
万字综述大模型高效推理:无问芯穹与清华、上交最新联合研究全面解析大模型推理优化
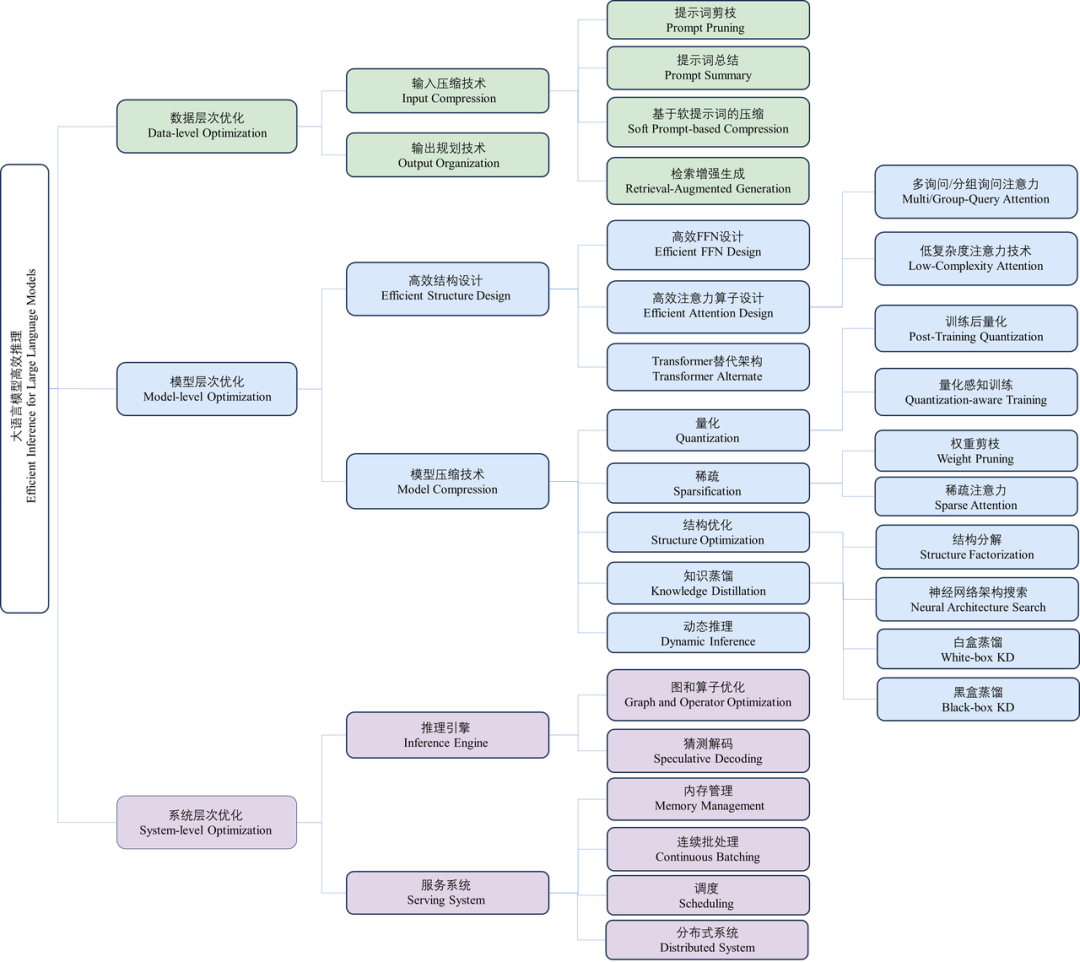
万字综述大模型高效推理:无问芯穹与清华、上交最新联合研究全面解析大模型推理优化近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。
来自主题: AI技术研报
11243 点击 2024-06-14 10:35








