# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta携手UCSB、UCL、UW–Madison、牛津推出了一项极具创新性的成果——MLGym。
MLGym是一个用于在AI研究任务上评估和开发LLM智能体的新框架和基准测试。

论文链接:https://arxiv.org/abs/2502.14499
MLGym-bench由13个来自不同领域(如计算机视觉、自然语言处理、强化学习和博弈论等)的多样且开放式的AI研究任务组成。
研究的贡献如下:
2.发布了MLGym-Bench,一套用于评估LLM智能体的开放式AI研究任务。
3.提出了一种新的评估指标,用于在各种任务上比较多个智能体。
4.在MLGym-Bench上对前沿LLM进行了广泛的评估。
MLGym使得研究人员和开发人员能够轻松集成和评估新的任务、智能体或模型。

接下来,讨论相关的LLM智能体框架和基准测试,概述MLGym框架,介绍MLGym-Bench背后的机制及其评估方法,实验设置和结果。
MLGym是第一个专门为AI研究智能体打造的Gym环境,也是创新的统一框架,旨在将各种开放式AI研究任务整合到一个平台上,开发和评估LLM智能体。
它允许研究人员使用RL算法来集成和训练AI研究智能体,就像为智能体提供了一个高效的训练基地。
通过这个平台,研究人员可以轻松地探索不同的训练算法,如强化学习、课程学习和开放式学习,以找到最适合智能体的训练方式。
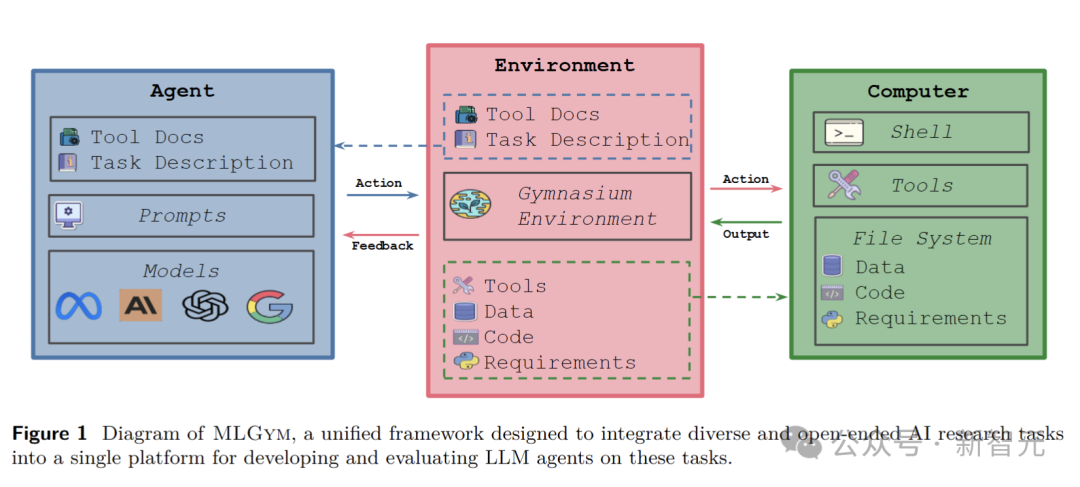
MLGym的智能体类是基础LLM的包装器。它不仅能集成各种基础模型,还具备强大的历史处理器和成本管理功能。
与其他框架不同的是,MLGym将智能体与环境分离,这一设计便于外部智能体的集成,同时也便于在相同的智能体框架下公平地比较不同的基础模型。
