
告别直接生成,文生图进入Agent时代:港中文联合伯克利开源Gen-Searcher
告别直接生成,文生图进入Agent时代:港中文联合伯克利开源Gen-Searcher过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
来自主题: AI技术研报
7191 点击 2026-04-10 08:34
 搜索
搜索
过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。

AI不再只是把两个物体「放一起」,而是真正造出一个新实体。VMDiff模型通过分阶段策略:先拼接保留信息,再插值融合成整体,并自动调节平衡,让生成结果既像两者,又自然统一。 过去,很多图像生成模型都能同时画出两个物体;但要让它们真正「长成一个新物体」,其实远没有那么简单。
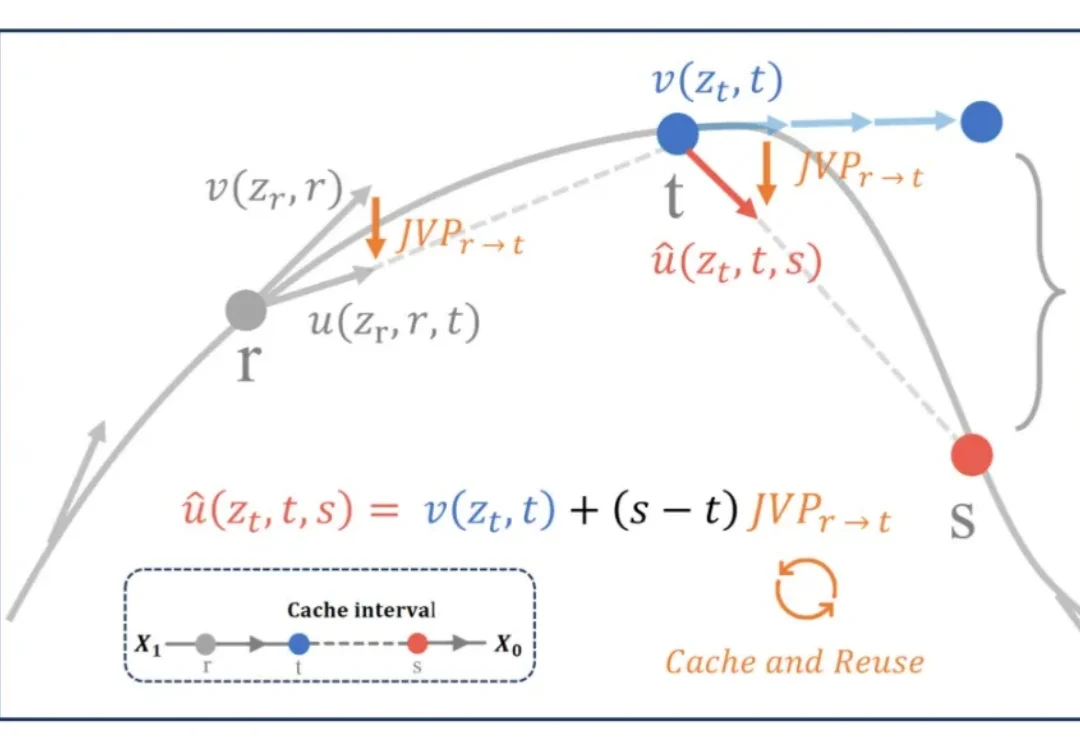
