

每天都看模型评分,但你真的了解吗?OpenAI研究员最新博客,一文读懂LLM评估
每天都看模型评分,但你真的了解吗?OpenAI研究员最新博客,一文读懂LLM评估在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。
来自主题: AI技术研报
11230 点击 2024-05-30 15:32
在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。

时隔3年,清华团队的研究再次登上Nature封面。刚刚,世界首个类脑互补视觉芯片Tianmouc重磅发布,灵感来源于人类视觉系统。它能以极低带宽和功耗采集图像信息,突破了传统的视觉感知挑战,自如应对开放世界中极端场景难题。
OpenAI 开始训练下一个前沿模型了。在联合创始人、首席科学家 Ilya Sutskever 官宣离职、超级对齐团队被解散之后,OpenAI 研究的安全性一直备受质疑。
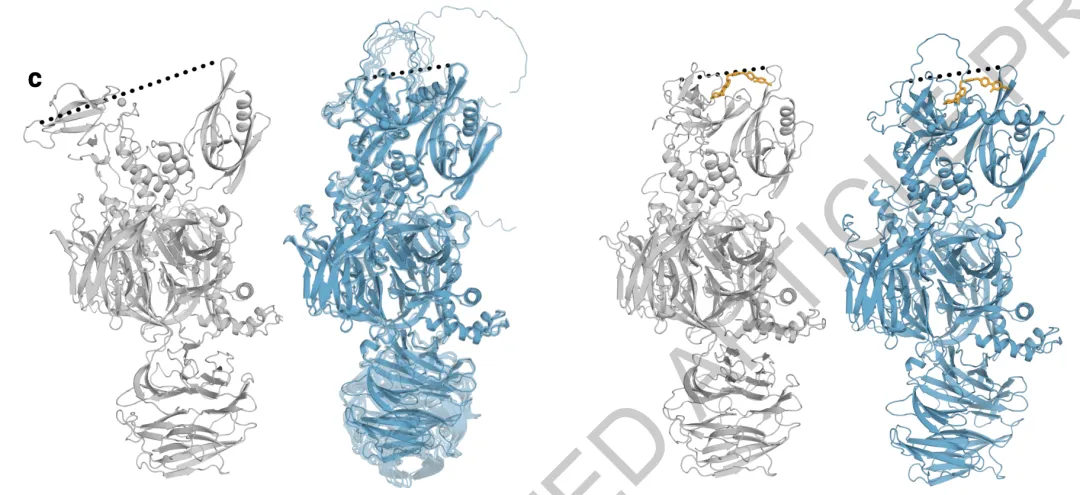
世界是变化的,分子是运动的,从预测静态单一结构走向动态构象分布是揭示蛋白质等生物分子功能的重要一步。探索蛋白质的构象分布,能帮助理解蛋白质与其他分子相互作用的生物过程;识别蛋白质表面下的潜在药物位点,描绘各个亚稳态之间的过渡路径,有助于研究人员设计出具有更强特异性和效力的目标抑制剂和治疗药物。但传统的分子动力学模拟方法昂贵且耗时,难以跨越长的时间尺度,从而观察到重要的生物过程。

斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。

3D生成也有自个儿的人工评测竞技场了~ 来自复旦大学和上海AI lab的研究人员搞了个3DGen-Arena,和大语言模型的Chatbot-Arena、GenAI-Arena等一脉相承,要让大伙儿对3D生成模型来一场公开、匿名的评测

更适配中文的语音大模型来了—— 来自中国电信人工智能研究院,AI领域Fellow大满贯科学家李学龙带队,发布首个能听懂30多种多方言混说的大模型。 号称最难方言、“魔鬼的语言”的温州话,也不在话下。

为什么是OpenAI首先开发出像GPT-4这样强大的模型?联合创始人Greg在接受采访时透露,团队中不仅仅有学术背景的研究型人才,同时还有优秀的工程人才,这使得他们能够从不同的角度解决问题,更有效地推动项目进步。