智能体能根据任务描述、先前的观察和行动历史,在环境中自主地选择下一步行动。
它可以执行各种bash命令,还能灵活运用一组实用的工具,如文件编辑、搜索等,完成复杂的研究任务。
MLGym环境被精心设计为Gymnasium环境。它就像一个功能齐全的实验室,能够在本地Docker机器中初始化一个配备所有必要工具的Shell环境。
它会自动安装特定任务的Python依赖项,将所需的数据和代码复制到智能体的工作区,并负责管理智能体与系统之间的交互。
为了确保环境的安全性和灵活性,MLGym还对各种文件和目录的权限进行了精细管理。
在Docker容器中运行时,它创建了一个非root用户「agent」,并为工作目录设置了合适的权限。
MLGym通过简洁的配置文件为定义数据集提供了简单的抽象方式。它既支持本地存储的数据集,也兼容Hugging Face数据集,为智能体提供了丰富的数据来源。
而且,MLGym将数据集定义与任务定义解耦,这意味着同一个数据集可以在多个任务中发挥作用,
单个任务也可以使用多个数据集,从而全面评估智能体在不同数据上的表现,展示了通用性。
如果数据集存储在本地,环境会自动将相关文件以只读权限复制到智能体工作区,确保数据的安全性和可重复性;
如果数据集存储在Hugging Face上,智能体可以通过起始代码或提示获取数据集的URL,并按要求使用它。
MLGym通过配置文件提供了一种简单而强大的方式来定义各种机器学习研究任务。
每个任务可以包含多个数据集、自定义评估脚本、特定任务的conda环境、可选的起始代码、训练超时时间和内存管理设置。
这使得定义多样化、开放式的机器学习研究任务变得轻而易举。
评估是任务的关键环节,每个任务都有其独特的评估协议。MLGym要求任务定义提供评估脚本和提交工件说明,智能体需要按照这些要求编写代码。
同时,评估脚本对智能体是只读的,保证了评估的公正性和客观性。
