
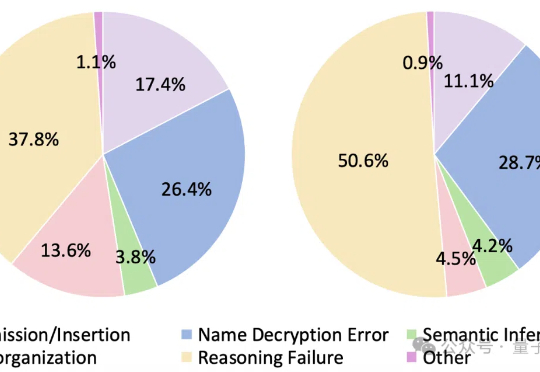
SOTA大模型遇上加密数据评测:Qwen3未破10%,o1也栽了丨上海AI Lab等联合研究
SOTA大模型遇上加密数据评测:Qwen3未破10%,o1也栽了丨上海AI Lab等联合研究大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
来自主题: AI技术研报
8680 点击 2025-05-29 14:59
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
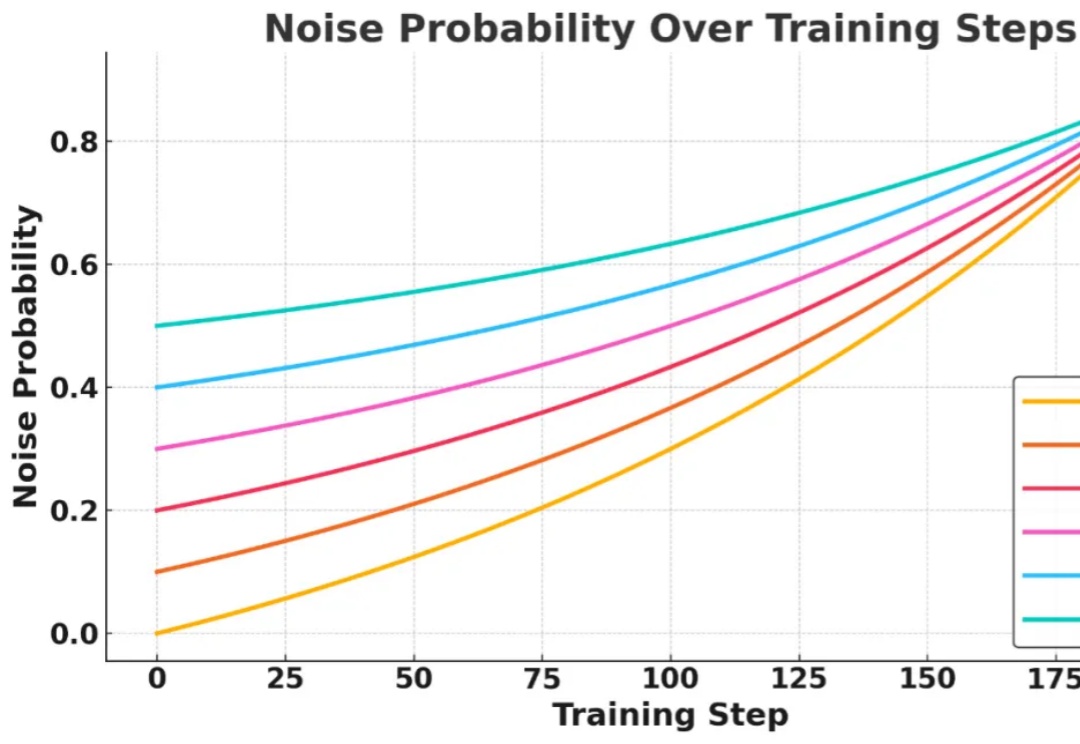
