
1.5B参数撬动“吉卜力级”全能体验,国产开源之光多模态统一模型,来了
1.5B参数撬动“吉卜力级”全能体验,国产开源之光多模态统一模型,来了听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。
来自主题: AI资讯
10355 点击 2025-07-30 15:24
 搜索
搜索
听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。

AMD携手Stability AI宣布推出世界首款适用于Stable Diffusion 3.0 Medium的B16 NPU模型。该模型可直接运行于AMD XDNA 2 NPU之上,能够显著提升图像生成质量。新模型作为Amuse 3.1平台的组件之一亮相,于今天一起发布。
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

《涌现NewThings》是我们关注新兴AI应用的一档新栏目,如果你也是文生图/视频、情感陪伴、Coding、智能硬件等等AI应用创业者

这篇文章,我会从几个真实的案例出发,深度拆解一下星流这款产品,以及聊聊:为什么我认为「可控」才是真正的生产力?星流到底如何做到「可控」?以及,「可控性」为什么会是下一阶段 AIGC 的竞争关键?
![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)
前段时间,沉寂了很久的Flux官方团队Black Forest Labs发布了新模型:FLUX.1 Kontext,这是一套支持生成与编辑图像的流匹配(flow matching)模型。FLUX.1 Kontext不仅支持文生图,还实现了上下文图像生成功能,可以同时使用文本和图像作为提示词,并能无缝提取修改视觉元素,生成全新且协调一致的画面。

谷歌把最新的文生图模型 Imagen 4,以及它的 Pro Max 版 Imagen 4 Ultra,放到了 AI Studio 和 API 里。
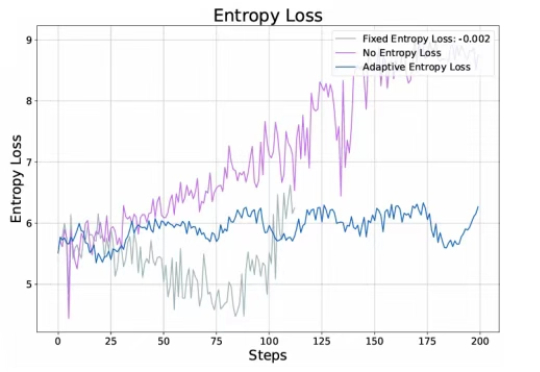
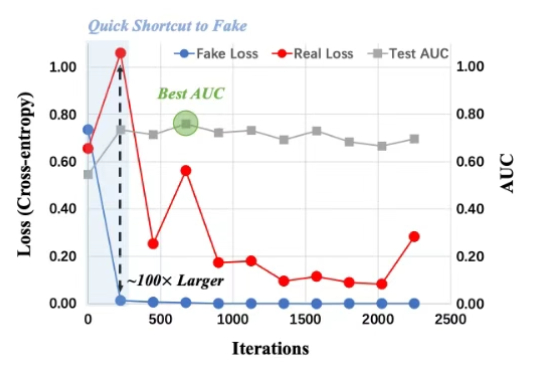
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

即梦AI的图片3.0生图功能更新之后基本是国内图像模型的天花板了,尤其是在日常的设计任务上,基本上人人都能做海报。

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?