

世界模型有了开源基座Emu3.5!拿下多模态SOTA,性能超越Nano Banana
世界模型有了开源基座Emu3.5!拿下多模态SOTA,性能超越Nano Banana最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
来自主题: AI资讯
8040 点击 2025-11-01 09:36
最新最强的开源原生多模态世界模型—— 北京智源人工智能研究院(BAAI)的悟界·Emu3.5来炸场了。 图、文、视频任务一网打尽,不仅能画图改图,还能生成图文教程,视频任务更是增加了物理真实性。
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。
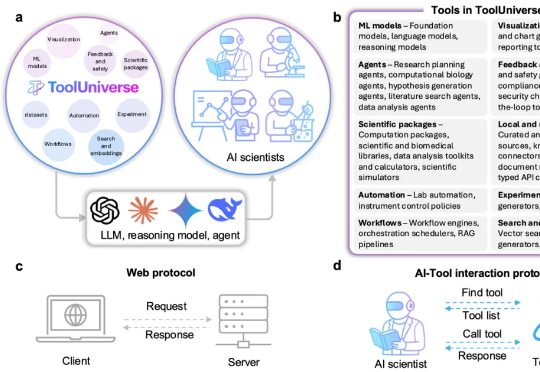
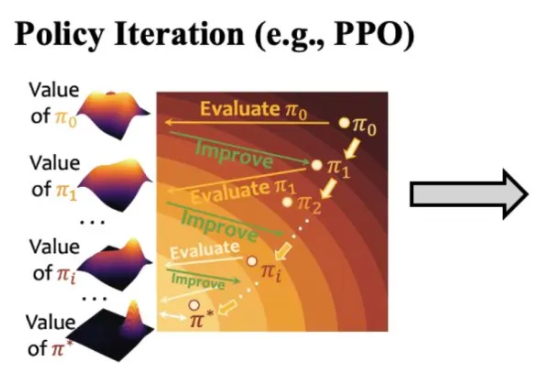
近日,OpenAI 宣称要在 2028 年实现让 AI 完全自主做研究,一下子又把焦点聚在了AI 科学家。 过去,AI 只是作为“助理”辅助研究者们进行科学研究。现在,美国哈佛大学与美国麻省理工学院联

刚刚,OpenAI推出了使用GPT-5寻找和修复安全漏洞的智能体Aardvark。目前,Aardvark还处于beta测试阶段。OpenAI称,Aardvark开创了「防御者优先」的新范式:作为自主安全研究智能体,随代码不断演化,为团队提供持续保护(continuous protection)。