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
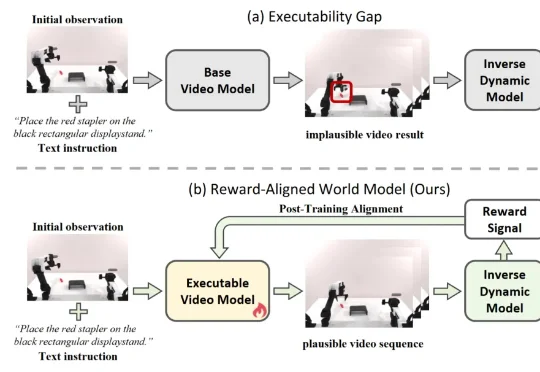
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。
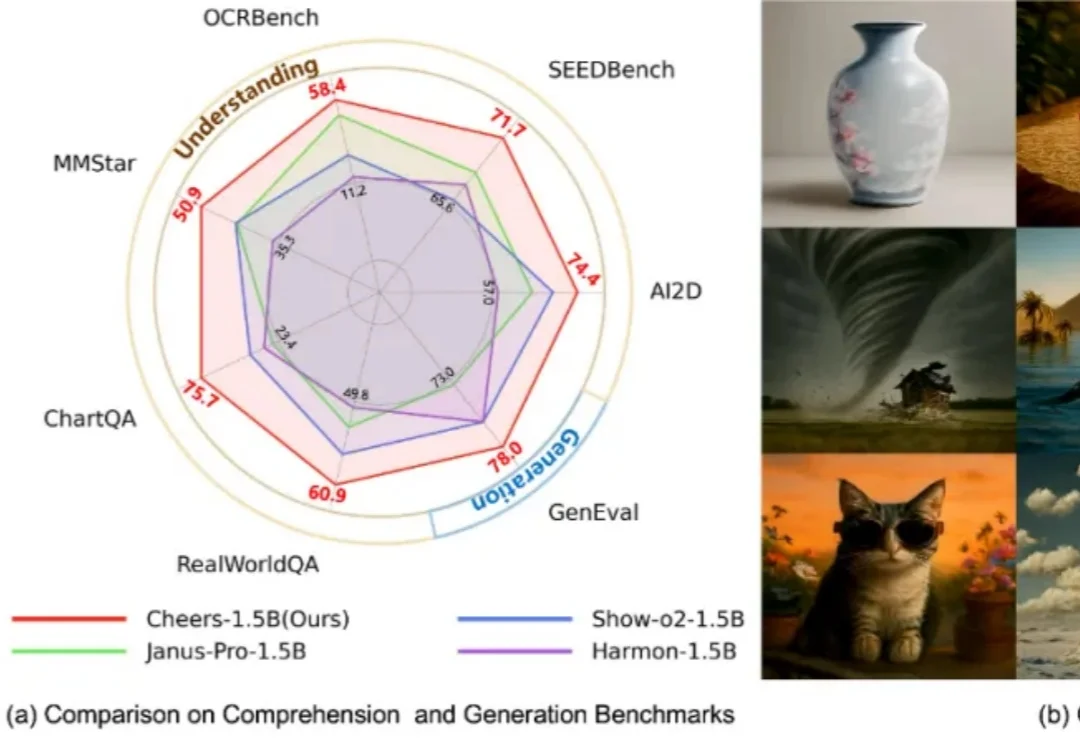
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
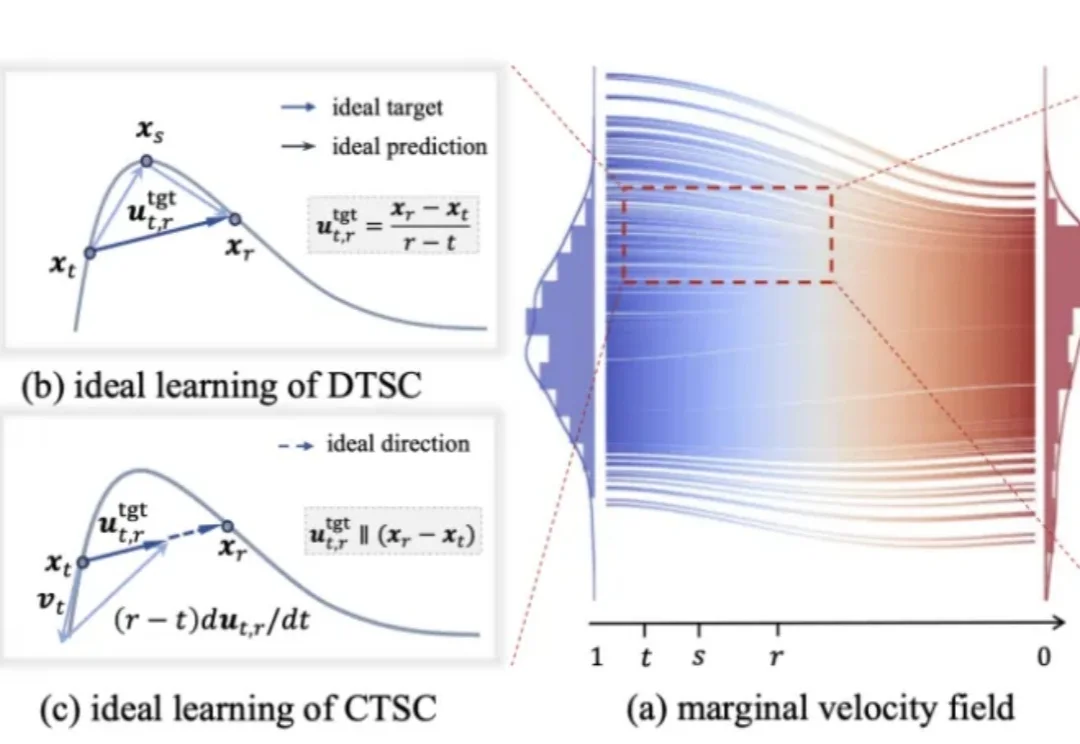
近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。

据 The Informaton 报道,字节跳动已经暂缓了视频生成模型 Seedance 2.0 的全球发布计划。背后的导火索,是一连串来自好莱坞头部片厂和流媒体平台的版权争议。