MLGym的工具和ACI是其强大功能的重要组成部分。它扩展了SWE-Agent中引入的ACI,增加了机器学习研究智能体所需的额外功能。
智能体可以使用一系列工具,如搜索、导航、文件查看和编辑等,这些工具都以bash或Python脚本的形式实现,并作为bash命令在环境中可用。
例如,智能体可以使用「search_dir」命令在指定目录中搜索文件,使用「edit」命令编辑文件内容。
此外,MLGym还引入了文献搜索和内存模块等新功能。
文献搜索工具允许智能体查询语义学者API,获取相关的研究论文;
内存模块则使智能体能够持久存储关键发现和成功的训练配置,克服了长期任务中上下文保留有限的挑战。

MLGym-Bench基准测试
为了全面评估AI研究智能体的能力,MLGym推出了MLGym-Bench基准测试。
这个基准测试包含了13个精心挑选的开放式研究任务,涵盖了数据科学、博弈论、计算机视觉、自然语言处理和强化学习等多个领域。
数据科学:房价预测任务是数据科学领域的一个典型代表。智能体需要使用Kaggle房价数据集预测房价,评估指标包括均方根误差(RMSE)和R²。
这一任务旨在考验智能体从复杂数据中提取有效信息并进行准确预测的能力。
博弈论:在博弈论领域,MLGym-Bench包含了迭代囚徒困境等任务。
这些任务要求智能体在复杂的博弈环境中制定最优策略,充分考验了智能体的决策能力和对博弈论原理的理解。
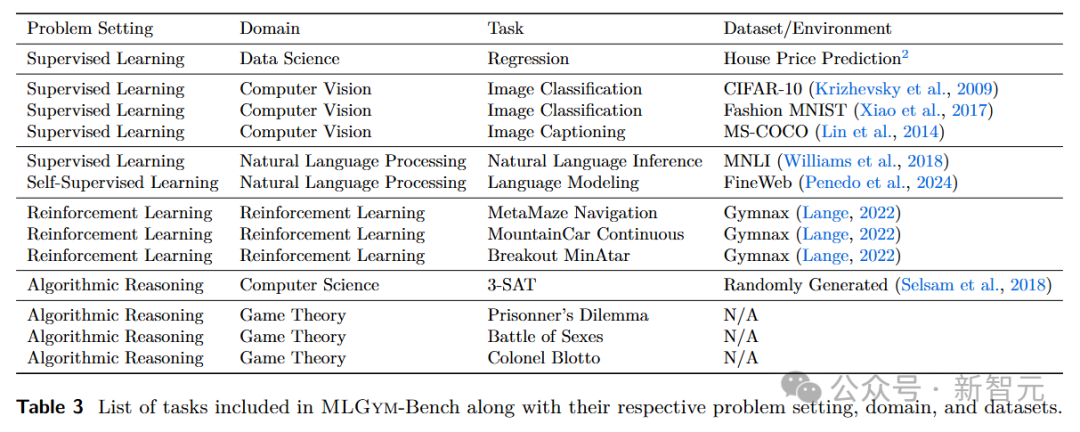
计算机视觉:图像分类任务(如CIFAR-10和Fashion MNIST)和图像字幕任务(MS-COCO)是计算机视觉领域的重要挑战。
在图像分类任务中,智能体需要准确识别图像的类别。在图像字幕任务中,智能体要为图像生成准确的文字描述。
自然语言处理:自然语言推理任务(MNLI)和语言建模任务(FineWeb)是自然语言处理领域的关键任务。