中国AI资源要靠储备,更要靠开放的生态。
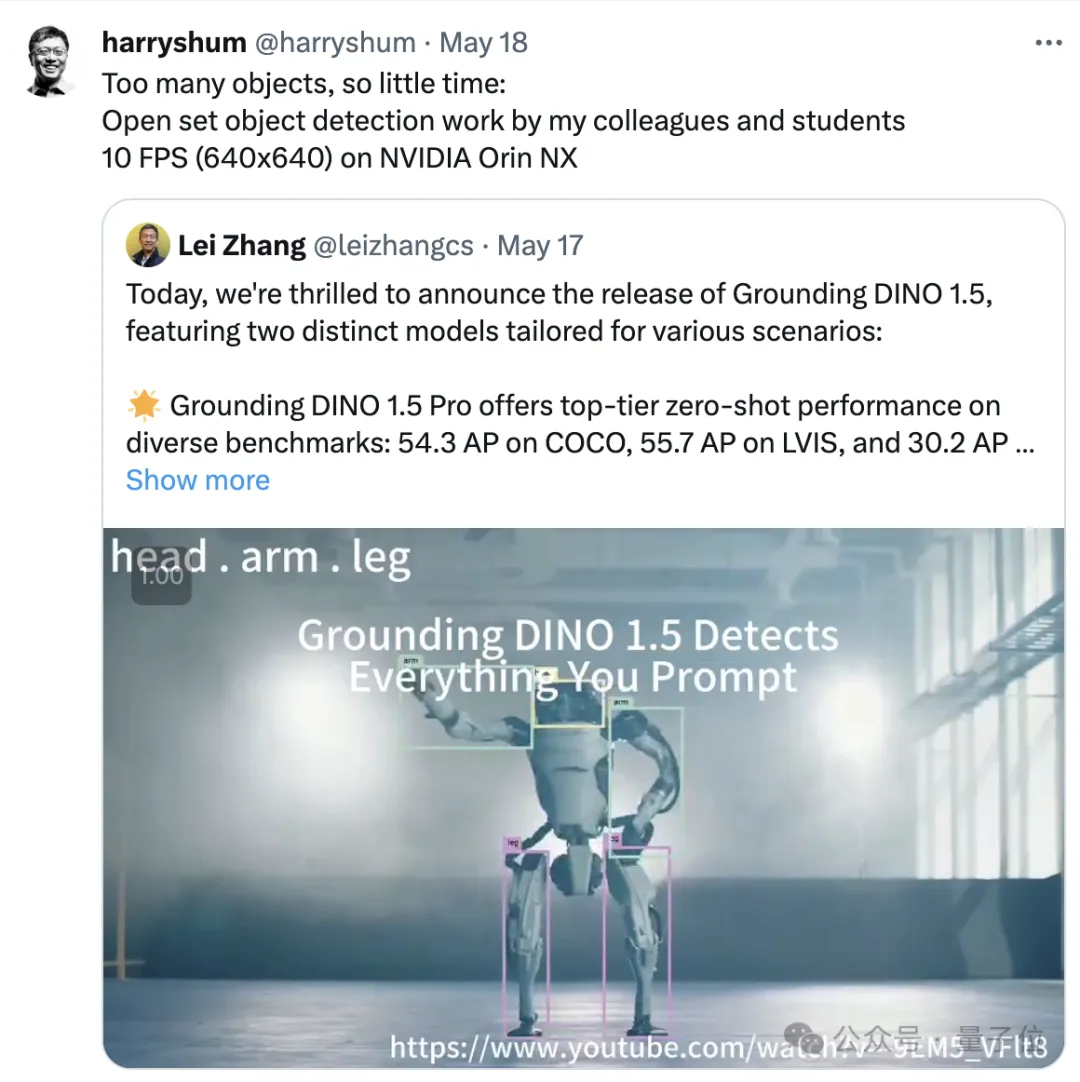
目标检测领域,迎来了新进展—— Grounding DINO 1.5,IDEA研究院团队出品,在端侧就可实现实时识别。