# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
但这件事并不容易。理解任务更依赖稳定、抽象、适合推理的语义表示,生成任务则要求模型保留充足的局部细节与高频纹理,以保证图像质量和真实感。近期越来越多工作都注意到,理解与生成在视觉表征和优化目标上存在天然张力,如何在同一个框架中兼顾二者,仍然是统一多模态建模最核心的挑战之一。
今天,我们正式介绍并开源发布 CHEERS。CHEERS 提出了一种面向统一多模态理解与生成的架构路线:在尽可能保持系统简洁的前提下,将理解任务与生成任务统一到同一个端到端框架中进行联合优化,并最大程度继承开源预训练模型已有知识。我们希望它回答的不只是 “能否统一”,更是能否以一种足够简洁、足够高效、足够开源友好的方式完成统一。Cheers 实现了:
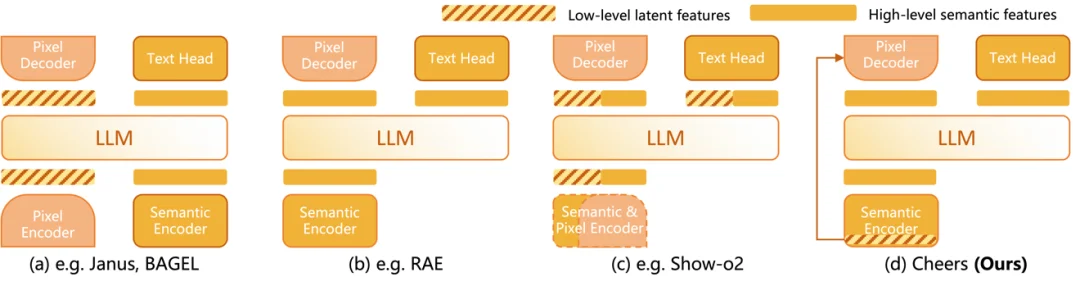
从视觉表示角度看,现有工作又大致呈现出几种典型思路。有些方法会把理解和生成放在相对分离的视觉空间里,各自优化、互不干扰,这类方案任务性能通常不差,但统一性相对有限;有些方法更强调单一语义空间,希望让同一套表示同时支撑理解与生成,但往往会在结构细节上遇到瓶颈;还有一些方法尝试融合异构特征,把语义信息与像素级信息汇总到一起,但融合之后也容易出现干扰和拉扯。CHEERS 的位置,正是在这些路线之间给出一个更加克制的答案:不追求把所有问题压缩成一种表示,也不走完全分离的双系统,而是在统一框架下重新安排语义与细节的职责。
