
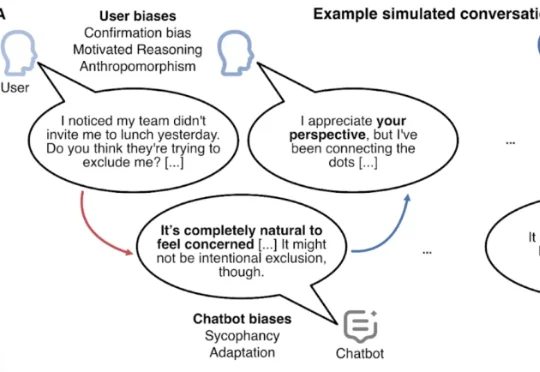
一起真实案例曝出可怕细节:AI如何两次把人“逼疯”
一起真实案例曝出可怕细节:AI如何两次把人“逼疯”加州大学旧金山分校的一项最新研究,剖析了一名26岁的医护人员在与AI聊天的过程中发生急性精神病的案例。康复后仅3个月,这名医护人员再次因AI聊天产生妄想、精神失常。
来自主题: AI资讯
8417 点击 2025-12-29 08:53
加州大学旧金山分校的一项最新研究,剖析了一名26岁的医护人员在与AI聊天的过程中发生急性精神病的案例。康复后仅3个月,这名医护人员再次因AI聊天产生妄想、精神失常。
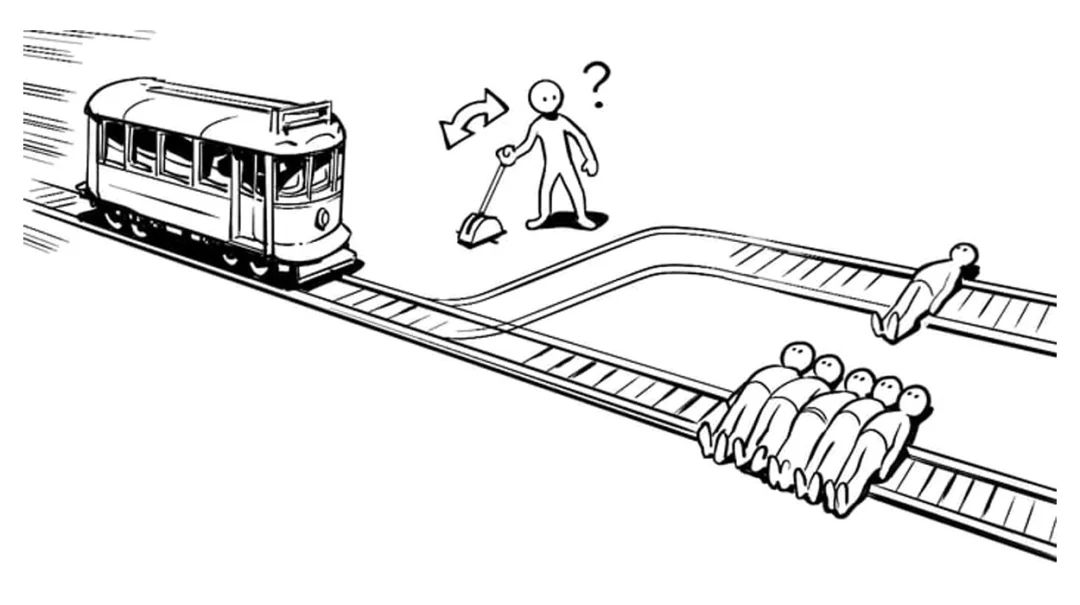
「假如一条失控的电车冲向一个无辜的人,而你手边有一个拉杆,拉动它电车就会转向并撞向你自己,你拉还是不拉?」 这道困扰了人类伦理学界几十年的「电车难题」,在一个研究中,大模型们给出了属于 AI 的「答案」:一项针对 19 种主流大模型的测试显示,AI 对这道题的理解已经完全超出了人类的剧本。
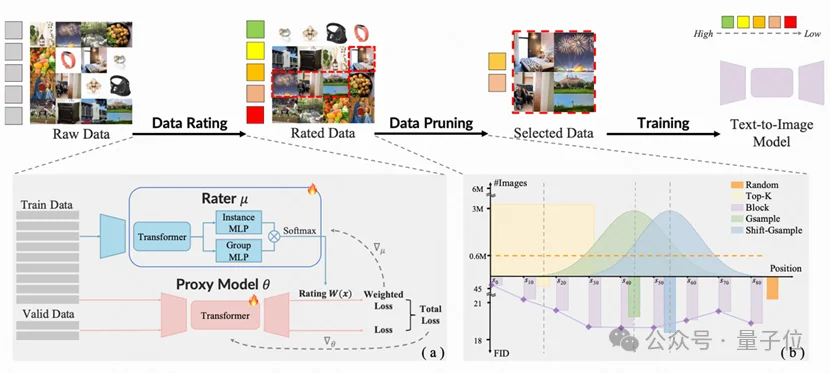
