

行业必读丨OpenAI 最新报告:AI 在企业中的应用
行业必读丨OpenAI 最新报告:AI 在企业中的应用OpenAI 最近发布了三份针对企业客户的研究报告,本次挑选了其中的「AI in the Enterprise」一篇进行了翻译。
来自主题: AI资讯
9979 点击 2025-04-21 12:17
OpenAI 最近发布了三份针对企业客户的研究报告,本次挑选了其中的「AI in the Enterprise」一篇进行了翻译。

还在用搜索和规则训练AI游戏?现在直接「看回放」学打宝可梦了!德州大学奥斯汀分校的研究团队用Transformer和离线强化学习打造出一个智能体,不靠规则、没用启发式算法,纯靠47.5万场人类对战回放训练出来,居然打上了Pokémon Showdown全球前10%!

OpenAI首席财务官Sarah Friar探讨了通往AGI的发展路径,目前OpenAI已到达第三阶段:智能体(Agent)。除Operator和深度研究Deep Research智能体外,OpenAI即将发布全球最强编程智能体。
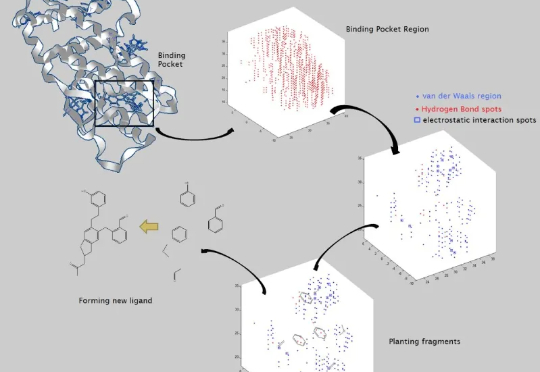
当前,人们对人工智能驱动的药物发现公司(以下简称 AIDD)这一新兴公司确发有效的界定。2025年开年,DeepSeek的爆火为AI医疗和AI制药领域带来了多维度变革。近日,BioPharma Trend发表了一份AI制药研究报告,报告力图从各个维度回答AI对生物医药的关键价值。

微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。
只用6GB显存的笔记本GPU,就能生成流畅的高质量视频!斯坦福研究团队重磅推出FramePack,大幅改善了视频生成中的遗忘和漂移难题。

当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

Two Heads are Better Than One"(两个脑袋比一个好/双Agent更优)源自英语中的一句古老谚语。MAS-TTS框架的研究者将这一朴素智慧应用到LLM中,创造性地让多个智能体协同工作,如同专家智囊团。

悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。

最近,人工智能研究人员开始认真关注赋予机器“接地性”(groundedness)——机器的表征与实际现实之间的可靠关系——以及记忆和对因果关系的理解等项目。新的技术方法正在促进人工智能这些能力的提升,毫无疑问,未来我们在这方面还将取得更多进展。