在这个问题上,CHEERS 的出发点非常明确:不是为了统一而引入庞大而复杂的组合系统,而是在保留已有开源预训练能力的基础上,用尽可能小的架构增量完成从 “理解模型” 到 “理解 + 生成统一模型” 的升级。具体来说,CHEERS 构建了一个统一多模态大模型框架,通过统一视觉 tokenizer、LLM 主干以及 Cascaded Flow Matching Head,将多模态理解与图像生成纳入同一条端到端链路。
这个设计最重要的价值在于两点。第一,它实现了理解与生成任务的同时优化。同一个 LLM 主干既服务于文本自回归与多模态理解,也服务于图像生成过程中的条件建模,从而让统一不再停留在 “模块拼装”,而成为真正端到端的联合建模。第二,它尽可能继承了开源预训练模型已有知识。CHEERS 不需要为了 “统一化” 额外再做一轮昂贵的大规模预训练,而是完整保留并利用已有预训练能力,让统一多模态模型的构建成本显著降低。对于开源社区而言,这一点尤其重要,因为真正能被持续复现、扩展和使用的路线,不只是性能强,更要足够现实。
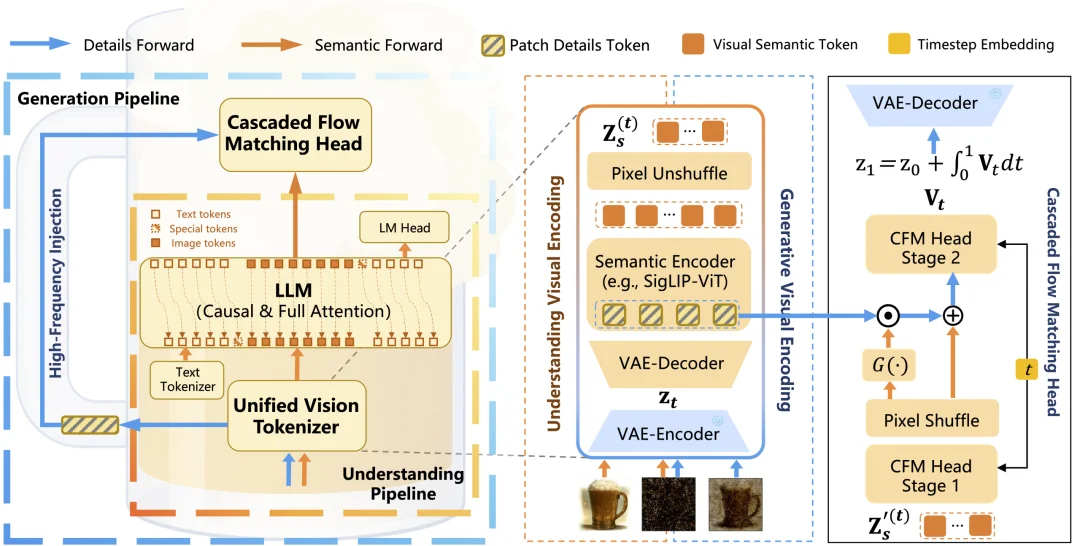
近期不少统一多模态工作都已经观察到类似经验:理解更偏向稳定语义,生成更依赖细节保真。这说明问题本身正在逐渐被行业看清。在 CHEERS 中,视觉信息被组织为两类互补成分:语义 token 用于多模态理解和生成条件控制,细节残差则用于在生成过程中补足高频纹理和局部保真。
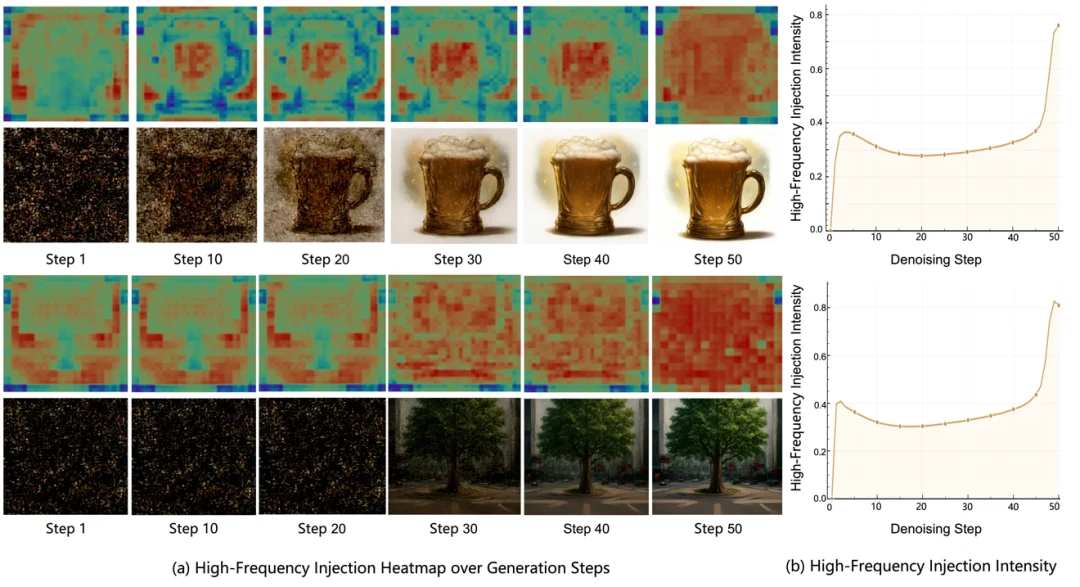
对应地,在生成阶段,CHEERS 采用 “先语义、后细节” 的级联方式:先生成全局语义布局,再通过语义门控逐步注入细节信息,对局部纹理进行修正和增强。同时我们发现,即便没有对高频细节注入强度做显式监督,模型也会在生成后期自然增强对高频细节的使用。这种现象非常像人类作画时 “先搭结构、再补内容、后补纹理” 的过程,也说明 CHEERS 的设计并不是机械堆叠模块,而是在建模上更贴近理解与生成各自的需求节奏。
