

19岁辍学少年拿下260万美元:让谷歌AI负责人都抢着投资的秘密
19岁辍学少年拿下260万美元:让谷歌AI负责人都抢着投资的秘密我深入研究了 Supermemory 的技术方案后,发现它和市面上其他记忆解决方案有本质区别。大多数所谓的"记忆"系统,本质上只是一个数据库,提供基本的增删改查功能。你可以保存一个实体,给它设定用户范围,然后查询出来。这很有用,但这只是基础功能,任何数据库都能做到。
来自主题: AI资讯
8252 点击 2025-11-03 15:31
我深入研究了 Supermemory 的技术方案后,发现它和市面上其他记忆解决方案有本质区别。大多数所谓的"记忆"系统,本质上只是一个数据库,提供基本的增删改查功能。你可以保存一个实体,给它设定用户范围,然后查询出来。这很有用,但这只是基础功能,任何数据库都能做到。

当你发现自己刷到的视频、帖子是「AI制造」时,当身边的人用一种「AI腔调」和你说话时,你是不是想要迅速滑走,或者直接拉黑?加州大学伯克利分校等机构的权威研究证实,AI正在改变我们的说话、写作等交流方式,让我们的交际「塑料感」十足。

每周我们都会和不少AI公司创业者交流,体验和评测新的AI产品,以各种方式去研究这些项目。
一个研究者一天到底要读多少篇论文才能跟上最新趋势?在 AI 研究成果爆炸的今天,这个数字变得越来越模糊。人的阅读速度,早就跟不上 AI 科研地图扩展的速度了。
在大数据和大模型推动下,微调技术凭借成本低、效率高优势,成为应对小样本、长尾目标等复杂场景的利器。从早期全参数微调到参数高效微调(PEFT),再到如今融合多种PEFT技术的混合微调,遥感微调技术不断进化。清华大学等团队在CVMJ期刊上系统梳理了技术脉络,并指出了九个潜在研究方向,助力遥感技术在农业监测、天气预报等关键领域发挥更大作用。
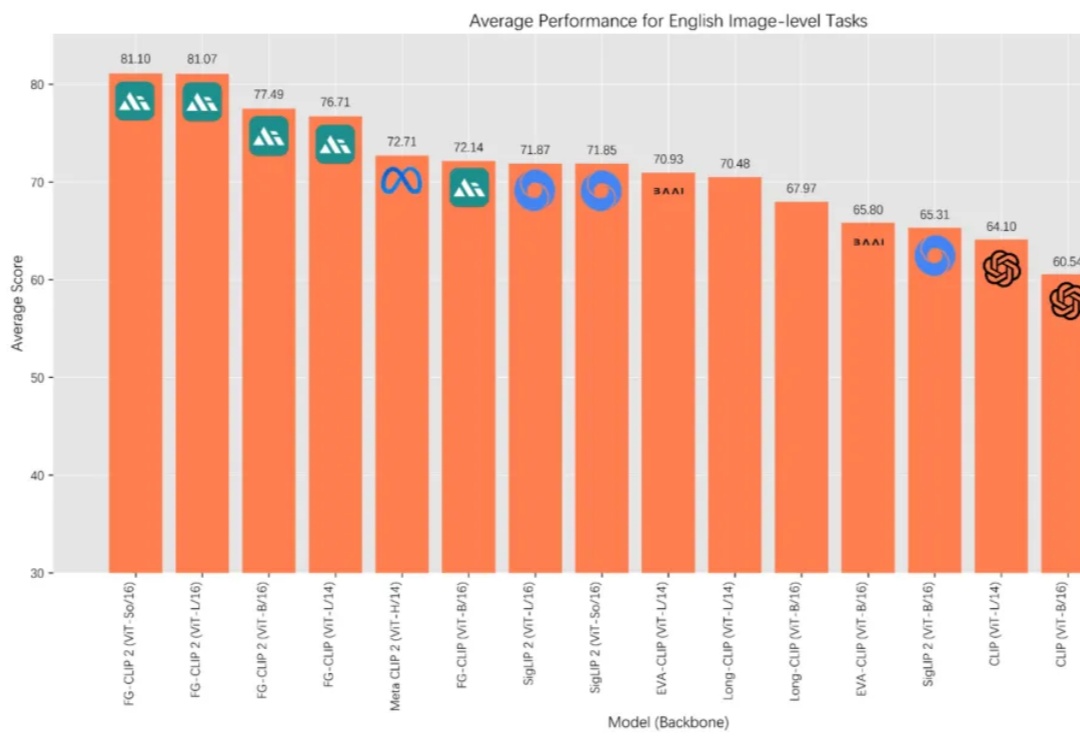
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。

Meta首席执行官马克·扎克伯格近日批准了一项涉及约600名员工的AI部门裁员计划,这是Meta今年在人工智能领域规模最大的一次调整,主要波及公司核心研发机构。在此消息公布后,田渊栋首次公开露面,接受了腾讯科技特约作者「课代表立正」的独家深度访谈。

在AI加持下的这一年人类突飞猛进,停下来回头看去,似乎AI已经无所不能,但前OpenAI灵魂研究员认为AI不可能瞬间超越人类,他还提出了三个关于AI的最新洞见。所有能被验证的任务,最终都会被AI解决 智能最后会变成商品,知识价格归零 AI不会瞬间超过人类

当医生按下Enter键,AI就能决定人的生死!美国华盛顿大学,一项名为「AI代理人」的研究,试图让算法预测昏迷患者的生死意愿。支持者说这是医疗新纪元,反对者担心它只是复制偏见的机器。当AI学会理解生命,人类的怜悯、犹豫与责任,会不会被一串数据取代?

科技行业全球10万大裁员,连10年老将田渊栋都被Meta裁掉了!昨天,南洋理工大学的副教授Boyang Li吊足了大家的胃口:Meta FAIR最近的事件很抓马,但工业研究为什么这么难?我想知道大家愿不愿意听一下我的观点。