# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。
上述问题的根源在于,这些模型缺乏对科学规律的内在理解。它们学习到的只是像素分布,而非支配这些分布的动力学方程。更糟的是,科学数据具有稀缺性,且缺少语言描述(不像 “a dog is running” 那样易于提示),导致传统 “文本提示 — 图像生成” 范式在科学视频生成任务中失效。
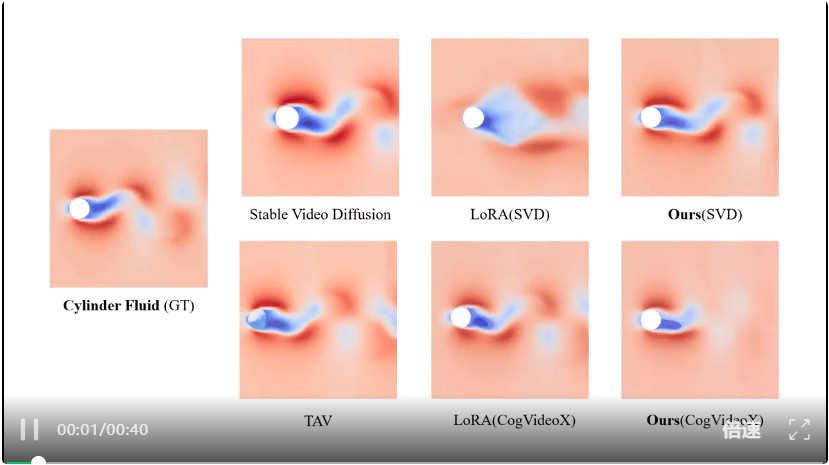 现有的视频扩散模型与本文新方法的生成效果对比
现有的视频扩散模型与本文新方法的生成效果对比
因此,在扩散模型不断重塑视觉生成的今天,一个全新的问题正在浮现:当 AI 可以生成炫丽的自然视频时,是否也能推演 “真实的科学现象”
这正是来自东方理工与上海交大的研究团队在最新研究中提出的挑战。他们在一篇新论文中,提出了一种让视频扩散模型学习 “潜在科学知识” 的全新框架,使模型在给定一帧初始图像的情况下,可以生成更为贴近物理规律的科学现象演化过程 —— 例如流体运动、台风路径、湍流结构等。

不同于以往依靠语言提示或大规模视觉数据的生成方式,这项方法让模型在 “看懂科学” 的基础上自己推演后续的演化轨迹,在生成式 AI 中注入了 “物理直觉(physical intuition)”。该研究已被人工智能顶会 AAAI 2026 正式接收。
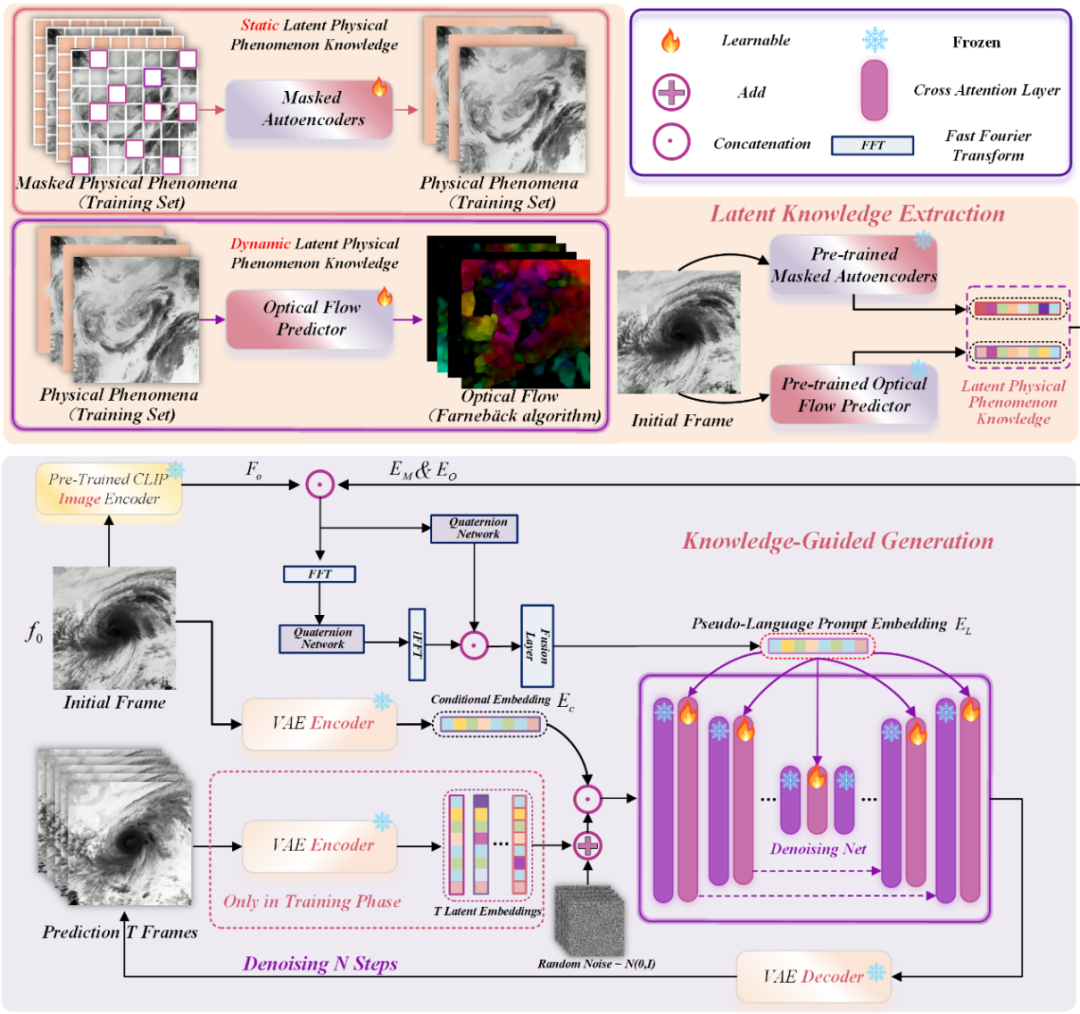
图一:整体算法框架。该方法通过参数高效的微调将潜在的物理现象知识融入视频扩散模型中,从而在数据受限的场景下实现更贴近物理规律的视频生成。
