
清华AI找药登Science!一天筛选10万亿次,解决AlphaFold到药物发现的最后一公里
清华AI找药登Science!一天筛选10万亿次,解决AlphaFold到药物发现的最后一公里清华大学智能产业研究院(AIR)联合清华大学生命学院、清华大学化学系在Science上发表论文:《深度对比学习实现基因组级别药物虚拟筛选》。团队研发了一个AI驱动的超高通量药物虚拟筛选平台DrugCLIP。
来自主题: AI资讯
9015 点击 2026-01-09 20:40
清华大学智能产业研究院(AIR)联合清华大学生命学院、清华大学化学系在Science上发表论文:《深度对比学习实现基因组级别药物虚拟筛选》。团队研发了一个AI驱动的超高通量药物虚拟筛选平台DrugCLIP。
在传统企业中,市场调研往往是决策最慢的一环,从问卷设计到洞察输出要花上数周。Dialogue AI试图用AI自动化整个研究流程,让洞察生成的速度与产品迭代保持同步。它的出现不仅是效率的革新,更是企业理解用户方式的范式转变——让研究从被动响应变为实时驱动。

CaveAgent的核心思想很简单:与其让LLM费力地去“读”数据的文本快照,不如给它一个如果不手动重启、变量就永远“活着”的 Jupyter Kernel。这项由香港科技大学(HKUST)领衔的研究,为我们展示了一种“Code as Action, State as Memory”的全新可能性。它解决了所有开发过复杂Agent的工程师最头疼的多轮对话中的“失忆”与“漂移”问题。

新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。

最新报告探讨了生成式模型Nano Banana Pro在低层视觉任务中的表现,如去雾、超分等,传统上依赖PSNR/SSIM等像素级指标。研究发现,Nano Banana Pro在视觉效果上更佳,但传统指标表现欠佳,因生成式模型更追求语义合理而非像素对齐。

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。
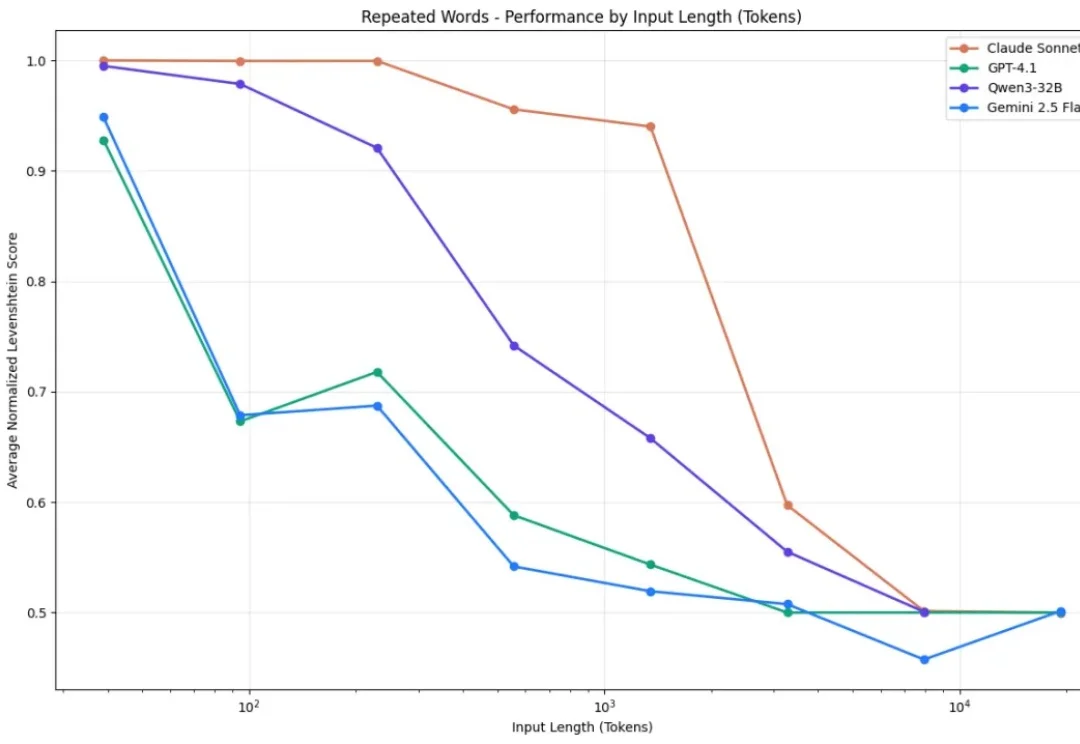
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。

最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。
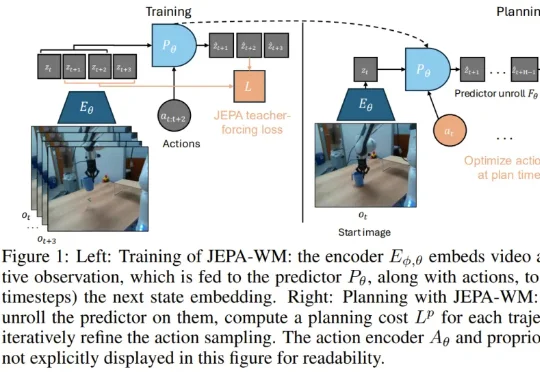
真正的挑战在于,如何在错综复杂的原始视觉输入中提取抽象精髓。这便引出了本研究的主角:JEPA-WM(联合嵌入预测世界模型)。从名字也能看出来,这个模型与 Yann LeCun 的 JEPA(联合嵌入预测架构)紧密相关。事实上也确实如此,并且 Yann LeCun 本人也是该论文的作者之一。