
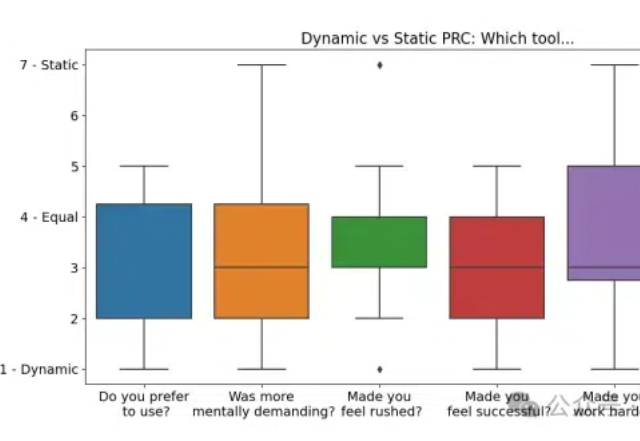
微软新作:动态Prompt中间件,用图形界面细化控制上下文,让你的提示更懂你
微软新作:动态Prompt中间件,用图形界面细化控制上下文,让你的提示更懂你微软研究院最新研究揭示:一种悄然兴起的AI交互模式,正在改变我们与AI对话的方式。这项突破性研究不仅让AI更懂你,还能帮你更好地表达你的需求。
来自主题: AI技术研报
9547 点击 2024-12-09 10:51
微软研究院最新研究揭示:一种悄然兴起的AI交互模式,正在改变我们与AI对话的方式。这项突破性研究不仅让AI更懂你,还能帮你更好地表达你的需求。
面对众多功能独特的AI工具,究竟哪个才是最适合的?本文将带你探索几款顶级的科学研究AI工具:Consensus、SciSpace、Elicit,还有一些正在崛起的黑马,看看谁更胜一筹。

投资界获悉,备受关注的前OpenAI研究与安全副总裁翁荔(Lilian Weng)近日宣布,她正式加入硅谷早期投资机构Fellows Fund的Fellow团队,担任Distinguished Fellow,开启新一段征程。

