
速递|微软生成式AI研究负责人加入OpenAI
速递|微软生成式AI研究负责人加入OpenAI微软失去了一位人工智能专家,而 OpenAI 获得了一位,前者的生成 AI 研究副总裁塞巴斯蒂安·布贝克离开了微软,加入了后者。《信息》首次报道了这一消息,路透社也确认了微软的离职情况。
来自主题: AI资讯
4765 点击 2024-10-15 14:03
微软失去了一位人工智能专家,而 OpenAI 获得了一位,前者的生成 AI 研究副总裁塞巴斯蒂安·布贝克离开了微软,加入了后者。《信息》首次报道了这一消息,路透社也确认了微软的离职情况。

别信忽悠,信实测。

前些日子,特工宇宙关注到了一款名为「ResearchFlow」的产品。

随着对现有互联网数据的预训练逐渐成熟,研究的探索空间正由预训练转向后期训练(Post-training),OpenAI o1 的发布正彰显了这一点。
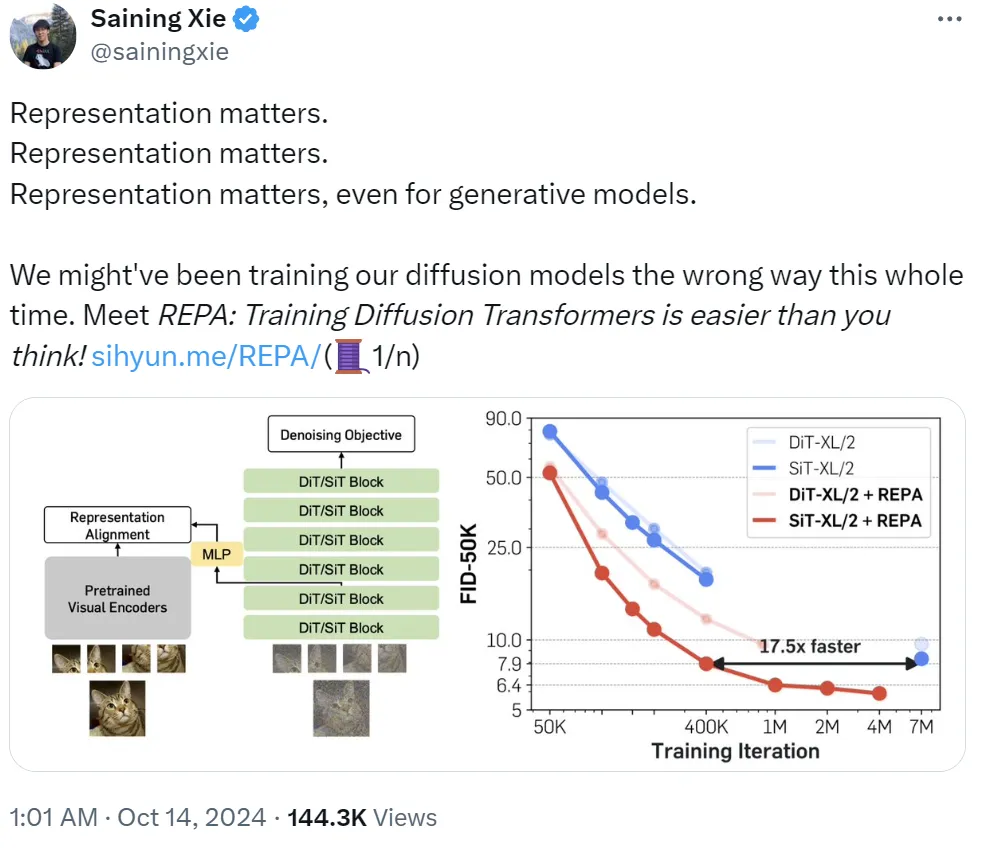
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」
陶哲轩发起的「众包」数学研究项目终于快要迎来胜利时刻!
OpenAI好不容易开源了一次,却被曝出剽窃? 就在昨天,OpenAI应用AI研究员Shyamal Anadkat ,放出了全新多智能体框架——Swarm,瞬间在全网爆火。

三个月前我在硅谷沉浸式泡了两个多月把产品上的整体感受和几个趋势简短写在了这里,在和不同的创业者交流研究了 40 多个产品后,最终回归到了“语音”这个方向,写下“Voice is a big thing”,语音产品是我认为 AI 在 C 端领域的核心变革点。

借助AI工具,研究人员有更多方法来快速筛选总结研究文献,他们又是如何正确/谨慎使用这些AI工具的?

对创意、创新和创造的自由探索