
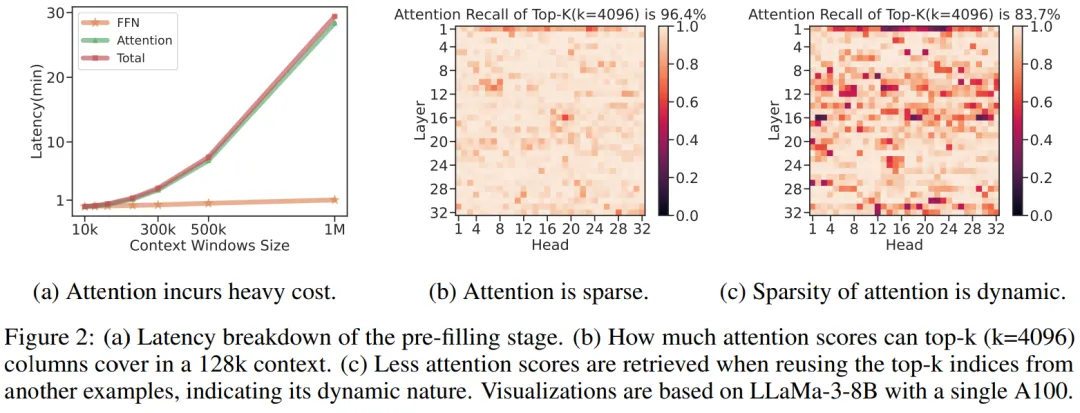
单卡A100实现百万token推理,速度快10倍,这是微软官方的大模型推理加速
单卡A100实现百万token推理,速度快10倍,这是微软官方的大模型推理加速微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。
来自主题: AI技术研报
7788 点击 2024-07-09 17:24
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。

科学家们一直致力于让机器人更敏捷,此次哈佛大学与谷歌DeepMind人工智能实验室的合作有了新突破。他们创造出了一只搭载了AI大脑的「虚拟大鼠」,能够模仿真实啮齿动物的所有动作,甚至做出了一些没有被明确训练过的「新奇行为」。此项研究有望开辟「虚拟神经科学」新领域,对于脑科学和机器人学意义重大。
下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。

超越Transformer和Mamba的新架构,刚刚诞生了。斯坦福UCSD等机构研究者提出的TTT方法,直接替代了注意力机制,语言模型方法从此或将彻底改变。

AI全流程赋能制造业三大环节,实现生产效率和产品竞争力的突破

6月,IEEE刊登了一篇对ChatGPT代码生成任务进行系统评估的论文,数据集就是程序员们最爱的LeetCode题库。研究揭示了LLM在代码任务中出现的潜在问题和能力局限,让我们能够对模型做出进一步改进,并逐渐了解使用ChatGPT写代码的最佳姿势。

冲锋在AI辅助数学研究第一线的陶哲轩,近日又有「神总结」:ChatGPT提升的,是我们在编码、图表等次要任务上的能力;而真要搞好数学研究,基础不扎实的话,AI也是没用的。

给大模型加上第三种记忆格式,把宝贵的参数从死记硬背知识中解放出来!

瑞士苏黎世联邦理工学院的研究者发现,为ChatGPT等聊天机器人提供支持的大型语言模型可以从看似无害的对话中,准确推断出数量惊人的用户个人信息,包括他们的种族、位置、职业等。

近日,来自谷歌DeepMind的研究人员,推出了专门用于评估大语言模型时间推理能力的基准测试——Test of Time(ToT),从两个独立的维度分别考察了LLM的时间理解和算术能力。