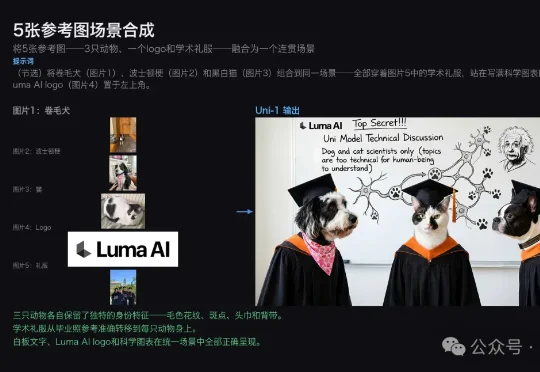
刚刚,Luma AI甩出全新模型Uni-1,正面对标谷歌Nano Banana Pro和GPT Image 1.5。Uni-1是一个统一的图像理解与生成模型。在官方展示中,Uni-1具备角色姿态迁移、故事板生成、草稿+材质结合参考生成、草稿转漫画、多参考图场景合成、草稿引导的照片编辑、UV贴图生成、带有文字的贺卡海报生成等诸多能力。
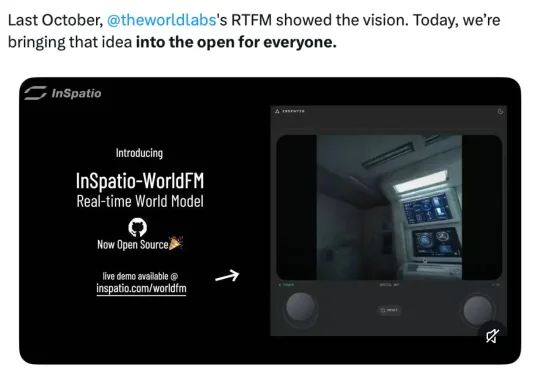
在 50 亿美元估值神话的背后,这一空间智能的最新高地正被国内创业公司攻克并推向产业纵深。近日,影溯(InSpatio)正式发布并开源了其实时帧生成模型 InSpatio-WorldFM,一个实时交互的 3D 世界模型。这标志着中国团队在空间智能底层技术上取得了奠基性突破,而且以开放的姿态,正成为推动 AI 从虚拟屏幕走向物理现实的关键破局者。