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:

来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。
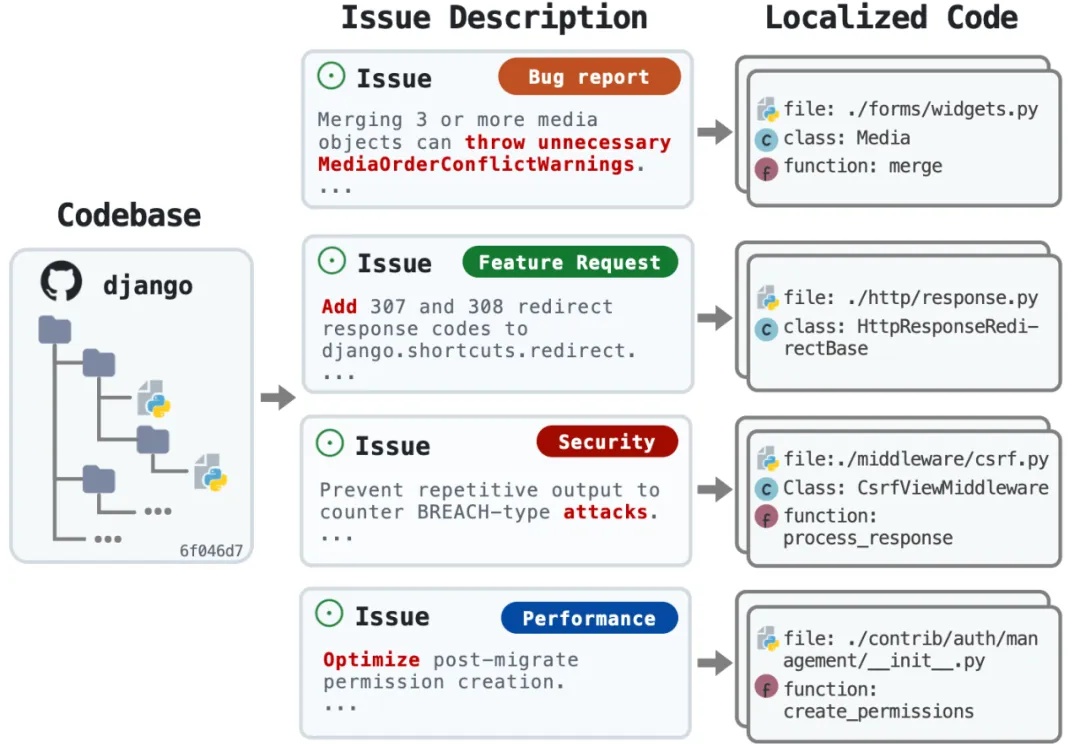
又是一个让程序员狂欢的研究!来自 OpenHands、耶鲁、南加大和斯坦福的研究团队刚刚发布了 LocAgent—— 一个专门用于代码定位的图索引 LLM Agent 框架,直接把代码定位准确率拉到了 92.7% 的新高度。该研究已被 ACL 2025 录用。