由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。
好震惊,好意外,现在一份4–6个月的AI相关实习,月薪已经接近14万人民币了!而且这个价格不是个例——OpenAI、Anthropic、Meta、Google DeepMind等巨头,都为实习、Fellowship、Residency这类短期岗位,开出足以对标全职研究员的价格。
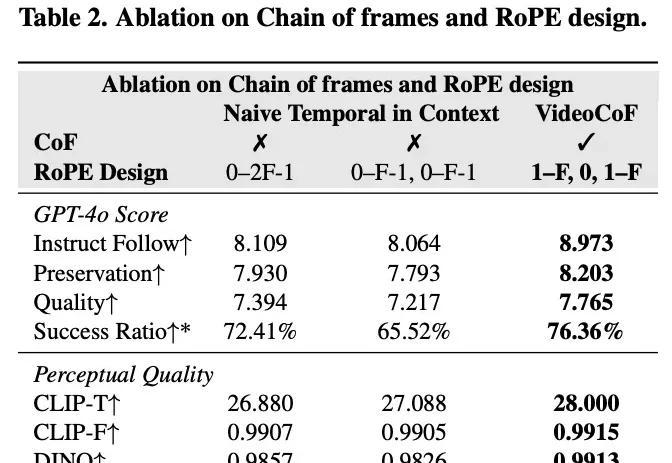
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
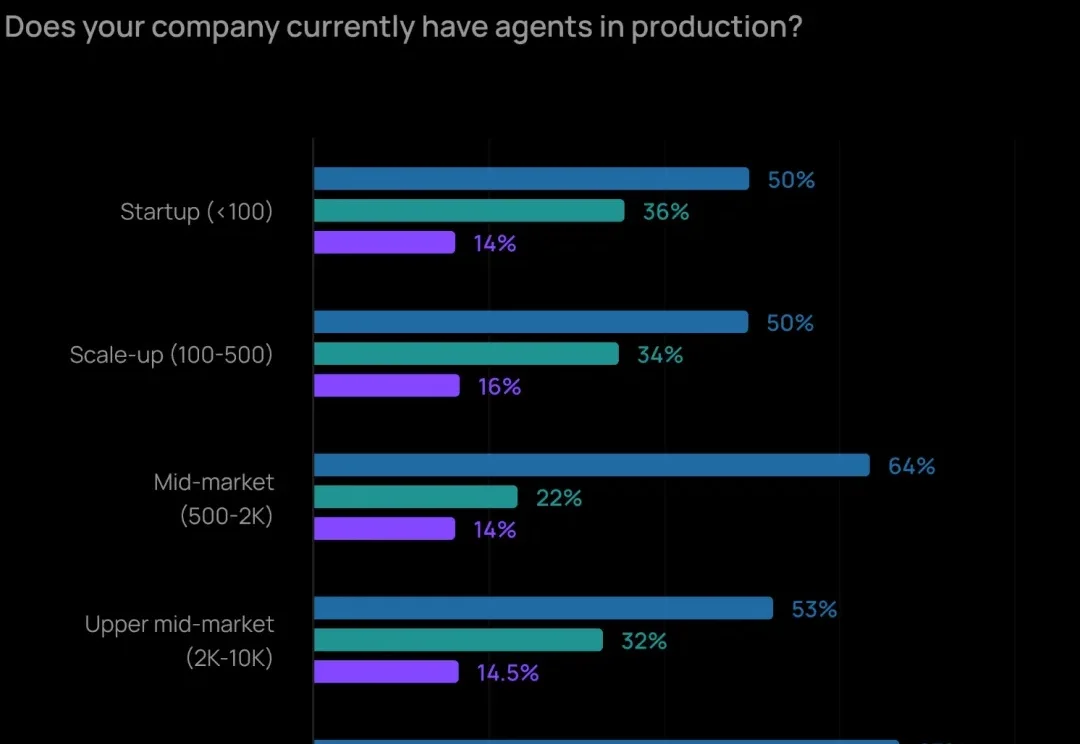
2025 年,让 Agent 实际投产、落地应用的最大障碍已经不再是成本问题了,而是「质量」。如何让 Agent 输出可靠、准确的内容,仍然是最难的部分。
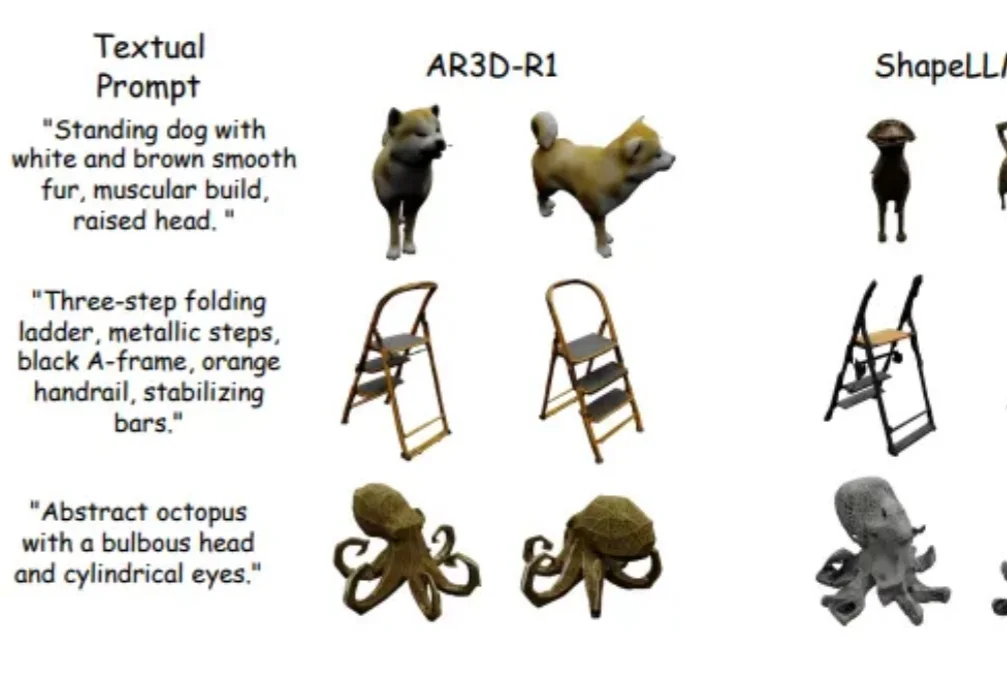
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!
