所有AI创作工具,都该学学 MVLAND 这个功能
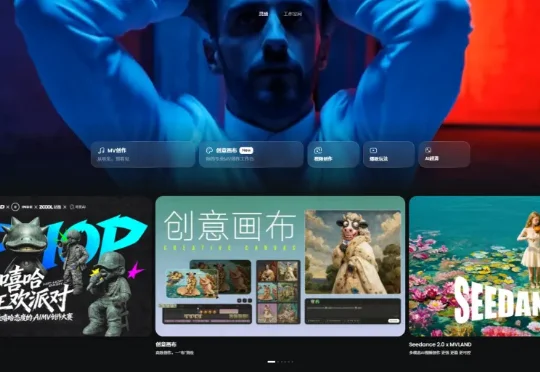
所有AI创作工具,都该学学 MVLAND 这个功能最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。
来自主题: AI资讯
10783 点击 2026-07-05 10:16
 搜索
搜索
最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。
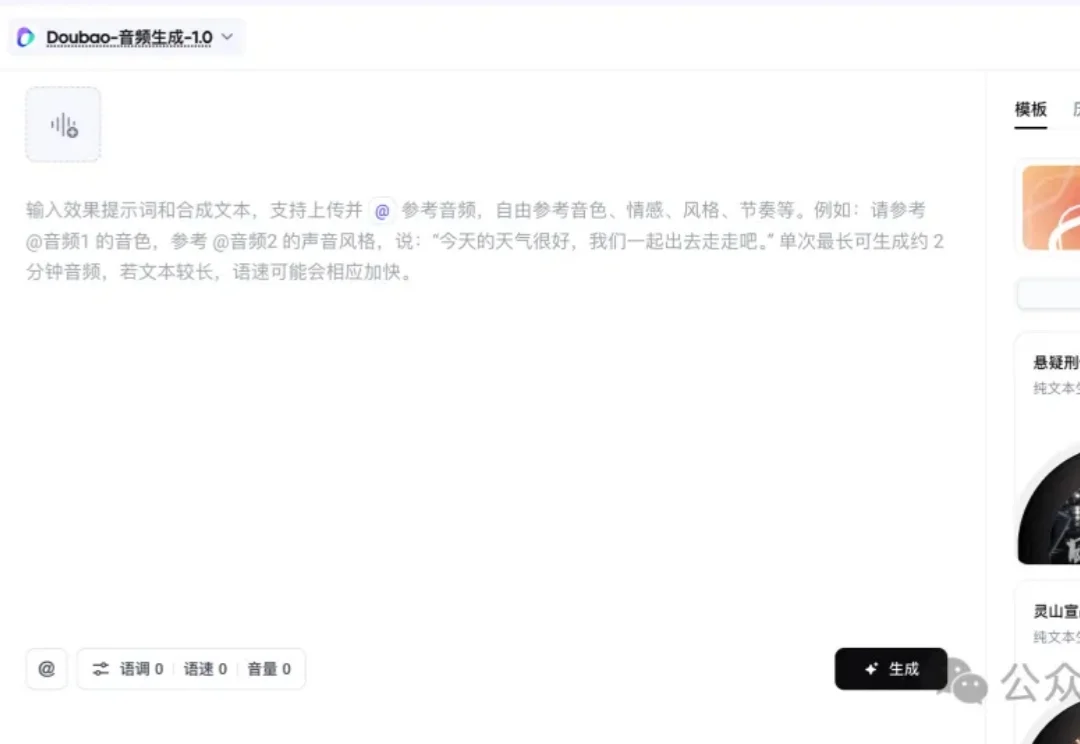
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