第一财经「新皮层」独家获得消息称,小红书已将内部大模型技术与应用产品团队升级为「hi lab」(人文智能实验室,Humane Intelligence Lab)。同时,小红书今年年初开始组建「AI人文训练师」团队,邀请有深厚人文背景的研究者与AI领域的算法工程师、科学家共同完成对AI的后训练,以训练AI具有更好的人文素养以及表现上的一致性。而这个「AI人文训练师」团队也隶属于「hi lab」。
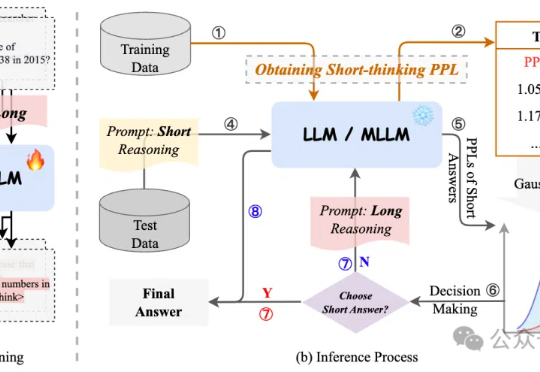
过度依赖CoT思维链推理会降低模型性能,有新解了! 来自字节、复旦大学的研究人员提出自适应推理框架CAR,能根据模型困惑度动态选择短回答或详细的长文本推理,最终实现了准确性与效率的最佳平衡。