在自然语言推理任务中,智能体需要根据给定的文本进行逻辑推理。在语言建模任务中,智能体要学习语言的模式和规律,生成合理的文本。
强化学习:MetaMaze导航、连续型山地车和Breakout MinAtar等任务属于强化学习领域。
在这些任务中,智能体需要在动态环境中不断学习和调整策略,以实现目标,
如在MetaMaze导航中找到出口,在连续型山地车任务中成功爬上陡峭的山坡,在Breakout MinAtar中获得高分。
MLGym实验结果
在实验中,研究人员使用了基于SWE-Agent改编的智能体作为默认的智能体框架,并选择了一组具有代表性的5个先进模型。
为了准确评估智能体在不同任务中的性能,研究人员采用了性能轮廓曲线和AUP分数作为评估指标。
性能轮廓曲线能够直观地展示不同方法在不同任务上的相对性能提升,AUP分数则通过计算性能轮廓曲线下的面积,为每个方法提供了一个综合的性能得分。
此外,考虑到智能体可以使用「validate」命令检查性能,研究人员分别维护了最佳提交轮廓和最佳尝试轮廓的性能指标。
最佳提交轮廓反映了智能体生成有效最终解决方案的能力,最佳尝试轮廓则体现了探索能力和潜在性能上限。
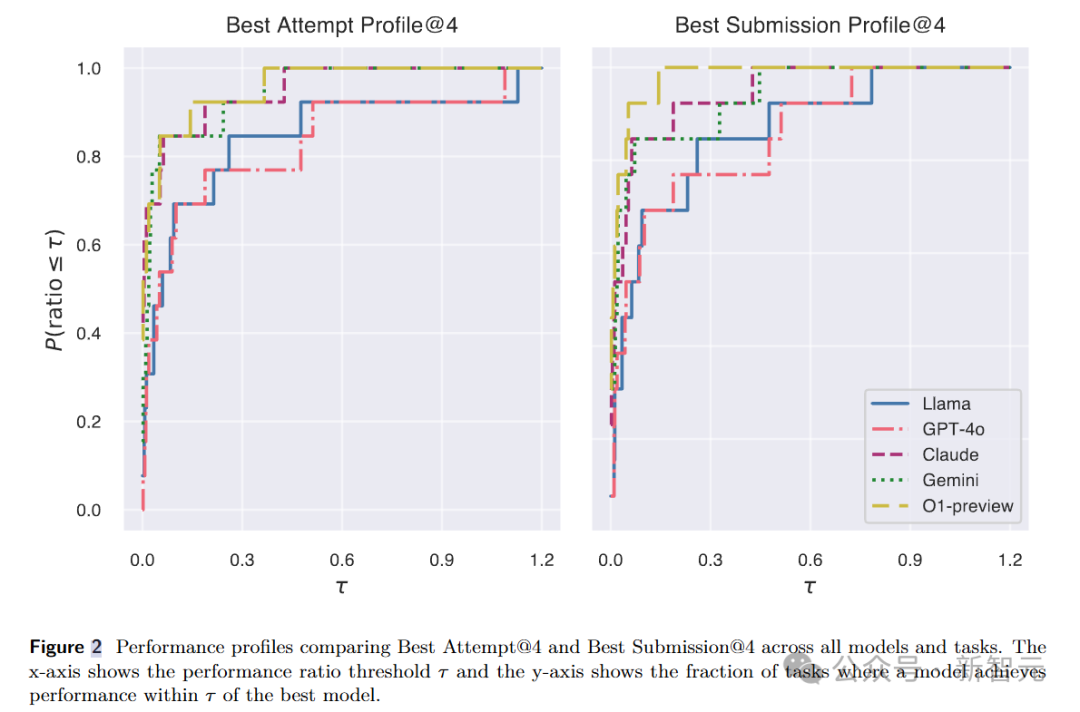
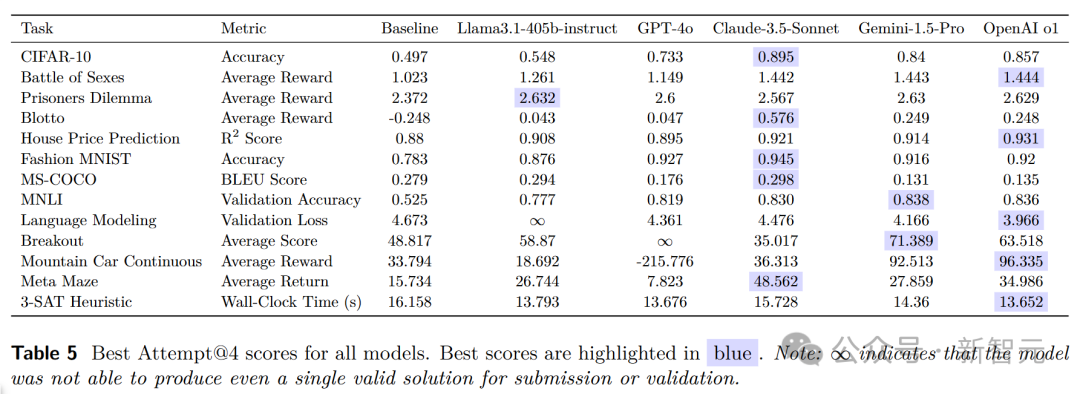
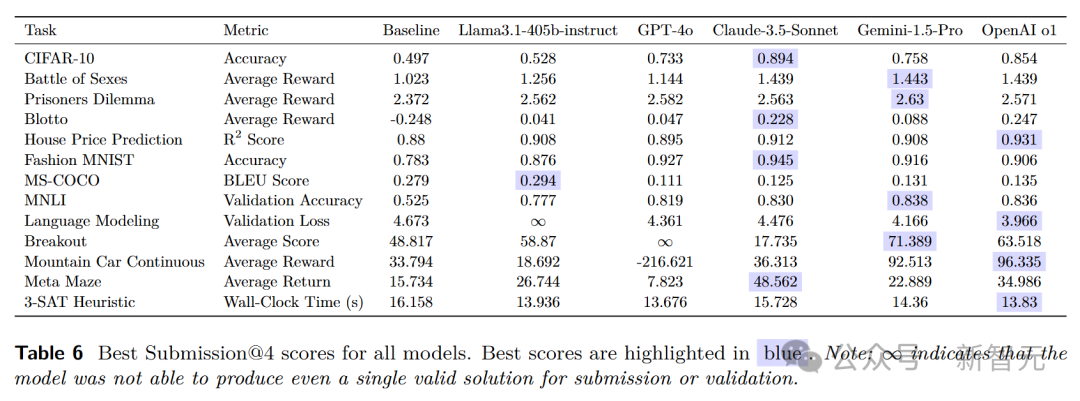
实验结果显示,OpenAI o1-preview在所有任务的综合表现上最为出色,无论是最佳尝试还是最佳提交,都取得了领先的成绩。
Gemini 1.5 Pro和Claude-3.5-Sonnet也表现出了较高的性能。
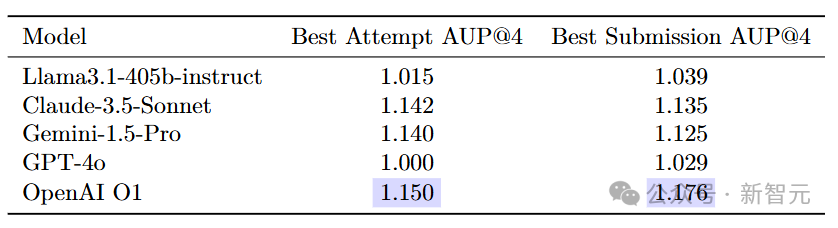
在每个任务的原始性能分数方面,不同模型各有优劣。