新模型上线首月,订阅用户与 ARR 的环比增速均超 400%。 文|王欣逸 编辑|张雨忻 2026 年开年来,3D 生成模型赛道相当热闹。 今年第一季度,影眸科技发布首个 3D 编辑模型 Rodin

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。

当用户给出一句简单提示词时,当前的音视频生成模型往往已经能够生成具有不错质量的视听内容。然而,一旦提示词变得复杂,问题便开始暴露出来。
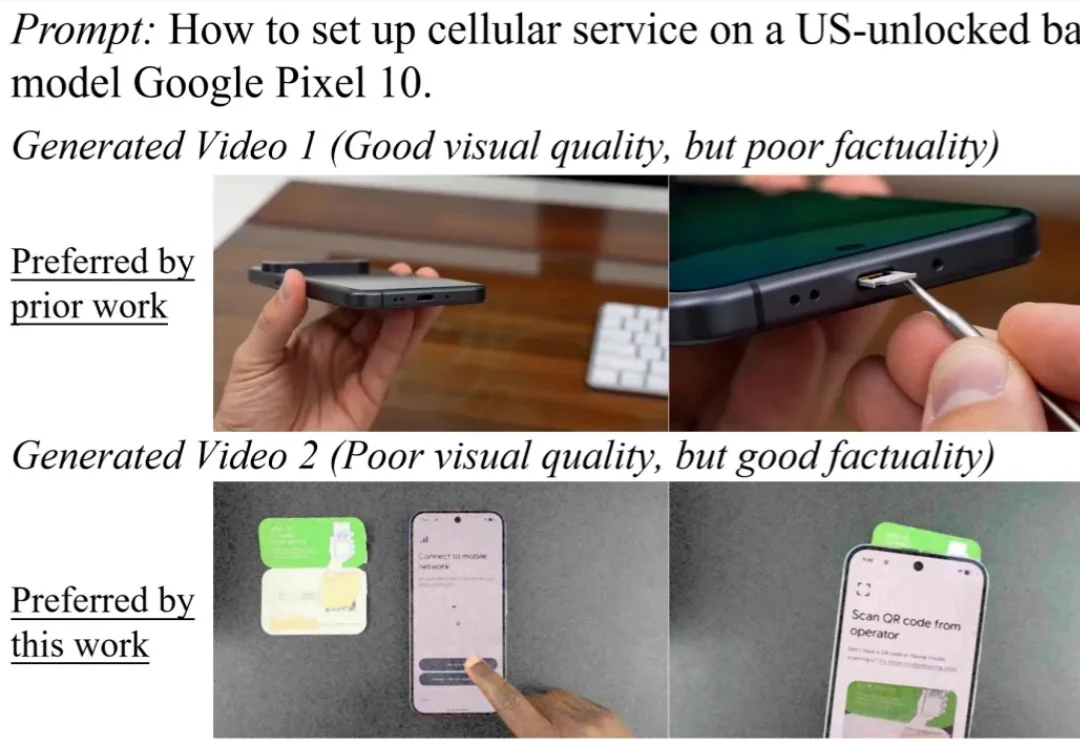
当视频生成模型走出娱乐创作的舒适区,进入科学、医疗、教育等知识密集场景,它们是否还能生成事实准确、清晰可用的视频?