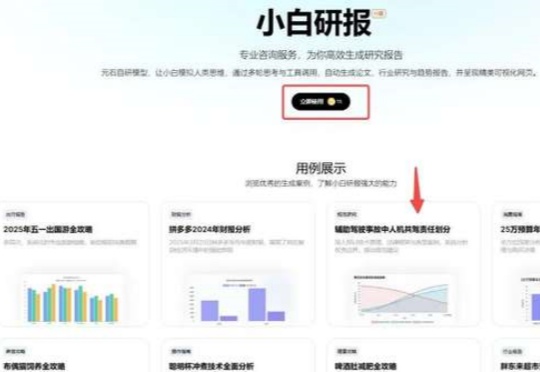
2025 年快要过半,今年上半年 AI 搜索、AI 深度研究类产品可谓是欣欣向荣。
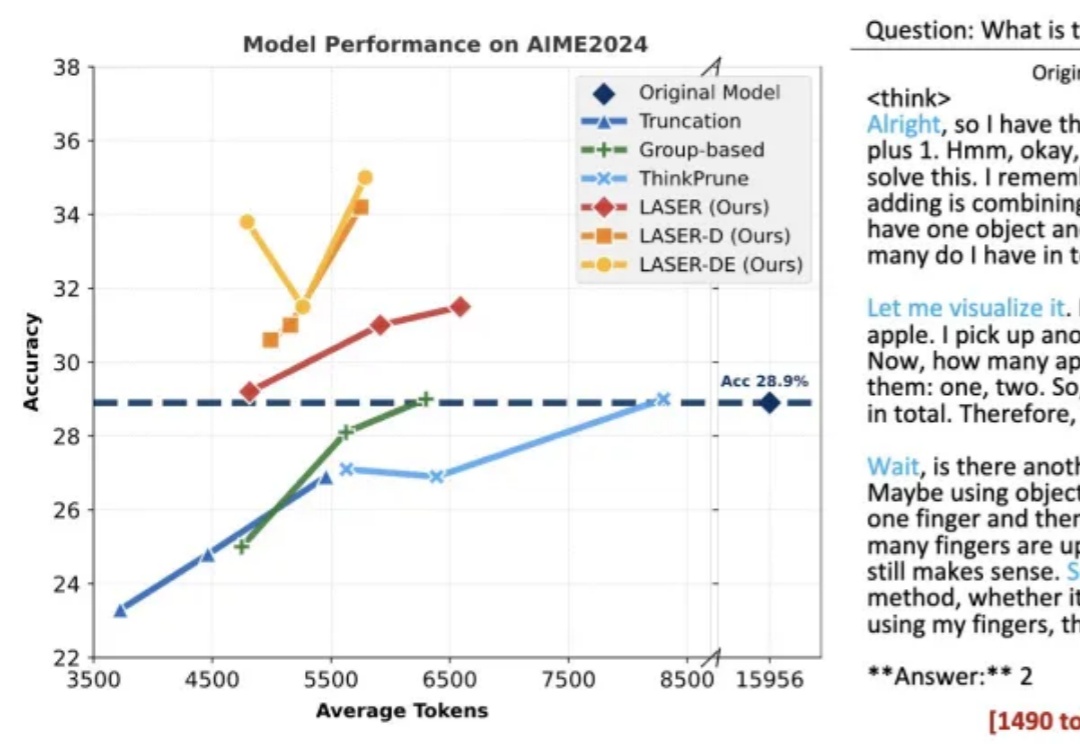
1+1等于几?
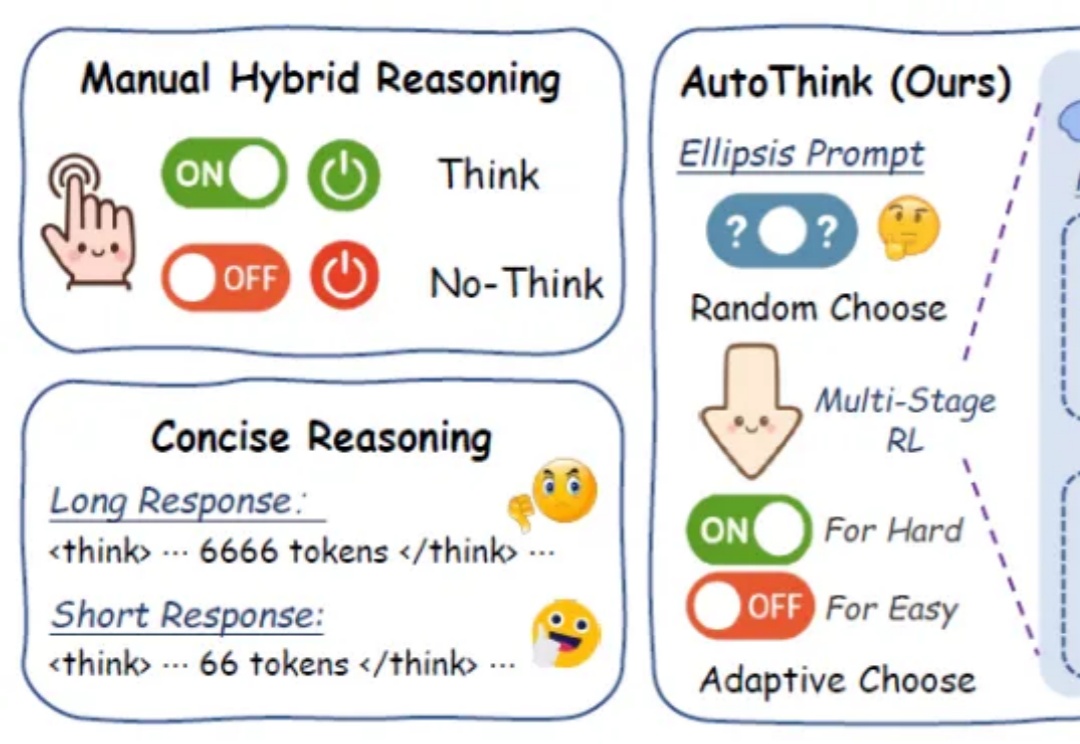
在日益强调“思维能力”的大语言模型时代,如何让模型在“难”的问题上展开推理,而不是无差别地“想个不停”,成为当前智能推理研究的重要课题。
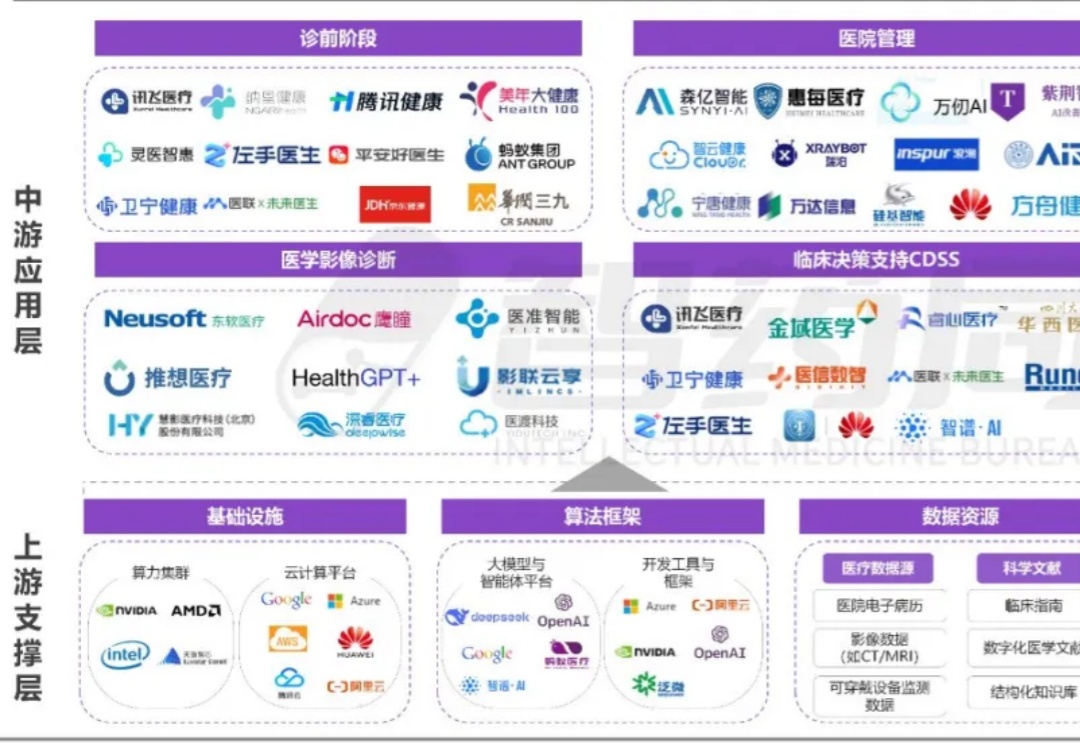
医疗站在变革的关键节点,AI正渗透行业的每一个角落,为资源分布不均、诊疗效率不高等深层次难题提供解决方案