硬刚马斯克,超越Sora2的国产模型强势登场了!支持16秒声画同出
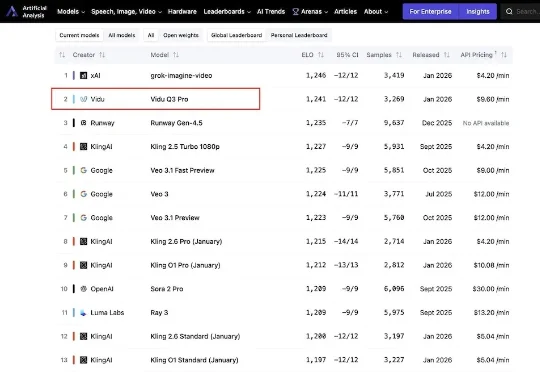
硬刚马斯克,超越Sora2的国产模型强势登场了!支持16秒声画同出今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
来自主题: AI资讯
10439 点击 2026-01-31 16:14
 搜索
搜索
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。
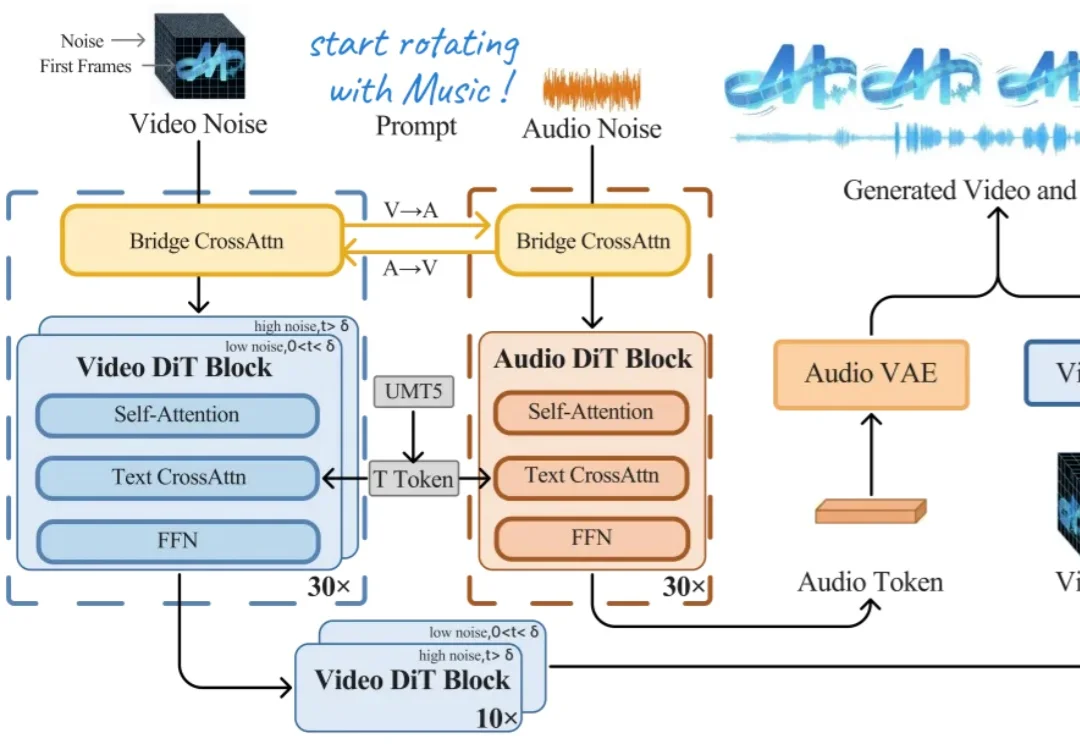
今天上午,上海创智学院 OpenMOSS 团队联合初创公司模思智能(MOSI),正式发布了端到端音视频生成模型 —— MOVA(MOSS-Video-and-Audio)。
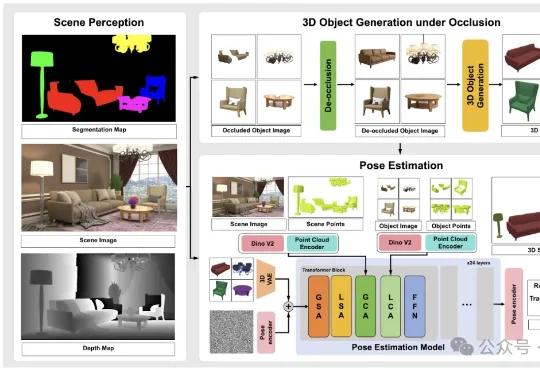