据英国《金融时报》报道,字节跳动内部人士称,虽然已卸任公司CEO一职,但张一鸣一直在积极参与公司的人工智能(AI)战略,并亲自监督从竞争对手公司招聘中国AI工程师和研究人员。
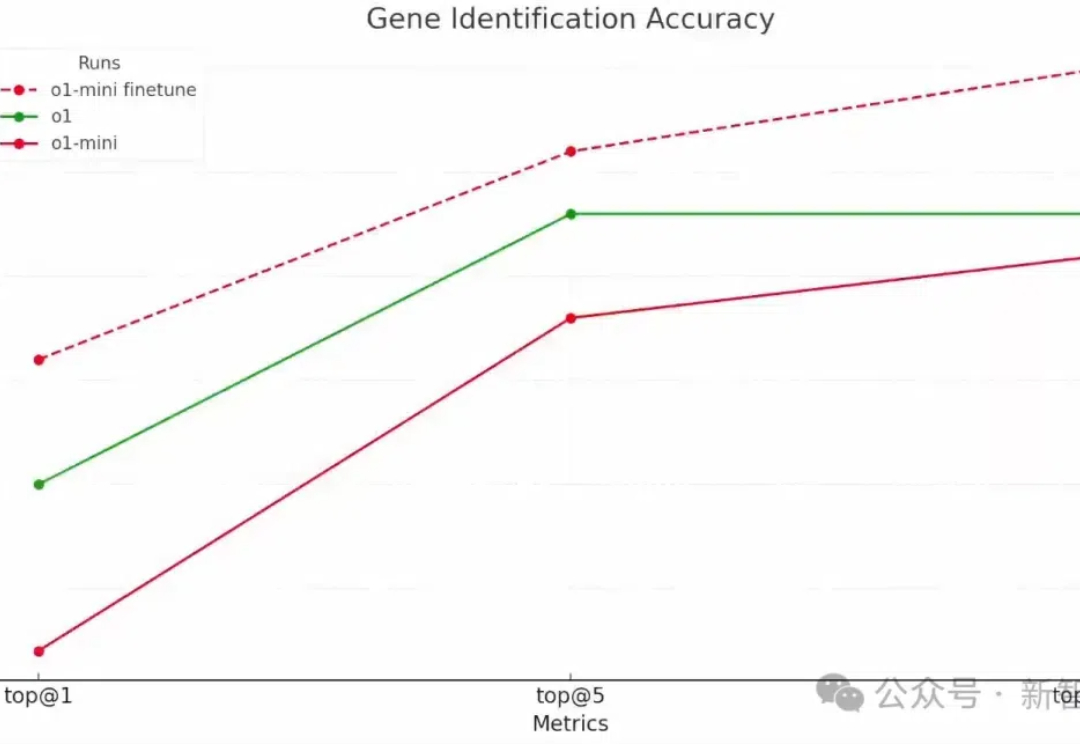
OpenAI第二天的直播,揭示了强化微调的强大威力:强化微调后的o1-mini,竟然全面超越了地表最强基础模型o1。而被奥特曼称为「2024年我最大的惊喜」的技术,技术路线竟和来自字节跳动之前公开发表的强化微调研究思路相同。
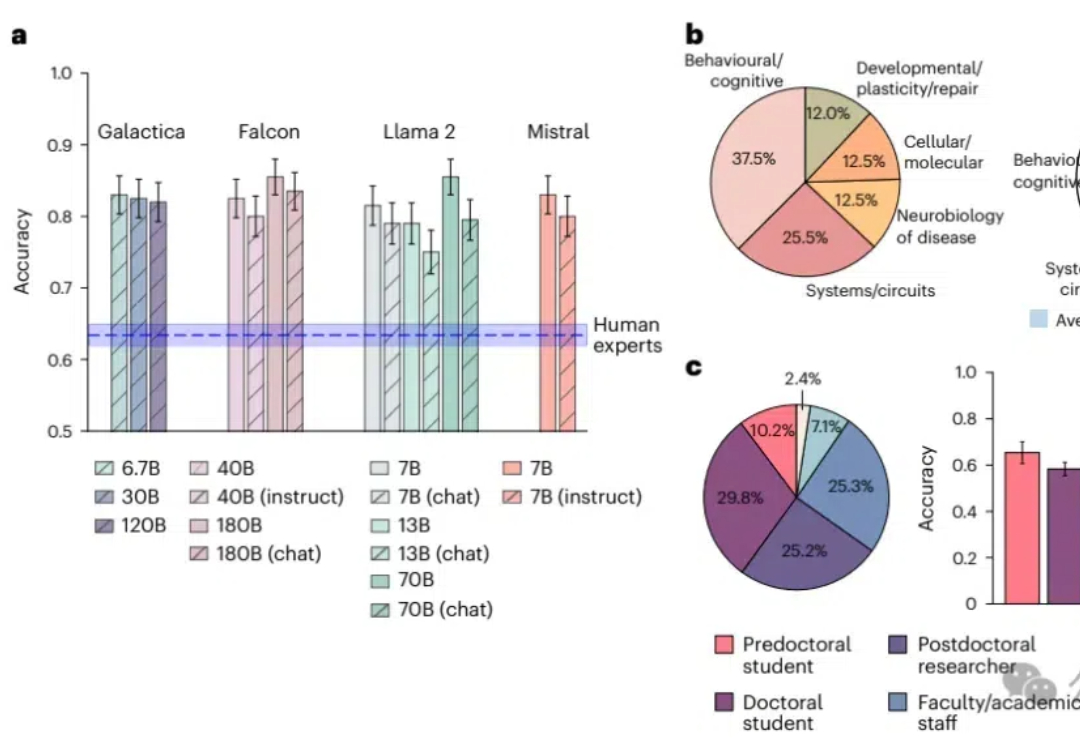
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。
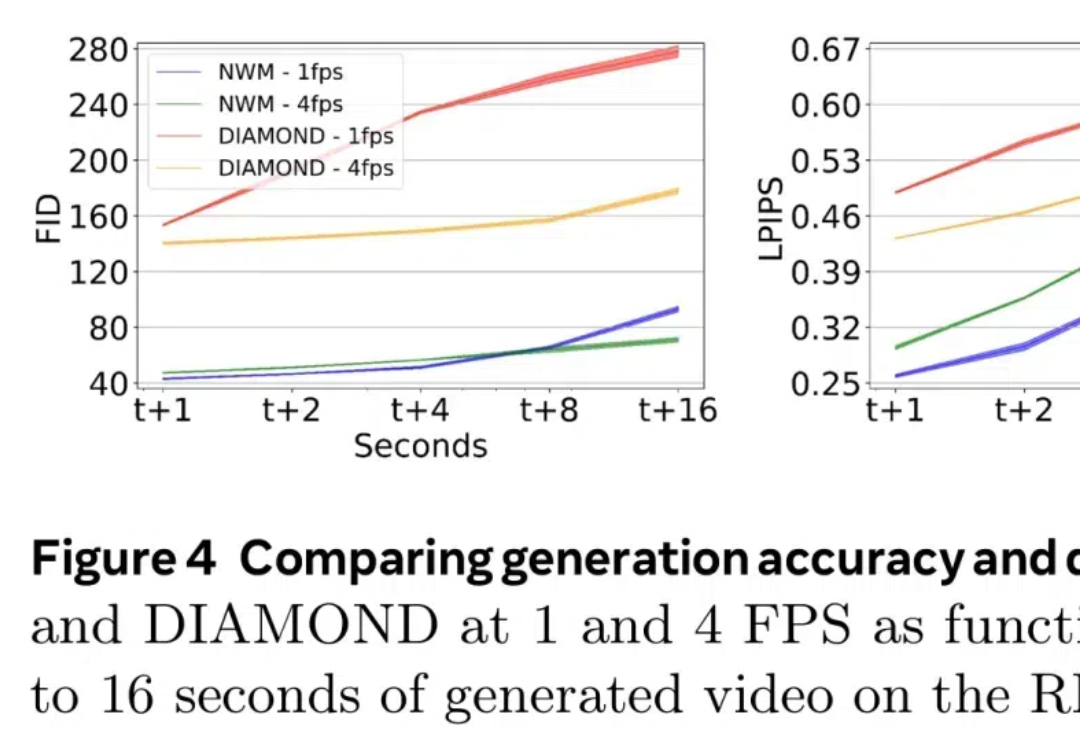
最近,世界模型(World Models)似乎成为了 AI 领域最热门的研究方向。
人类离AGI究竟还有多远?最新一期Nature文章,从以往研究分析、多位大佬言论深入探讨了LLM在智能化道路上突破与局限。

在AI迅速发展的技术背景下,如何更高效地利用模型资源成为了一个关键问题。批处理提示(Batch Prompting)作为一种同时处理多个相似查询的技术,虽然在提高计算效率方面显示出巨大潜力,但同时也面临着性能下降的挑战。香港理工大学的研究团队提出的Auto-Demo提示技术,为这一问题带来了突破性的解决方案。

人工智能工具正在帮助科研人员快速整合和理解大量科学文献,但完全自动化的高质量文献综述生成仍面临挑战,虽然能提升研究效率,但也存在生成低质量综述的风险,需谨慎使用,所以说现阶段还是人眼看论文靠谱。