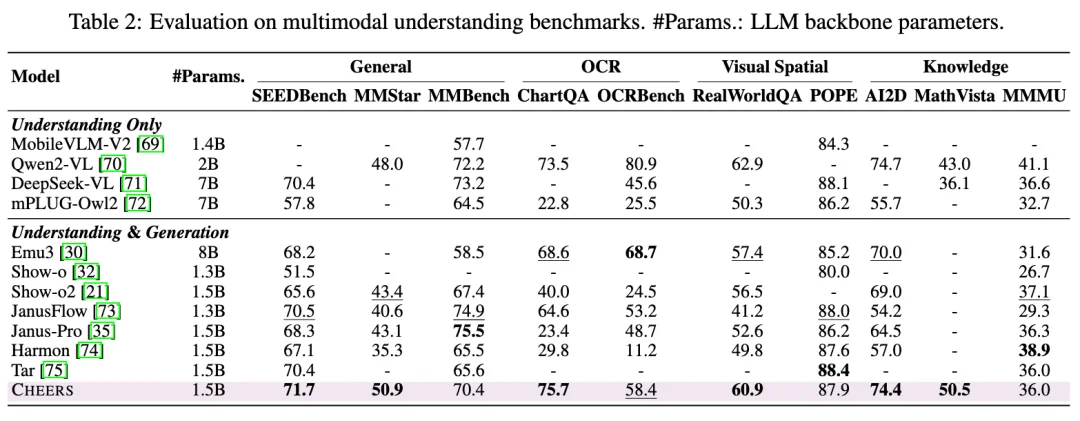
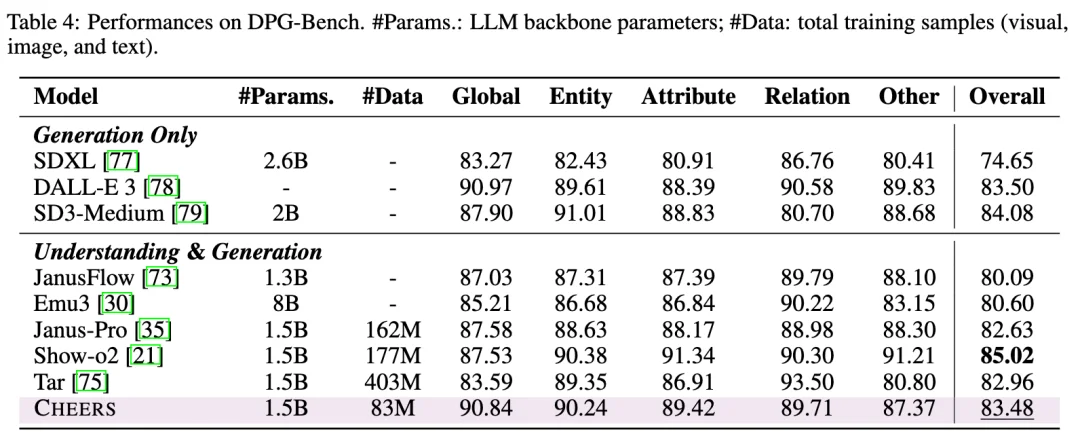
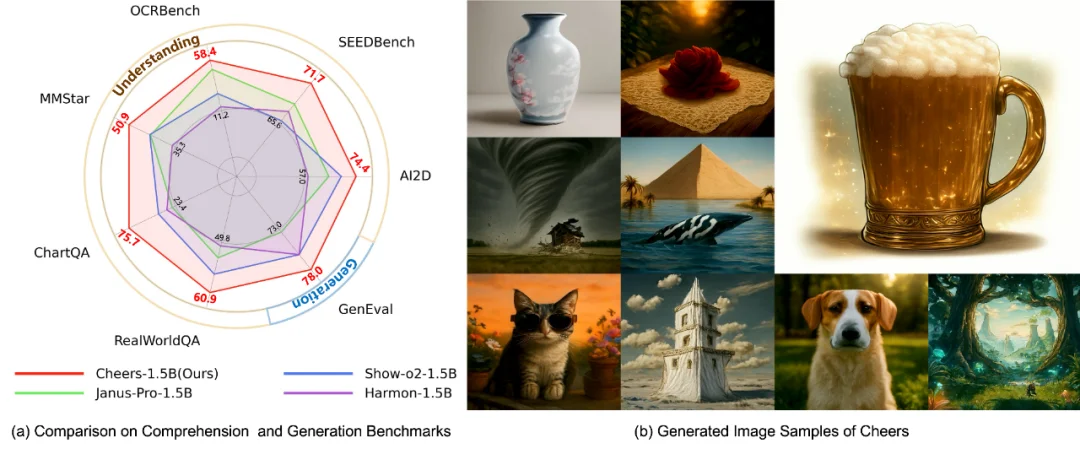
从实验结果来看,CHEERS 在同等规模统一多模态模型中取得了很强的综合表现。在多项主流理解基准与生成基准上,CHEERS 都展现出竞争性甚至领先的结果。论文中,CHEERS 在 GenEval 上达到 0.78,在 MMBench、MMStar、AI2D、MathVista 等理解基准上也取得了稳健表现。同时,CHEERS 还实现了 4× token compression,为高分辨率视觉理解与生成提供了更高效率的统一建模方式。
相比单纯列举性能,我们更想强调另一点:CHEERS 达成这些结果时,使用的数据规模显著小于部分同类方法。CHEERS 总训练样本规模为 83M,相比一些同类工作节省了约 2× 甚至更多的数据需求,仍然能够达到同规模 SOTA 或领先性能。这说明 CHEERS 的优势不只是 “训得出来”,而是它对已有预训练知识具有更高的继承和利用效率。某种意义上,这比单纯提升某个 benchmark 分数更值得关注,因为统一多模态走到今天,真正稀缺的已经不只是数据规模,而是如何把已有知识体系更高效地组织起来。
在我们看来,CHEERS 的意义不止体现在结果上,也体现在它对统一多模态研究提供了一些值得继续思考的方向。