如图一所示,整个方法核心可分为三步:潜在知识提取 → 伪语言提示生成 → 知识引导视频生成。
研究的起点是极具挑战性的设定:模型只能获得一帧初始图像。在这种情况下,它需要有“潜在科学知识”,从而“推断”出后续的动态演化。为此,作者设计了两种互补的知识提取模块:
扩散模型通常依赖文字提示(prompt)来控制生成,但在科学领域,“语言提示” 很难准确定义。例如,用自然语言准确描述 “一个雷诺数为 10⁵ 的流场如何演化”就极为困难。为此,研究者创新性地利用了 CLIP 模型的跨模态对齐特性。他们将前一步提取的视觉特征与科学知识特征输入 CLIP 的视觉空间中,并通过一种四元数网络(Quaternion Network)进行投影,把这些潜在特征转换成伪语言提示嵌入(pseudo-language embeddings)。
这一步的关键思想是,避开文字局限,通过跨模态特征对齐与多维信息融合,使科学知识转化为可被扩散模型解析的引导信号。四元数网络使模型能在多维空间中同时处理图像、静态知识、动态知识与频率信息,从而生成能够引导扩散模型的语义性信号。研究者还将频域(Frequency Domain)特征注入提示生成过程,让模型在 “空间-频率” 两个维度理解科学规律。
在拥有这些 “伪语言提示” 后,研究者将其注入 Stable Video Diffusion (SVD) 或 CogVideoX 的注意力层,通过 LoRA(Low-Rank Adaptation) 的方式进行轻量微调。
