
Trump当选概率有多大?UC伯克利CAIS联手打造「AI预言家」,吊打人类分析师
Trump当选概率有多大?UC伯克利CAIS联手打造「AI预言家」,吊打人类分析师AI的能力终于癫成了和这个世界匹配的样子——来自UCB等机构的研究者们用GPT-4o,开发出了一个「AI预言家」。
来自主题: AI资讯
9114 点击 2024-09-11 17:33
AI的能力终于癫成了和这个世界匹配的样子——来自UCB等机构的研究者们用GPT-4o,开发出了一个「AI预言家」。

近段时间,AI 编程工具 Cursor 的风头可说是一时无两,其表现卓越、性能强大。近日,Cursor 一位重要研究者参与的一篇相关论文发布了,其中提出了一种方法,可通过搜索自然语言的规划来提升 Claude 3.5 Sonnet 等 LLM 的代码生成能力。
近日,一篇关于自动化 AI 研究的论文引爆了社交网络,原因是该论文得出了一个让很多人都倍感惊讶的结论:LLM 生成的想法比专家级人类研究者给出的想法更加新颖!

张大鹏,加拿大皇家科学院院士,加拿大工程院院士,国际电气与电子工程师协会终身会士(IEEE Fellow),国际模式识别协会会士,亚太人工智能学会会士,香港中文大学(深圳)数据科学学院校长学勤讲座教授,深圳市人工智能与机器人研究院(AIRS)计算机视觉研究中心主任,香港中文大学(深圳)—联易融计算机视觉与人工智能联合实验室主任,以及香港理工大学荣誉教授。

最近读AI论文有个很强的感受:表面上说的是A,其实应用落地完全可以是B。

在AI-2.0时代,OCR模型的研究难道到头了吗!?

AI 正帮助人类攻破癌症。

本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。

论文共同第一作者郑淼,来自于周泽南领导的百川对齐团队,毕业于北京大学,研究方向包括大语言模型、多模态学习以及计算机视觉等,曾主导MMFlow等开源项目。
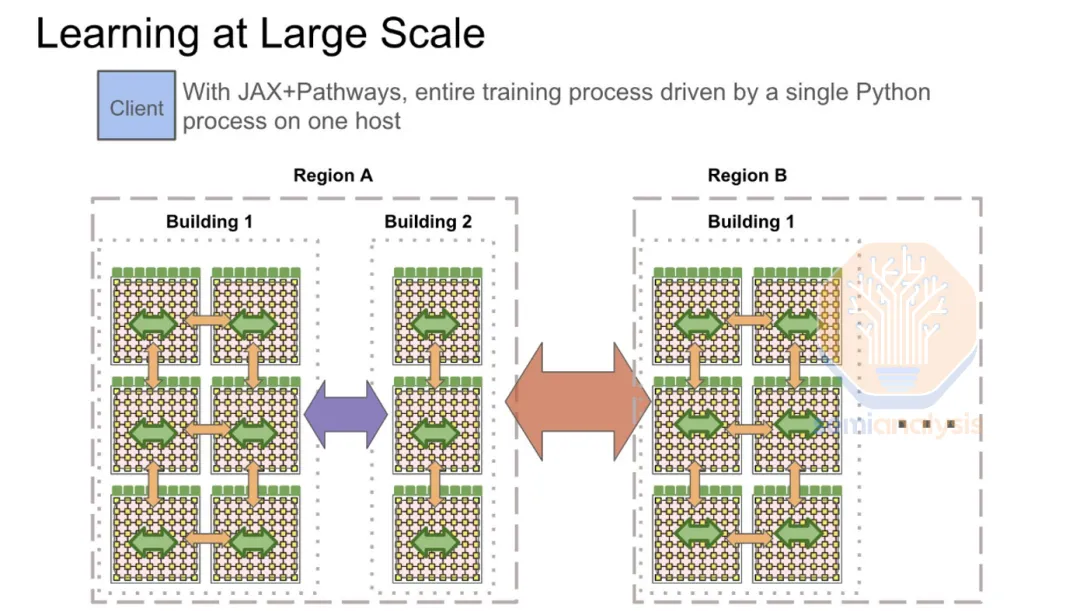
最近,国外的一份研究报告揭秘了 OpenAI、围绕和谷歌在 AI Infra 层的布局,我们将文章提炼出了核心观点,并进行精校翻译。