

复刻Sora的通用视频生成能力,开源多智能体框架Mora来了
复刻Sora的通用视频生成能力,开源多智能体框架Mora来了自理海大学、微软研究院的研究者提出了一种多智能体框架 Mora,该框架整合了几种先进的视觉 AI 智能体,以复制 Sora 所展示的通用视频生成能力。
来自主题: AI技术研报
5431 点击 2024-03-23 21:22
自理海大学、微软研究院的研究者提出了一种多智能体框架 Mora,该框架整合了几种先进的视觉 AI 智能体,以复制 Sora 所展示的通用视频生成能力。

斯坦福的一篇案例研究表示,提交给AI会议的同行评审文本中,有6.5%到16.9%可能是由LLM大幅修改的,而这些趋势可能在个体级别上难以察觉。

升级洪水预警系统,每年可以挽救数千人的生命!谷歌最新研究登上Nature。洪水是最常见的自然灾害类型,全球有近 15 亿人(约占世界人口的 19%)直接面临严重洪水事件的巨大风险。洪水还造成巨大的物质损失,每年造成全球经济损失约 500 亿美元。

最新消息,Stable Diffusion核心研究团队已集体辞职!名单包括研究团队领导、论文一作Robin Rombach,共同一作Andreas Blattmann,以及另一位作者Dominik Lorenz。

简笔素描一键变身多风格画作,还能添加额外的描述,这在 CMU、Adobe 联合推出的一项研究中实现了。作者之一为 CMU 助理教授朱俊彦,其团队在 ICCV 2021 会议上发表过一项类似的研究:仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。

一直以来,我都习惯于用各种各样的外部工具辅助自己的科研全过程。从论文阅读、文献查找、公式理解,再到论文润色,AI工具都能在不同程度地帮上我。
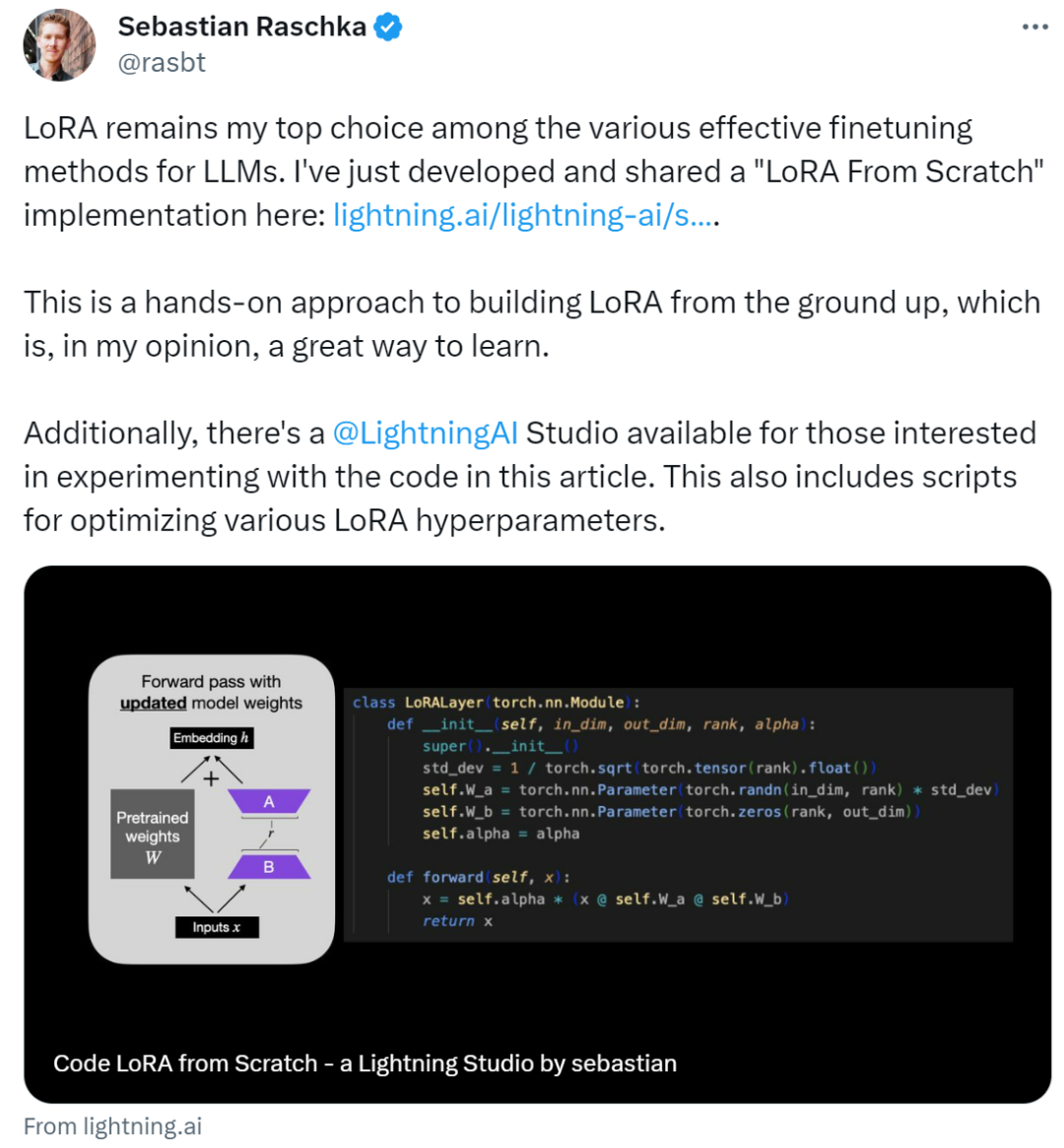
作者表示:在各种有效的 LLM 微调方法中,LoRA 仍然是他的首选。LoRA(Low-Rank Adaptation)作为一种用于微调 LLM(大语言模型)的流行技术,最初由来自微软的研究人员在论文《 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 》中提出。

【新智元导读】利用文本生成图片(Text-to-Image, T2I)已经满足不了人们的需要了,近期研究在T2I模型的基础上引入了更多类型的条件来生成图像,本文对这些方法进行了总结综述。

为了应对 AI 发展带来的挑战,国内外研究者展开合作以避免其可能带来的灾难的发生。

深度学习模型因其能够从大量数据中学习潜在关系的能力而「彻底改变了科学研究领域」。然而,纯粹依赖数据驱动的模型逐渐暴露出其局限性,如过度依赖数据、泛化能力受限以及与物理现实的一致性问题。