在训练阶段,模型从真实的科学视频(如流体仿真、台风演化)中学习如何从噪声逐步重建出物理一致的视频序列;在推理阶段,它只需要输入一帧图像,就能借助潜在知识推演出整个动态过程 —— 实现从 “初态” 到 “演化” 的全程科学生成。这种机制让模型不再仅仅是图像生成器,而是一个能够模拟科学规律的世界现象生成器(World Phenomena Simulator)。
研究团队在流体力学仿真数据和真实台风观测数据上进行了大规模实验,结合数值精度指标和物理精度指标进行评估。该模型的输出不仅呈现效果更优,更关键的是,它生成得更 “科学”。
在实验中,研究者分别使用了四种典型的流体模拟场景:Rayleigh-Bénard Convection(瑞利 - 贝纳德对流)、Cylinder Flow(圆柱绕流)、DamBreak(溃坝流)和 DepthCharge(深水爆炸 / 水下爆炸)。这些都是流体力学中经典而复杂的物理过程。此外,研究者还将方法应用于真实卫星观测的台风数据,选取了 4 个台风事件(202001、202009、202102、202204),让模型在仅看到一帧初始卫星图像的情况下,推演整个风暴演化。
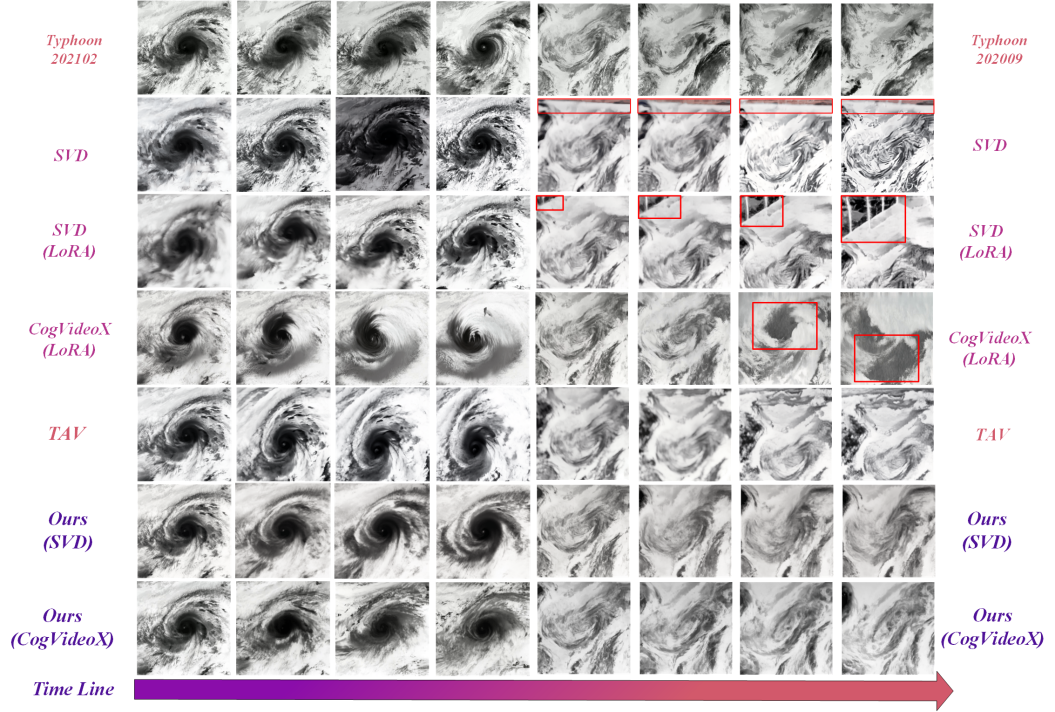
图二:台风现象生成效果对比。

图三:流体现象生成效果对比。
定性上看,如图二和图三所示,传统视频扩散模型(如 Stable Video Diffusion 或 CogVideoX)往往会 “画出” 违背物理规律的画面。在相同的初始帧下,传统模型生成的流体场常出现 “静止涡旋” 或 “反重力液面”,而本研究的模型则能自然还原出连续的流动与下泄过程。现有模型生成的台风中心漂移、风眼逆转、云层断裂;而新方法生成的视频不仅结构连贯,而且旋转方向、云带卷吸、能量分布都更好的保持了物理合理性。
