
ICLR高分论文险遭拒,只因未引用「造假」研究???作者怒喷:对方论文用Claude生成
ICLR高分论文险遭拒,只因未引用「造假」研究???作者怒喷:对方论文用Claude生成有在离谱。 高分论文因为没有引用先前的研究而被ICLR拒稿了?!
来自主题: AI资讯
7423 点击 2025-04-14 15:24
有在离谱。 高分论文因为没有引用先前的研究而被ICLR拒稿了?!
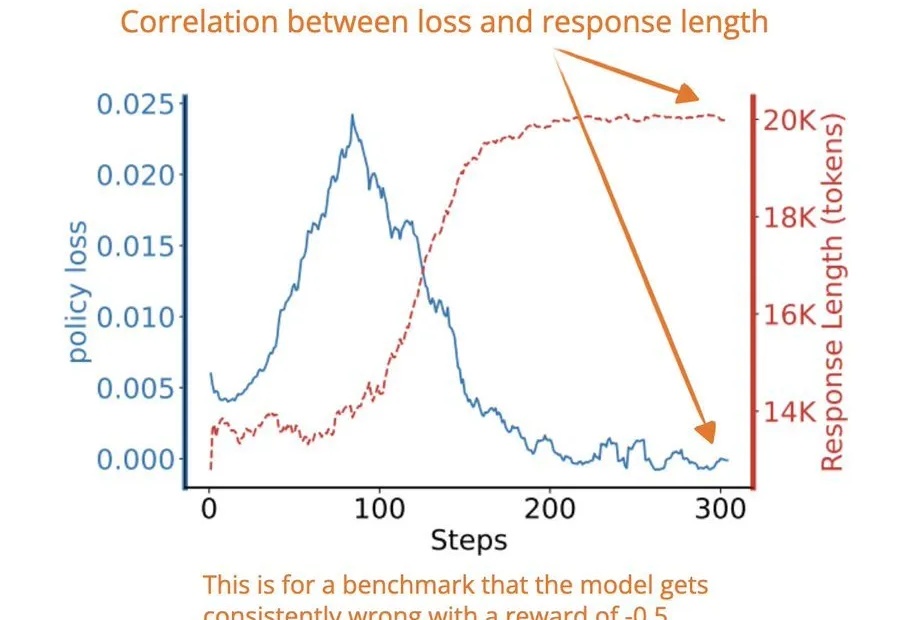
今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
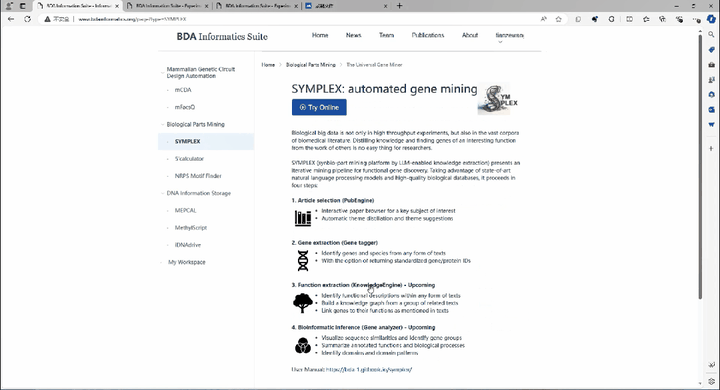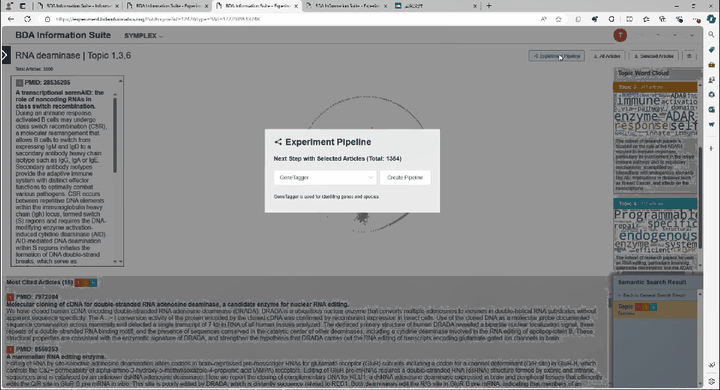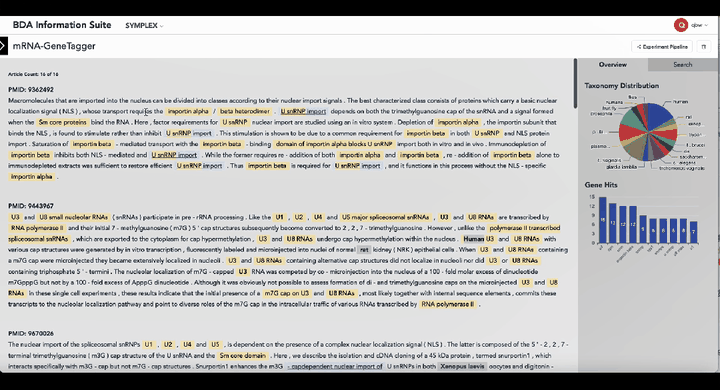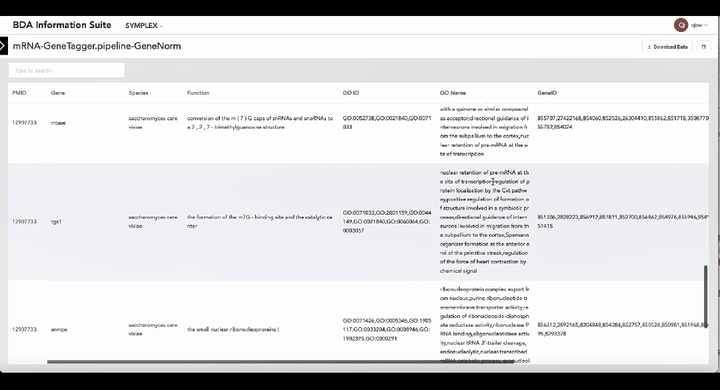
中国科学院深圳先进技术研究院娄春波团队与北京大学定量生物学中心钱珑团队成功推出一款生物制造大语言模型SYMPLEX。SYMPLEX是全球首个面向合成生物学元件挖掘与生物制造应用的大语言模型。
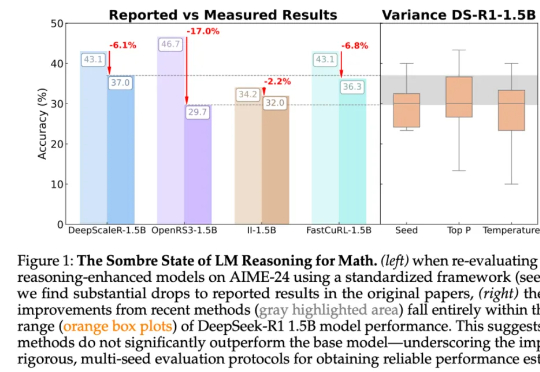
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

在这篇文章中,我采用了与去年研究人们如何使用 AI 的相同方法,但搜索了更多数据,并将结果限制在过去 12 个月内。我查看了在线论坛(Reddit、Quora)以及包含明确、具体的技术应用的文章。也许是由于其固有的匿名性,Reddit 再次提供了最丰富的见解。我阅读了这些文章,并将每个相关帖子添加到该类别的统计中。几天后,我统计出了 100 个新的使用案例,并逐一引用。

仅用4090就能实现大规模城市场景重建!

印度人工智能初创公司 Ziroh Labs ,与该国顶尖技术学院的研究人员合作,设计出一套经济实惠的系统,据称无需依赖英伟达公司等提供的高端计算芯片,即可运行大型 AI 模型。
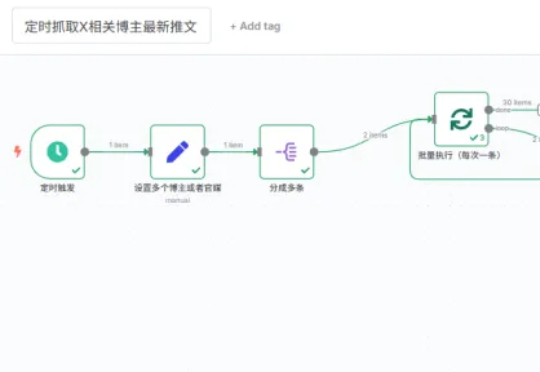
前两天给大家分享了一个我认为最强的开源AI Workflow平台:n8n。经过这几天的研究,我用n8n实现了一套超实用的X(原Twitter)热点监控workflow(工作流)。它由两个workflow(工作流)组成