

next-token被淘汰!Meta实测「多token」训练方法,推理提速3倍,性能大涨10%+
next-token被淘汰!Meta实测「多token」训练方法,推理提速3倍,性能大涨10%+研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。
来自主题: AI技术研报
9673 点击 2024-06-03 11:00
研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。

在以英语为主的语料库上训练的多语言LLM,是否使用英语作为内部语言?对此,来自EPFL的研究人员针对Llama 2家族进行了一系列实验。

深度学习领域知名研究者、Lightning AI 的首席人工智能教育者 Sebastian Raschka 对 AI 大模型有着深刻的洞察,也会经常把一些观察的结果写成博客。在一篇 5 月中发布的博客中,他盘点分析了 4 月份发布的四个主要新模型:Mixtral、Meta AI 的 Llama 3、微软的 Phi-3 和苹果的 OpenELM。

最近的一系列研究表明,纯解码器生成模型可以通过训练利用下一个 token 预测生成有用的表征,从而成功地生成多种模态(如音频、图像或状态 - 动作序列)的新序列,从文本、蛋白质、音频到图像,甚至是状态序列。

John Schulman 是 OpenAI 联合创始人、研究科学家(OpenAI 现存最主要具有技术背景的创始人),他领导了 ChatGPT 项目,在 OpenAI 内部长期负责模型 post-traning,在 Ilya 和 Jan Leike 离开 OpenAI 后,下一代模型安全性风险相关的研究也会由 John Schulman 来接替负责。

通过视觉信息识别、理解人群的行为是视频监测、交互机器人、自动驾驶等领域的关键技术之一,但获取大规模的人群行为标注数据成为了相关研究的发展瓶颈。如今,合成数据集正成为一种新兴的,用于替代现实世界数据的方法,但已有研究中的合成数据集主要聚焦于人体姿态与形状的估计。它们往往只提供单个人物的合成动画视频,而这并不适用于人群的视频识别任务。
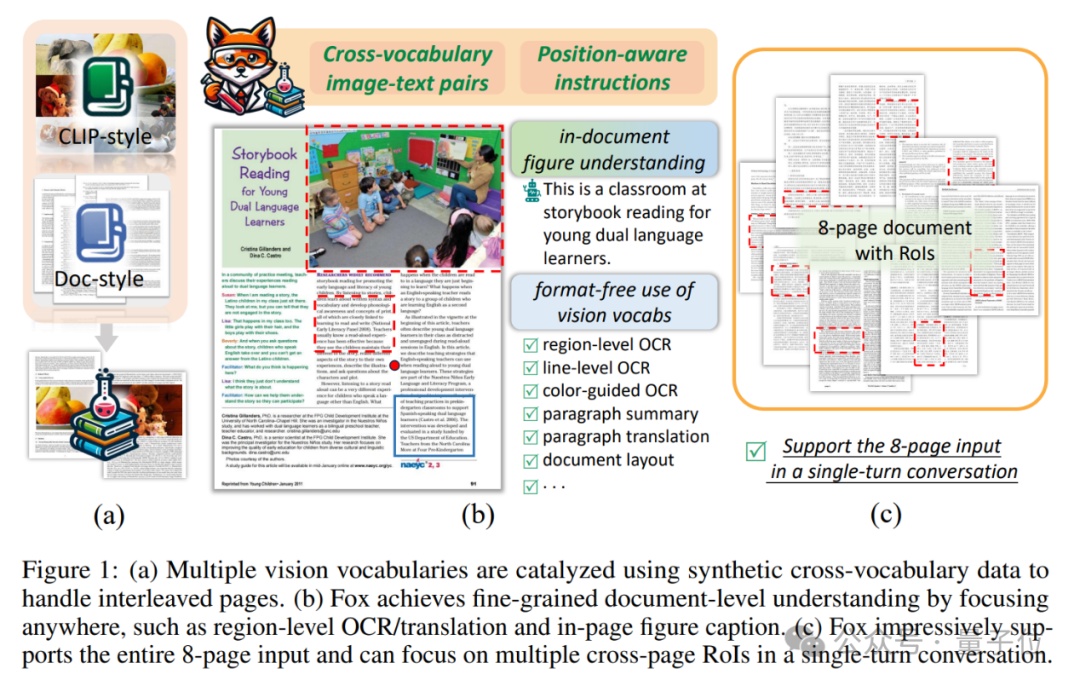
虽然多模态大模型都能挑西瓜了,但理解复杂文档方面还是差点意思。

刚刚,谷歌DeepMind、JHU、牛津等发布研究,证实GPT-4的心智理论已经完全达到成年人类水平,在更复杂的第6阶推理上,更是大幅超越人类!此前已经证实,GPT-4比人类更能理解语言中的讽刺和暗示。在心智理论上,人类是彻底被LLM甩在后面了。

清华类脑计算研究中心施路平团队新成果,登上最新一期Nature封面。

谁能想到,某天和你聊天的那个人竟是一个AI。来自TUM等研究人员提出了一种全新算法NPGA,能够生成高保真3D头像,表情逼真到让你怀疑自己的眼睛。