

GPT-4o竟是「道德专家」?解答50道难题,比纽约大学教授更受欢迎
GPT-4o竟是「道德专家」?解答50道难题,比纽约大学教授更受欢迎大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。
来自主题: AI技术研报
10126 点击 2024-07-05 16:30
大语言模型有道德推理能力吗?不仅有,甚至可能在道德推理方面超越普通人和专家学者!最新研究发现:GPT-4o针对道德难题给出的建议比人类专家更让人信服。

荷兰拉德布德大学的研究团队通过定位大脑注意力机制,在AI「读心术」领域精确生成图像,能够依据大脑活动记录极为准确地重建猕猴所看到的内容。网友:这是人机融合的最终目标。

大模型当上福尔摩斯,学会对视频异常进行检测了。 来自华中科技大学、百度、密歇根大学的研究团队,提出了一种可解释性的视频异常检测框架,名为Holmes-VAD。
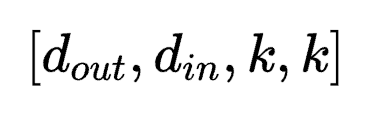
为了让大模型在特定任务、场景下发挥更大作用,LoRA这样能够平衡性能和算力资源的方法正在受到研究者们的青睐。
吃个瓜而已,AI居然写了份研究报告??

Meta的GenAI团队在最新研究中介绍了Meta 3D Gen模型:可以在不到1分钟的时间内从文本直接端到端生成3D资产。

「忙碌海狸」难题困扰了计算机科学家40多年。如今,来自全球各地20+业余开发者和数学家们,终于取得了突破性进展。他们抓到了第五只忙碌海狸——用Coq辅助证明,得到答案47176870。对此陶哲轩激动地表示,这再次体现了证明助手对数学研究协作的重要性。

神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例
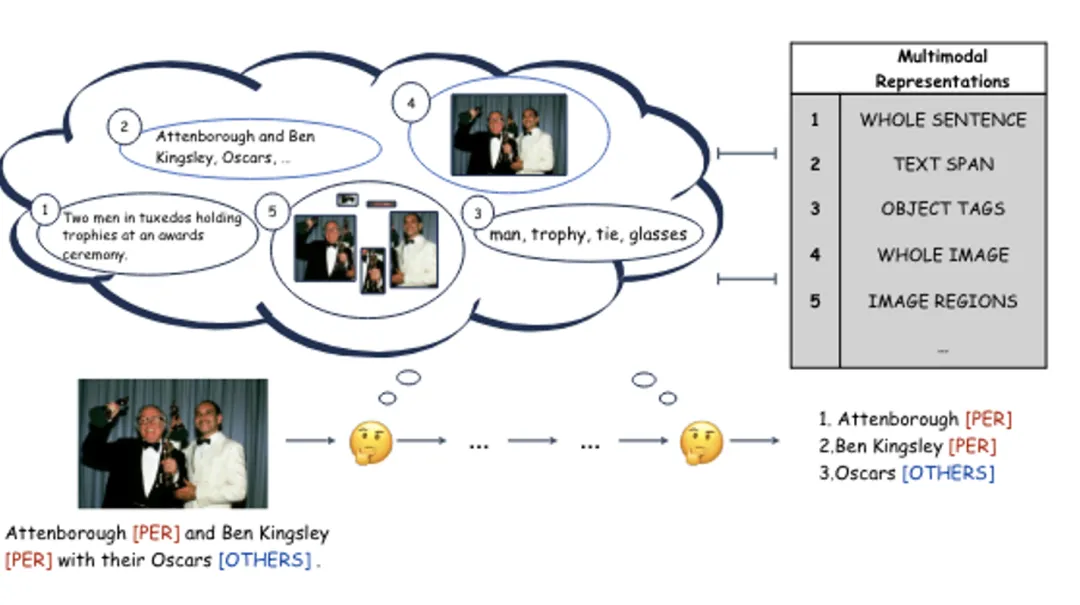
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。