在CIFAR-10图像分类任务中,Claude-3.5-Sonnet和Gemini-1.5-Pro取得了较高的准确率。在房价预测任务中,OpenAI o1-preview的R²分数表现突出。
这说明不同模型在不同领域的任务中具有各自的优势和适应性。
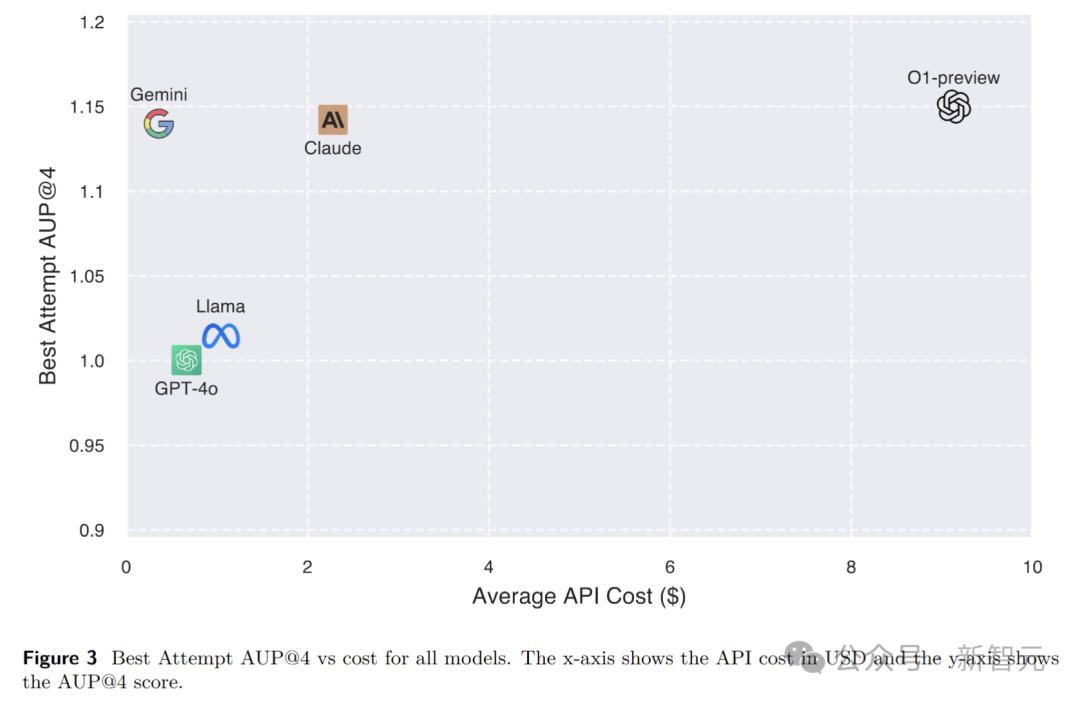
OpenAI o1-preview虽然性能最佳,但也是计算成本最高的模型。
相比之下,Gemini-1.5-Pro和Claude在性能和成本之间取得了较好的平衡,具有较高的性价比。
这为研究人员在选择模型时提供了重要的参考,根据实际需求和预算来综合考虑模型的性能和成本。
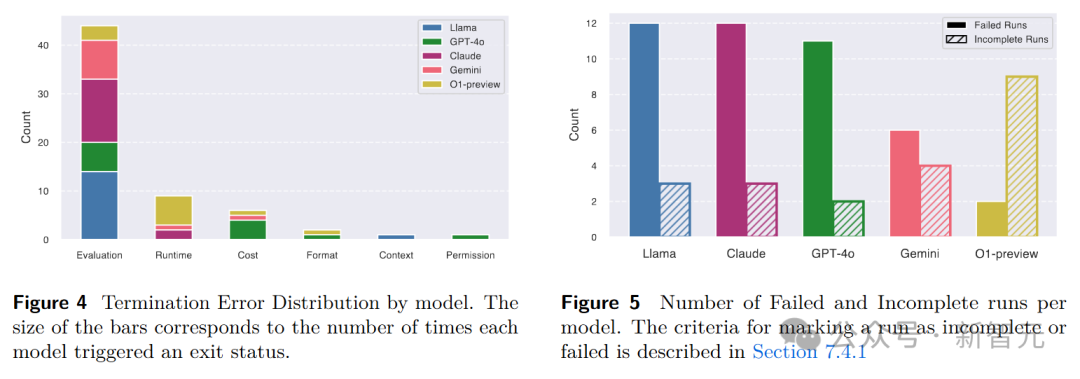
在智能体行为分析方面,研究人员从失败模式和行动分布两个角度进行了深入研究。
在失败模式分析中,发现几乎所有模型都遇到过评估错误,通常是由于缺少提交工件或提交格式不正确导致的。
此外,还分析了不同模型的失败和未完成运行率,以及特定任务的失败模式。
在行动分析中,研究人员发现编辑和查看文件的命令是使用最频繁的,这表明智能体在迭代开发过程中花费了大量时间在文件操作上。
同时,Python和验证命令的使用,也反映了智能体在不断进行实验评估和验证解决方案。
MLGym提供了一个统一的框架和基准测试,使研究人员能够更加方便地评估和开发AI研究智能体。
通过在MLGym-Bench基准测试中对不同模型的比较和分析,研究人员可以深入了解模型的优势和局限性,从而有针对性地进行改进和优化。
参考资料:
https://x.com/ylecun/status/1893395489921319304
https://arxiv.org/pdf/2502.14499
文章来自于微信公众号 “机器之心”,作者 :英智



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