第一个启发是:统一模型真正需要统一的,未必是单一视觉表示本身,而可能是一个足够稳定、足够高效的信息接口。如果不同任务对视觉信息的需求本来就不同,那么比起强行让所有能力共享同一份表征,更重要的也许是让不同信息以合适方式进入统一主干。
第二个启发是:理解与生成并不一定互相拖累,关键在于架构设计是否合理。论文表明,在统一架构设计下,联合训练生成目标不会显著破坏理解能力,反而有机会带来细粒度感知层面的增益。
第三个启发是:高效统一多模态,不一定意味着更重、更大、更复杂。CHEERS 用简单的系统改动,完成了从传统理解型 VLM 到统一模型的升级,这为后续很多开源工作提供了一种更现实的参考路径。
第四个启发是:效率问题本身就是统一多模态问题的一部分。CHEERS 的 4× token compression 不只是工程优化,也意味着高分辨率理解与生成可以在更现实的计算预算下被同时纳入一个系统中,这对未来更长上下文、更复杂视觉输入的统一建模都很关键。
我们期待的不只是一个更强的模型,而是一条让更多研究者和开发者都能继续往前推进的路线。因此我们开源了训练、推理测评代码和模型权重,并于近期开源微调数据。希望大家可以支持我们的工作。
作者简介:
张易辰,硕士,高级工程师,专注于理解生成统一方向,面向基础模型架构设计、大模型预训练进行了相关研究;彭达,硕士在读,专注于多模态理解和生成、高效推理,面向基础架构、预训练、视频高效编码进行了相关研究;通讯作者郭宗昊,博士,清华THUNLP访问学者,专注于多模态智能,面向多模态基础模型架构设计、大模型预训练与模型深思考能力进行了相关研究,在CVPR、NeurIPS、IJCV等顶会顶刊发表论文20余篇,谷歌学术引用超2000次。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
