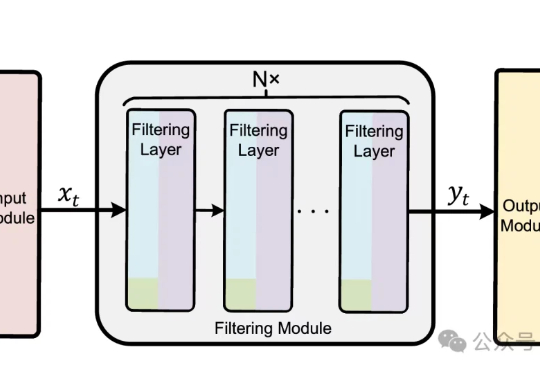
在机器人与自动驾驶领域,由强化学习训练的控制策略普遍存在控制动作不平滑的问题。这种高频的动作震荡不仅会加剧硬件磨损、导致系统过热,更会在真实世界的复杂扰动下引发系统失稳,是阻碍强化学习走向现实应用的关键挑战。
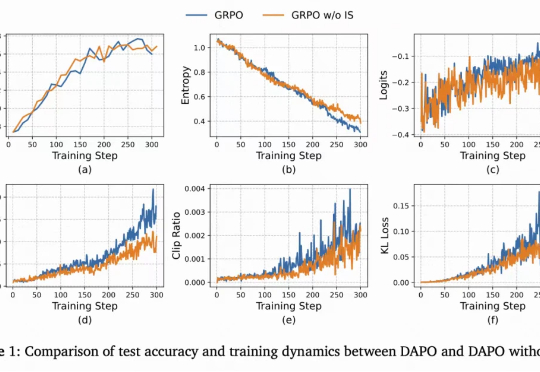
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。