
7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!
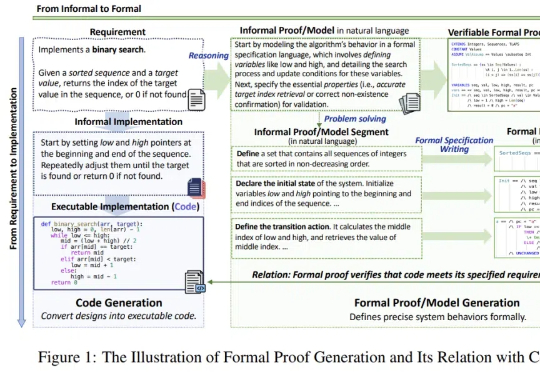
7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
来自主题: AI技术研报
6173 点击 2025-03-09 10:31
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
AI研究智能体全新升级!Meta等推出MLGym,一个专门用于评估和开发LLM智能体的Gym环境。MLGym提供了标准化的基准测试,让LLM智能体在多任务挑战中展现真正实力。

来自哥本哈根大学、苏黎世联邦理工学院等机构的研究人员,提出了一个全新的多模态Few-shot 3D分割设定和创新方法。无需额外标注成本,该方法就可以融合文本、2D和3D信息,让模型迅速掌握新类别。

据ZP独家获悉,半图科技(SemiGraph)近日完成了一轮数千万人民币的天使轮融资,全球知名投资机构IDG资本独家投资。据了解,半图科技正式成立于2024下半年,致力于通过创新的技术推动AI应用领域的变革,尤其聚焦于AI技术在游戏、内容、情感交互等领域的深度应用。此次融资的成功为公司3D动画大模型底层技术的突破提供了强有力的资金支持,并有望加速其产品和技术的市场落地。

Ilya团队再次拿到20亿美元新一轮融资,估值300亿美元。与此同时,SSI在以色列特拉维夫办公室的首支研究团队的成员曝光,阵容堪称豪华。硅谷当下投资最热门,不是某个产品,而是一个人。
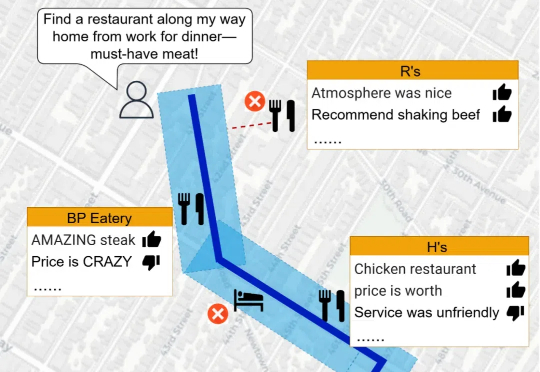
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。

