
Claude团队发布完整Prompt Engineering指南,助力无代码开发热潮
Claude团队发布完整Prompt Engineering指南,助力无代码开发热潮今天我兴奋地跟大家分享一个超级实用的新资源——Claude团队刚刚发布了一份全面的Prompt Engineering指南!作为一个每天都在摸索各种AI提示技巧的科技爱好者,我第一时间深入研究了这份指南,发现这简直就是AI无代码开发的宝典啊!
来自主题: AI资讯
9309 点击 2025-04-07 09:09
今天我兴奋地跟大家分享一个超级实用的新资源——Claude团队刚刚发布了一份全面的Prompt Engineering指南!作为一个每天都在摸索各种AI提示技巧的科技爱好者,我第一时间深入研究了这份指南,发现这简直就是AI无代码开发的宝典啊!
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
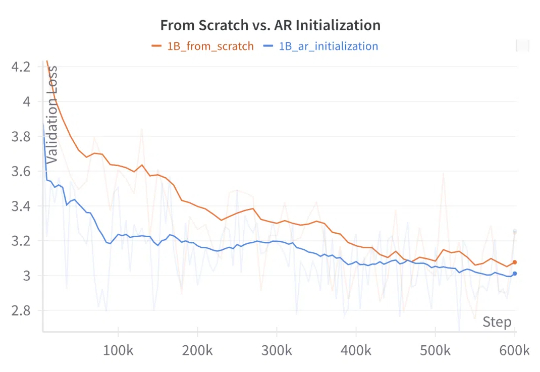
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。

最新研究发现,LLM在面对人格测试时,会像人一样「塑造形象」,提升外向性和宜人性得分。AI的讨好倾向,可能导致错误的回复,需要引起警惕。
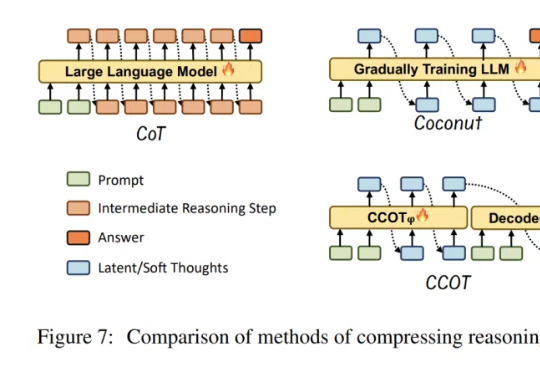
大模型虽然推理能力增强,却常常「想太多」,回答简单问题也冗长复杂。Rice大学的华人研究者提出高效推理概念,探究了如何帮助LLM告别「过度思考」,提升推理效率。

前OpenAI研究员Daniel Kokotajlo团队发布了「AI 2027」预测报告,描绘了一个超人AI崛起的未来:从2025年最贵AI诞生,到2027年自我进化的Agent-5渗透政府决策,人类可能在不知不觉中交出主导权。

DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。DeepSeek R2,果然近了。

Meta AI研究副总裁Pineau亲自发帖声称将于5月30日离职,她主导了Llama开源系列及PyTorch项目。此举正逢扎克伯格重金投入AI及LlamaCon AI大会前夕,引发业内对Meta战略调整和未来新作的诸多猜测。

PaperBench 是一个由 OpenAI 开发的基准测试,旨在评估 AI Agent 复现尖端 AI 研究的能 力。它专注于测试 AI 是否能理解研究论文、独立开发代码并执行实验以复现研究结果。

在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人: