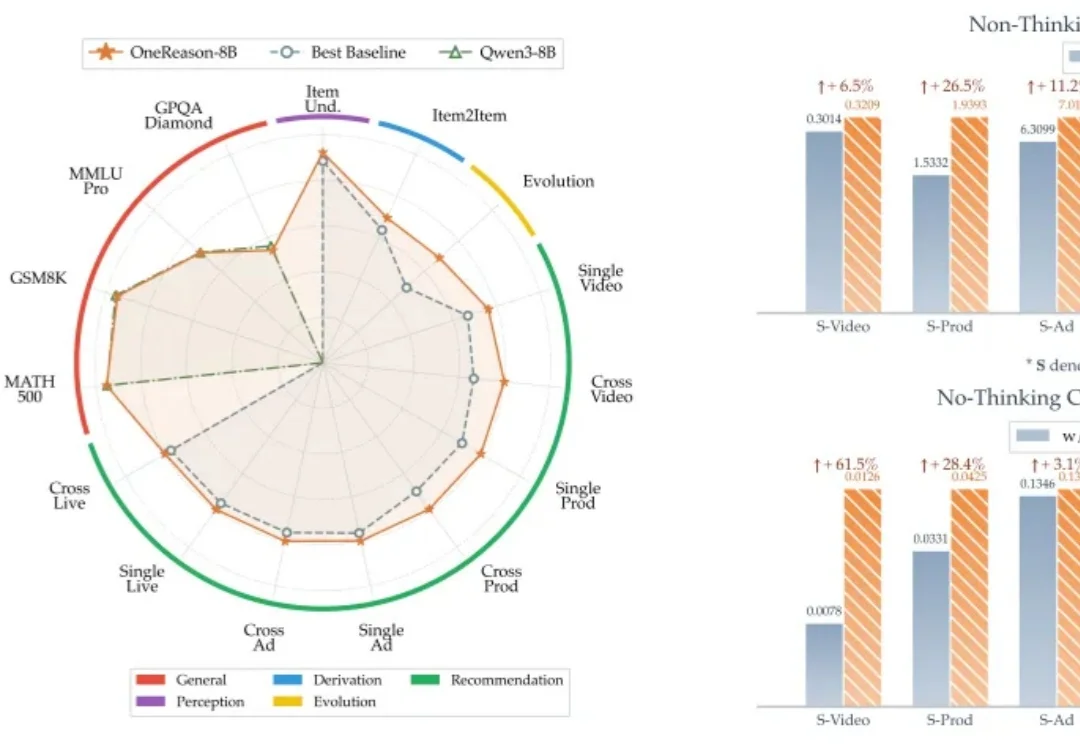
OneReason:当推荐系统学会思考
OneReason:当推荐系统学会思考推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。
来自主题: AI技术研报
6742 点击 2026-06-10 14:43
 搜索
搜索
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,

华为天才少年被具身智能企业哄抢。AI 科技评论最新获悉,前华为天才少年李一同近期已加入具身智能明星公司吉翼智能,任吉翼大模型研发中心总工程师,将主导公司在大模型与系统测试等核心板块的攻坚工作。履历方面,李一同为上海交大ACM班毕业,墨尔本大学博士,曾是华为天才少年,华为终端云语言大模型技术负责人。华为期间,李一同主要负责基于生成式大模型和人机对话方向的研究。

2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。
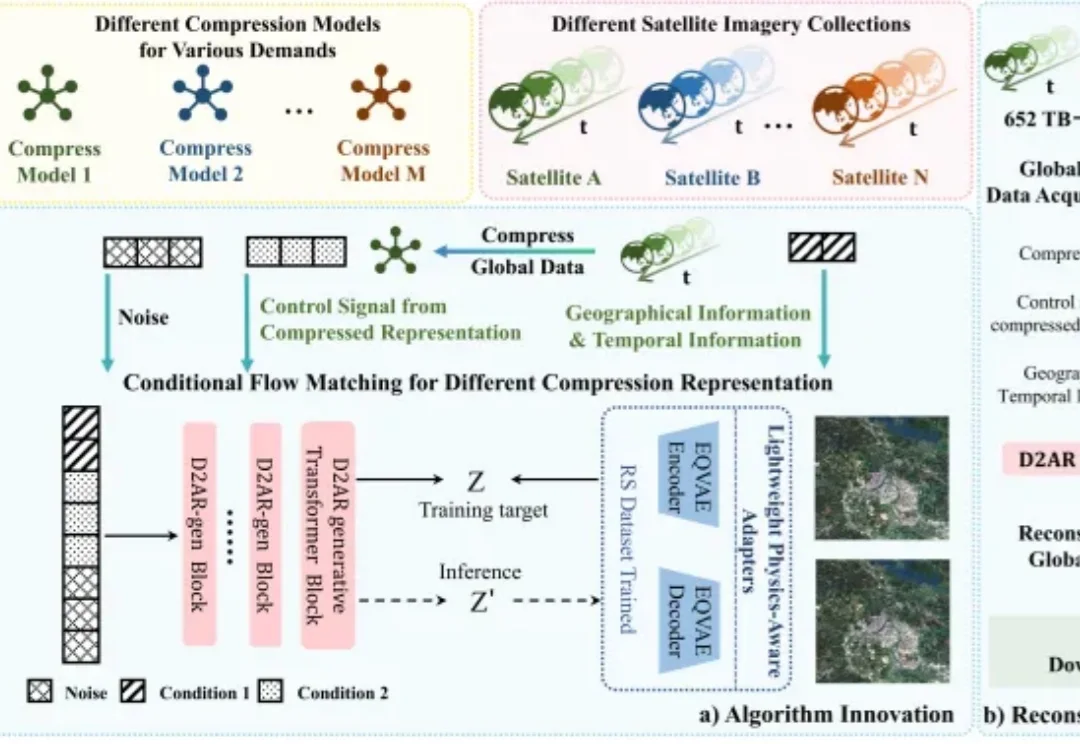
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

如今想写出一篇结构严密、用词专业的文章已经不算难事,只需要敲几个 prompt 生成式 AI 就能瞬间给你一篇成千上万字的文章。布鲁金斯学会去年的一项调查显示,拥有学士学位的成年人中有 35% 的人在工作中使用 AI 来撰写或编辑文档。
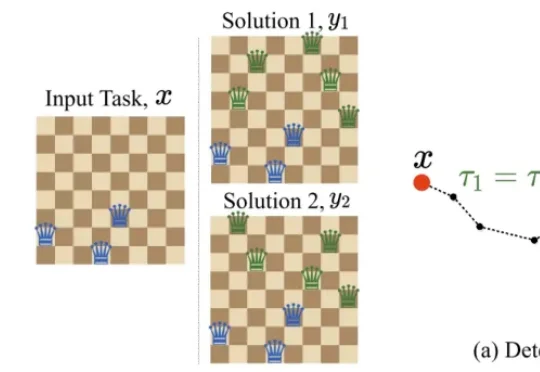
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。

人类历史上第一批和生成式AI同时长大的学生,正在踏入毕业季。这届毕业生可能会发现:不管在大学里学的是知识性课程,还是实用性技能,都难逃AI冲击,想要脱颖而出必须成为那个“更善于使用AI的人”。
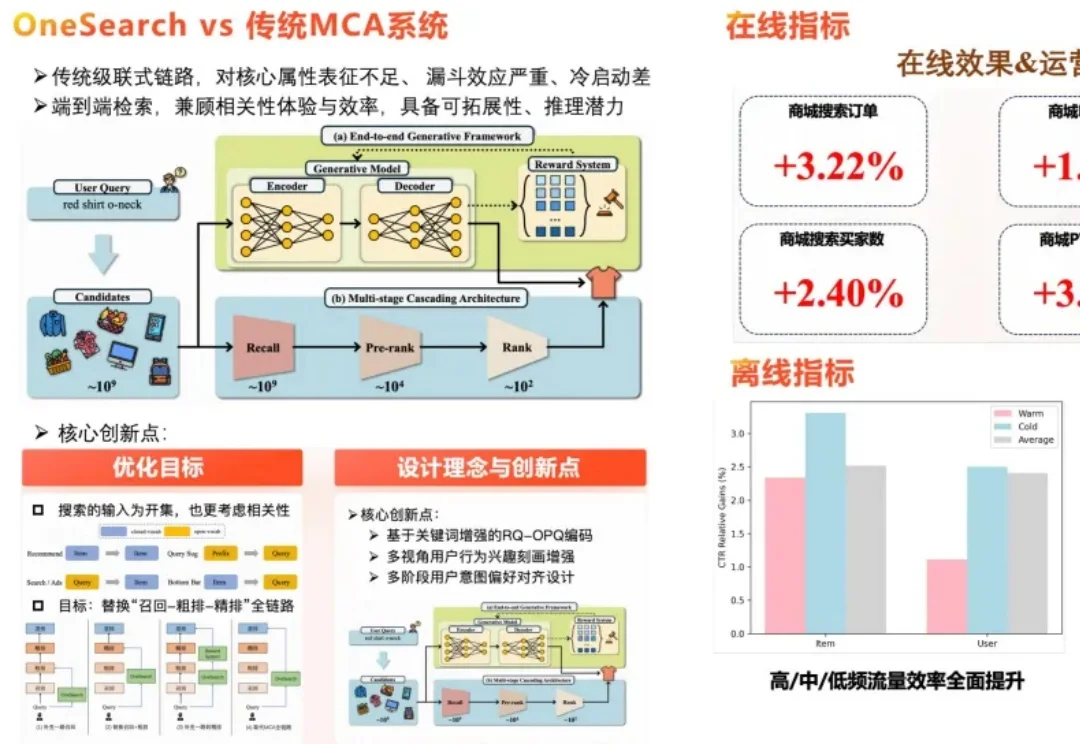
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。

随着AI大模型与生成式搜索全面普及,营销行业正迎来从传统搜索优化向AI原生优化的关键转型。GEO是适配AI问答、智能推荐的新一代营销体系,正在重新定义品牌与用户的信息连接方式。