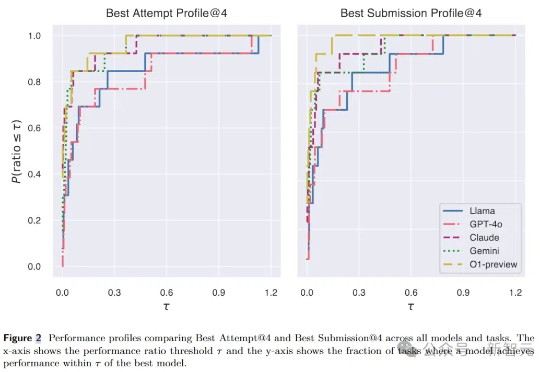
推理模型在复杂任务上表现惊艳,缺点是低下的token效率。UCSD清华等机构的研究人员发现,问题根源在于模型的「自我怀疑」!研究团队提出了Dynasor-CoT,一种无需训练、侵入性小且简单的方法。
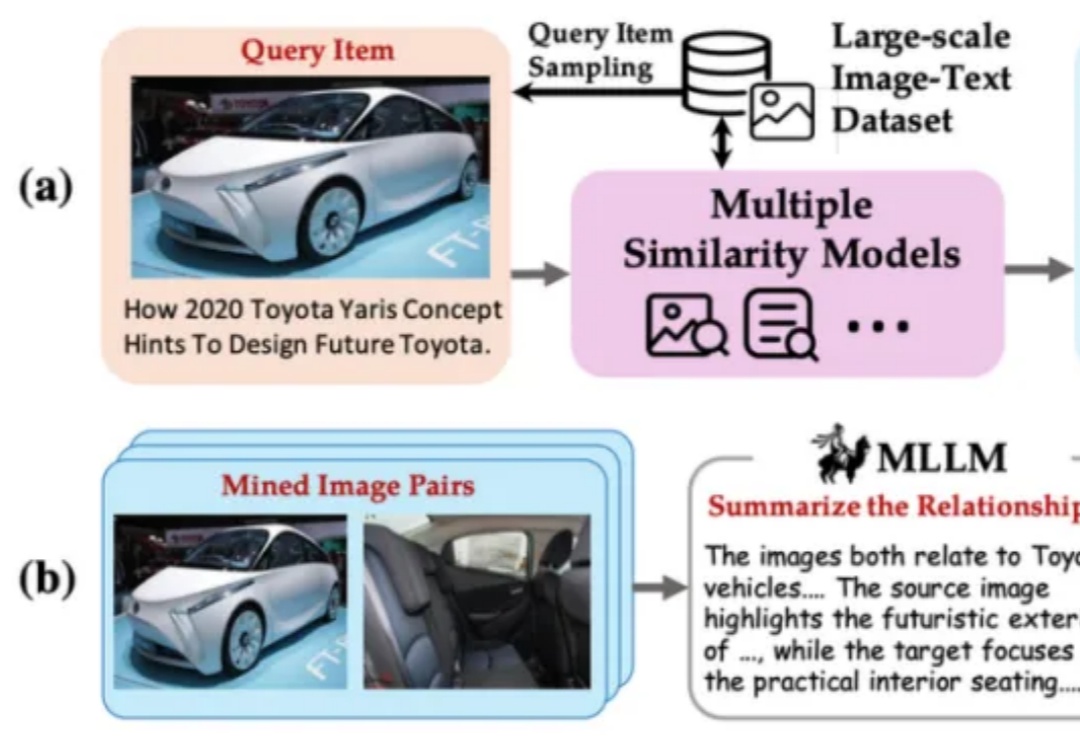
BGE 系列模型自发布以来广受社区好评。近日,智源研究院联合多所高校开发了多模态向量模型 BGE-VL,进一步扩充了原有生态体系。
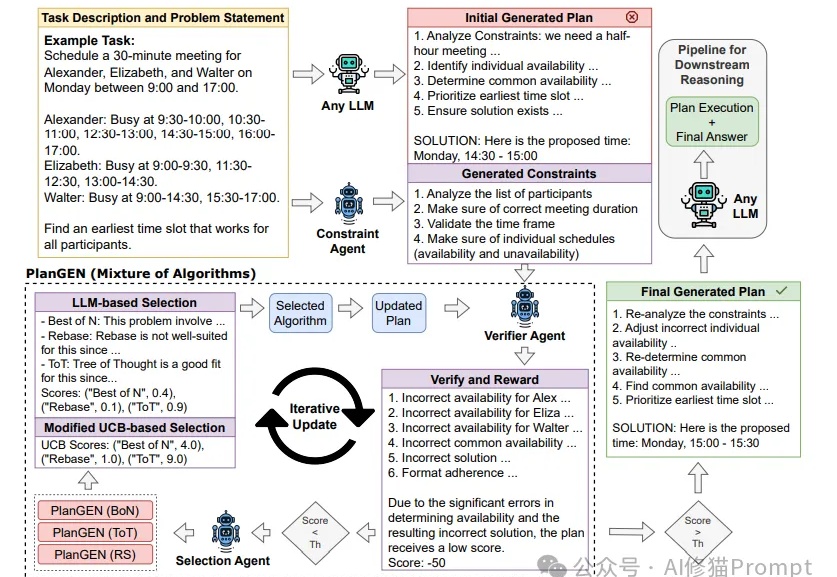
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

刚刚,OpenAI被爆三类智能体定价!价格从每月2k美元到20k美元不等,用于自动化编码和博士级别的研究等任务。此前,美国国家实验室使用OpenAI的o1模型来解决了与核聚变相关的问题。