IDEA研究院张磊团队与香港科技大学谭平团队联合推出SceneMaker框架,有望攻克这一问题。 它以视启未来的万物检测模型DINO-X与光影焕像的万物3D生成模型Triverse为基础,实现了从任意开放世界图像(室内/室外/合成图等)到带Mesh的3D场景的完整重建。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
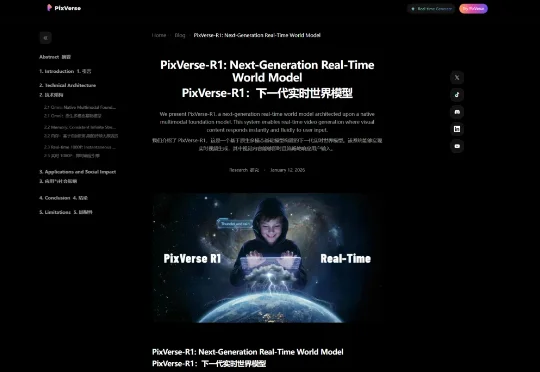
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。
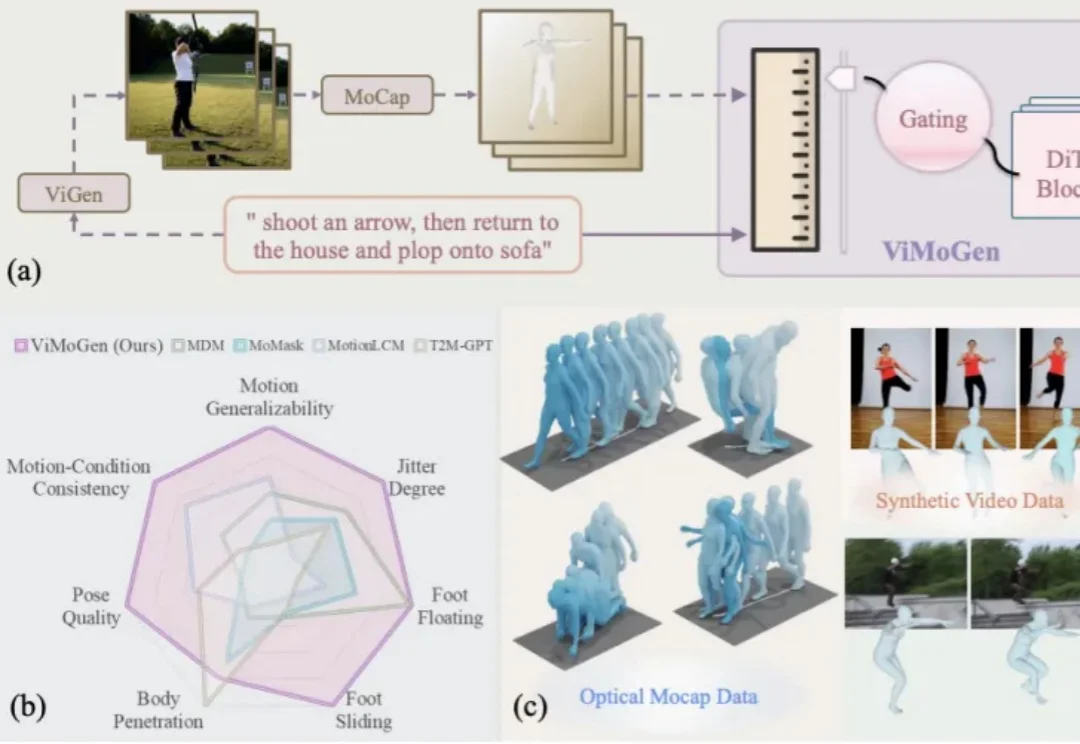
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。

大部分的高质量视频生成模型,都只能生成上限约15秒的视频。清晰度提高之后,生成的视频时长还会再一次缩短。
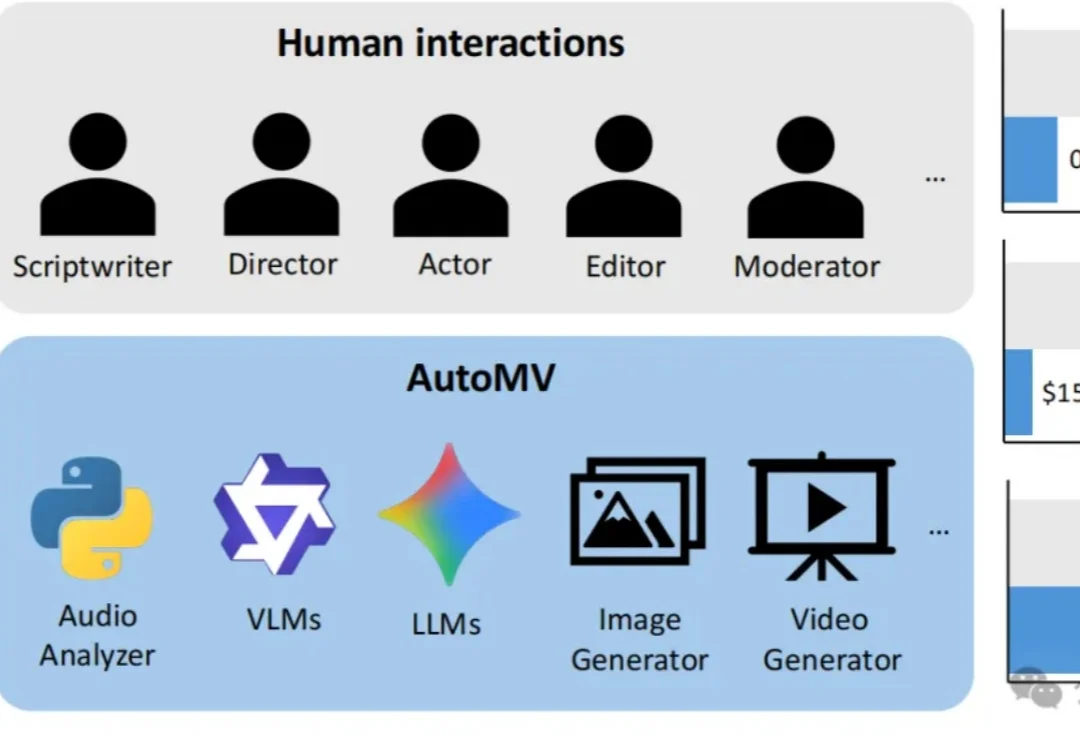
现有的AI视频生成模型虽然在短片上效果惊人,但面对一首完整的歌曲时往往束手无策——画面不连贯、人物换脸、甚至完全不理会歌词含义。