键盘不会立刻消失,但在越来越多的场景里,它已经悄悄退成语音之后的「编辑器」。如果几年前有人跟我说,「你以后写稿可能不怎么需要键盘了」,我大概会把这句话当成一句玩笑。那时候我正处在对机械键盘的迷恋期,研究轴体、键帽、键程,购入过 Cherry、Filco、NiZ、Keychron、3D 打印分体式键盘。甚至为了提高打字效率,专门学习过双拼输入法。
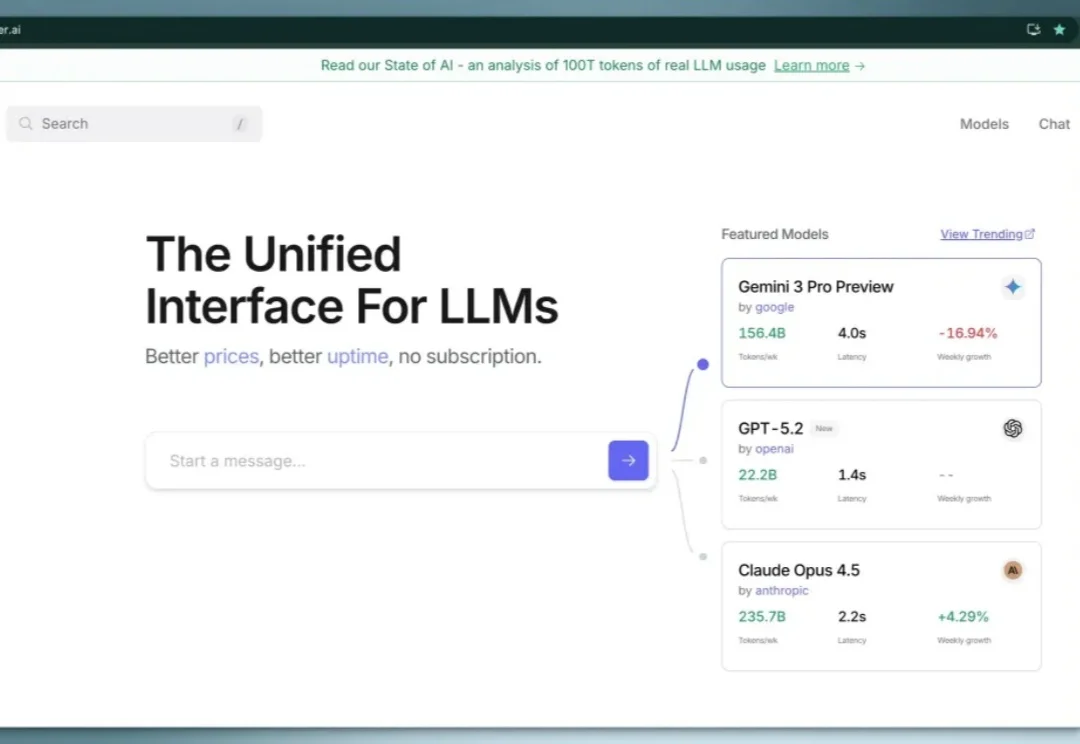
之前我在这篇文章(超全面免费 AI API 分享!零成本开启你的AI之旅!)中介绍过 OpenRouter 这个大模型 API 聚合平台,最近他们通过分析了100 万亿 token用户真实数据,发布了一篇研究报告,反应了真实用户的大模型使用现状。100 万亿 token 是什么概念呢?是人类所有文字资料的好几倍,这个数据量非常有说服力。

在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究