AI已经不止会写代码、画图、做PPT,它也开始「上班」了!CMU与斯坦福的研究团队首次完整追踪了AI的工作过程,发现一个惊人事实:它并不是在模仿人类,而是在用编程的方式重写工作的定义。这场关于「谁在工作」的实验,正在重构未来职场的逻辑。
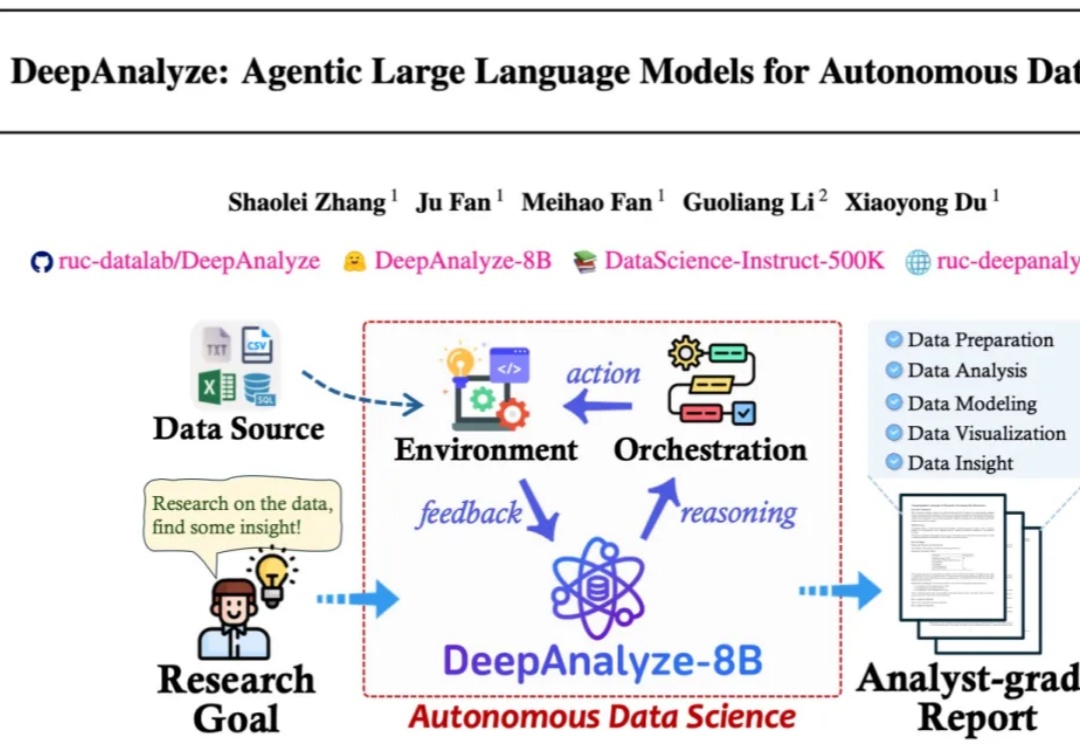
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
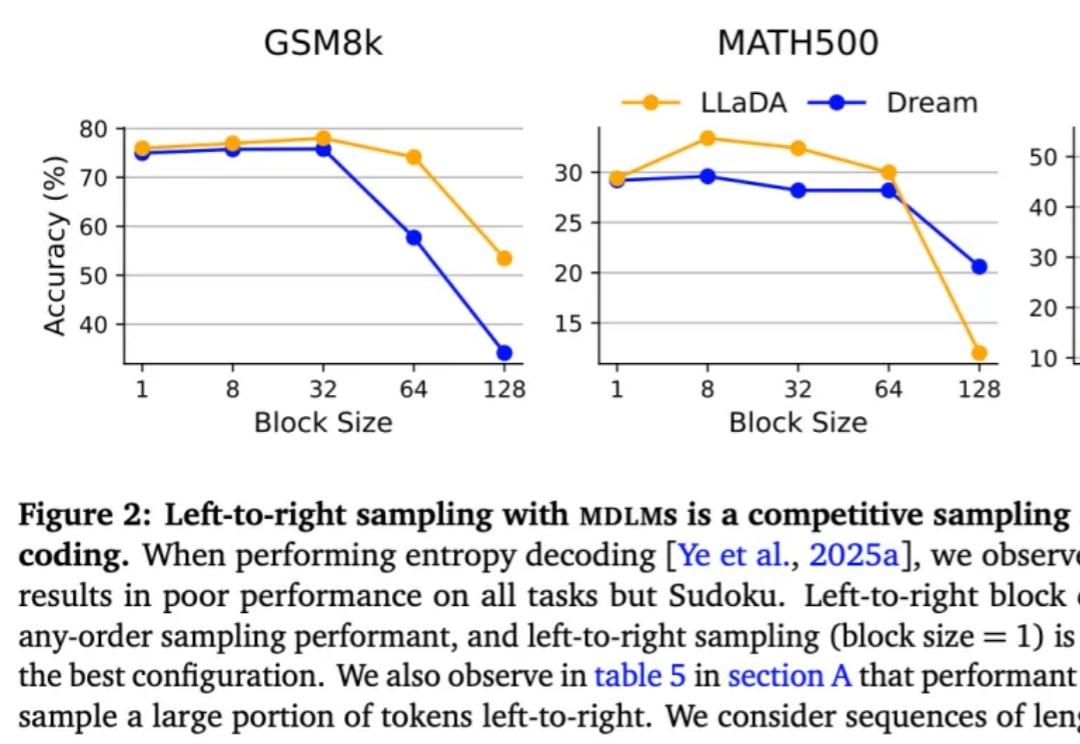
按从左到右的顺序依次生成下一个 token 真的是大模型生成方式的最优解吗?最近,越来越多的研究者对此提出质疑。其中,有些研究者已经转向一个新的方向 —— 掩码扩散语言模型(MDLM)。
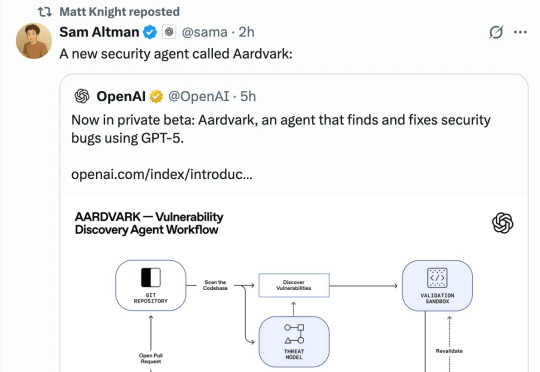
AI Coding火了大半年,AI Debugging也来了!刚刚,OpenAI发布由GPT-5驱动的“白帽”Agent——Aardvark(土豚)。这只“AI安全研究员”能帮助开发者和安全团队,在大规模代码库中自动发现并修复安全漏洞。

今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 —— 悟界・Emu3.5。这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 “多模态世界大模型”(Multimodal World Foudation Model)。