
清华AI数学家来了!从想法一路推到定理,参与完成84页量子算法论文
清华AI数学家来了!从想法一路推到定理,参与完成84页量子算法论文研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。
来自主题: AI技术研报
8695 点击 2026-07-10 10:41
 搜索
搜索
研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。
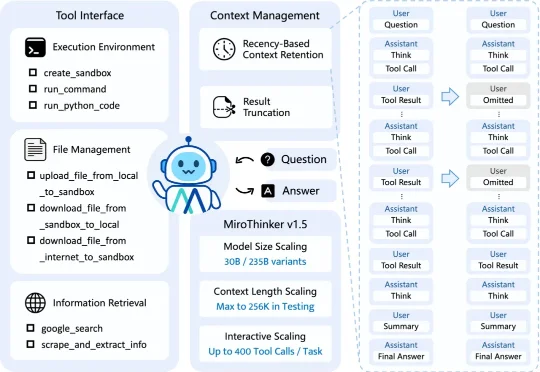
2026年1月5日,由陈天桥和清华AI学者代季峰联合发起的MiroMind团队,正式发布了自研旗舰搜索智能体模型MiroThinker 1.5。这个消息本身并不算特别,毕竟最近几个月几乎每周都有新模型发布。但当我深入了解后发现,这个模型背后代表的思路,可能会彻底改变我们对AI能力边界的认知。
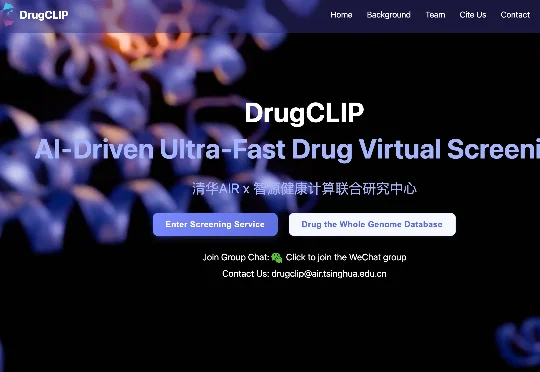
清华大学智能产业研究院(AIR)联合清华大学生命学院、清华大学化学系在Science上发表论文:《深度对比学习实现基因组级别药物虚拟筛选》。团队研发了一个AI驱动的超高通量药物虚拟筛选平台DrugCLIP。

成立两年半,再添近5亿元A+轮融资—— 截至目前,无问芯穹已累计吸金近15亿,成为AI基础设施领域最受资本追捧的“黑马”企业之一。
当AI不再只是解题机器,而能与人类并肩完成严谨的科研证明,这意味着什么?

医学研究迎来“零人工”时代了?!清华大学自动化系索津莉课题组,发布首个专为医疗信息学设计的全自主AI研究框架——OpenLens AI。首次实现从文献挖掘→实验设计→数据分析→代码生成→可投稿论文的全链条自动化闭环。

一个超越DeepSeek GRPO的关键RL算法出现了!这个算法名为DAPO,字节、清华AIR联合实验室SIA Lab出品,现已开源。禹棋赢,01年生,本科毕业于哈工大,直博进入清华AIR,目前博士三年级在读。去年年中,他以研究实习生的身份加入字节首次推出的「Top Seed人才计划」。

DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。