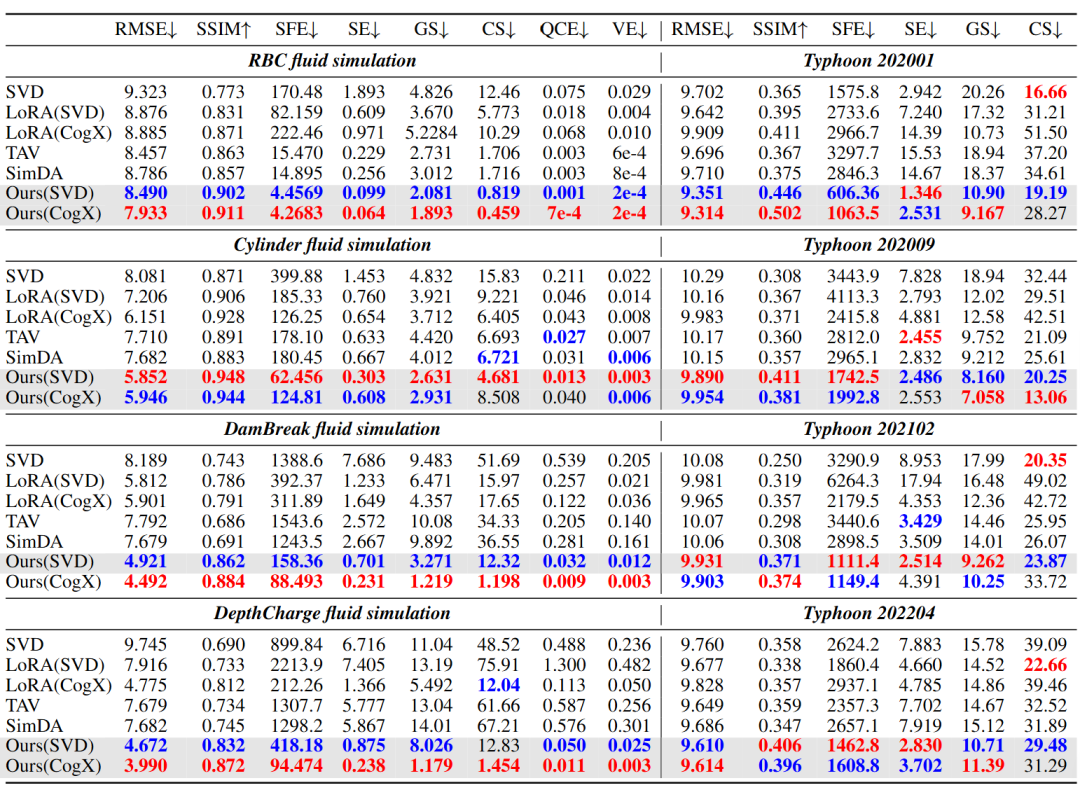
表一:对流体模拟数据(左)和真实台风数据(右)进行定量评估。
定量上评估,除了传统的 RMSE 和 SSIM 指标,为了验证生成结果是否 “符合科学”,研究团队设还基于六项物理一致性指标,从不同角度评估生成视频是否尊重物理规律:
如表一所示,在所有这些指标上,新模型都显著超越了主流方法。例如,在流体模拟任务中,Q-Criterion 误差降低了一个数量级,意味着生成视频的涡旋结构具有更强的物理一致性;而在台风预测任务中,SSIM 提升超过 10%,RMSE 降低 20% 以上,证明生成结果更加贴近真实观测。
综上所述,这项研究展示了生成式 AI 在科学建模方向上的一次有意义的探索。通过让视频扩散模型学习潜在的科学知识,研究团队让 AI 不再只是 “画出” 自然现象,而能 “推演” 出它们的演化逻辑。
在从一帧图像生成出完整科学过程的同时,模型也学会了遵守能量守恒、流体连续性等自然规律。需要明确的是,由于缺少未来边界条件等约束信息,其生成的并非未来真实发展的唯一结果,而是物理上可行的解。这种从 “视觉生成” 到 “科学生成” 的转变,意味着生成模型开始具备理解物理世界的潜能。
未来,这一方向有望在气象预测、流体仿真、地球系统建模等领域发挥更大作用,让 AI 真正成为科学家的助手,而不仅是艺术家的画笔。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