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。
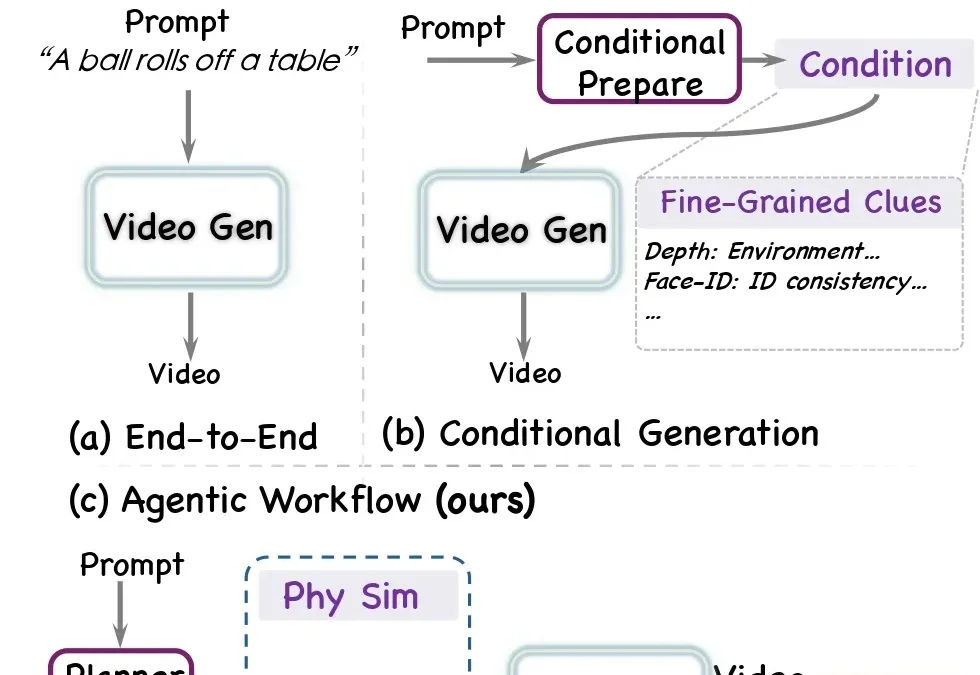
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
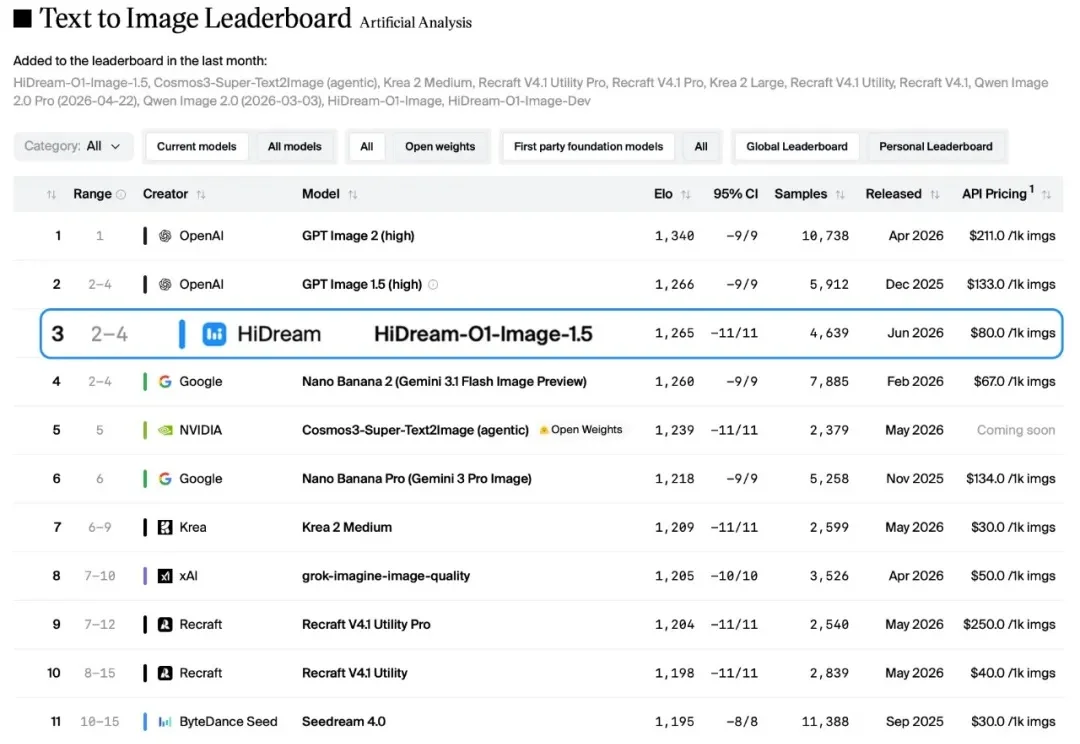
文生图的"慢思考",到底有没有用?