
ECCV 2024 | 一眼临摹:瞥一眼就能模仿笔迹的AI
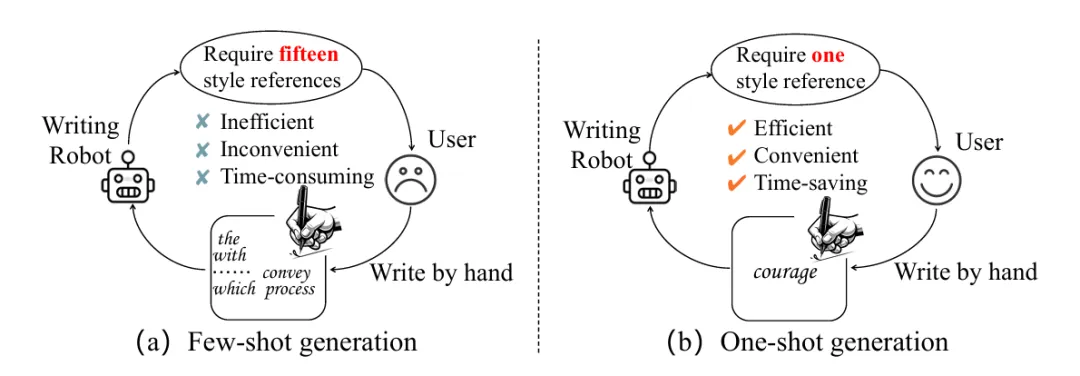
ECCV 2024 | 一眼临摹:瞥一眼就能模仿笔迹的AI来自华南理工大学、新加坡国立大学、昆仑万维以及琶洲实验室的研究者们提出一种新的风格化手写文字生成方法,仅需提供单张参考样本即可临摹用户的书写风格,支持英文,中文和日文三种文字的临摹。
来自主题: AI资讯
11699 点击 2024-09-16 20:40
来自华南理工大学、新加坡国立大学、昆仑万维以及琶洲实验室的研究者们提出一种新的风格化手写文字生成方法,仅需提供单张参考样本即可临摹用户的书写风格,支持英文,中文和日文三种文字的临摹。
o1消息满天飞。

阴谋论的“兔子洞”,被AI破解了!

好羡慕!原来早在8月份,陶哲轩就已经用上了OpenAI o1。

在美国田纳西州东部的山区,一台名为Frontier的破纪录超算为科学家提供了前所未有的机会,让他们得以研究从原子到星系的一切。

随着近年来在文本和视频数据上构建基础模型的进展,学术界对时间序列的基础模型也表现出浓厚的兴趣。 时间序列分析在许多关键领域中具有重要性,能够影响从科学研究到经济决策的广泛应用。
Jiajun Xu : Meta AI科学家,专注大模型和智能眼镜开发。南加州大学博士,Linkedin Top AI Voice,畅销书作家。他的AI科普绘本AI for Babies (“宝宝的人工智能”系列,双语版刚在国内出版) 畅销硅谷,曾获得亚马逊儿童软件、编程新书榜榜首。

本篇综述的作者包括来自复旦大学 CodeWisdom 团队的研究生刘俊伟、王恺欣、陈逸轩和彭鑫教授、娄一翎青年副研究员,以及南洋理工大学的陈震鹏研究员和伊利诺伊大学厄巴纳 - 香槟分校(UIUC)的张令明教授。
这是 AI 智能体在大部分科学研究中超越人类的第一个案例,或许会彻底改变人类与科学文献互动的方式。
近期,来自字节跳动的视频生成模型 Loopy,一经发布就在 X 上引起了广泛的讨论。Loopy 可以仅仅通过一张图片和一段音频生成逼真的肖像视频,对声音中呼吸,叹气,挑眉等细节都能生成的非常自然,让网友直呼哈利波特的魔法也不过如此。