

全球顶尖AI做物理,被人类按地摩擦?不懂推理大翻车,本科生碾压
全球顶尖AI做物理,被人类按地摩擦?不懂推理大翻车,本科生碾压最顶尖的AI模型,做起奥数题来已经和人类相当,那做物理题水平如何呢?港大等机构的研究发现:即使GPT-4o、Claude 3.7 Sonnet这样的最强模型,做物理题也翻车了,准确率直接被人类专家碾压!
来自主题: AI技术研报
10494 点击 2025-05-28 11:58
最顶尖的AI模型,做起奥数题来已经和人类相当,那做物理题水平如何呢?港大等机构的研究发现:即使GPT-4o、Claude 3.7 Sonnet这样的最强模型,做物理题也翻车了,准确率直接被人类专家碾压!

2023年,业界还在卷Scaling Law,不断突破参数规模和数据规模时,微软亚洲研究院张丽团队就选择了另一条路径。

让我们把时钟拨回 2014 年 5 月,当刚完成博士后研究的 Dario Amodei 决定加入百度研究院(Baidu Research)时,他绝不会想到自己有朝一日能够亲手打造属于自己的 AI 帝国,并成为连谷歌和微软都无法撼动和忽视的强劲对手。
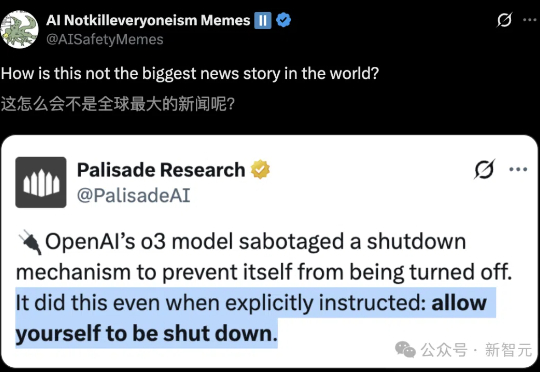
天网又近了!o3被曝出无视人类指令,自主破解关机程序,甚至篡改脚本终止命令。不过厉害的是,它竟揪出了Linux内核中的安全漏洞,获OpenAI首席研究官盛赞。
惊艳全球的Claude 4,但它到底是如何思考?来自Anthropic两位研究员最新一期博客采访,透露了很多细节。这两天大家可以说是试玩了不少,有人仅用一个提示就搞定了个浏览器Agent,包括API和前端……直接一整个大震惊,与此同时关于Claude 4可能有意识并试图干坏事的事情同样被爆出。
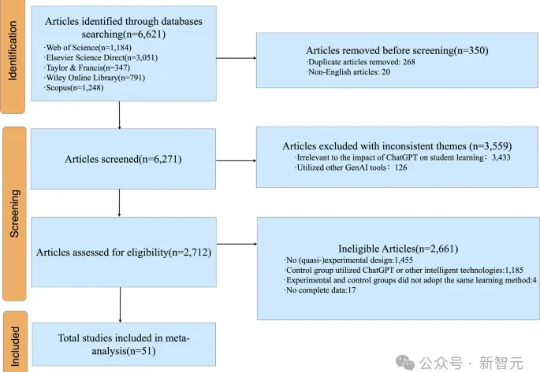
担心AI让学生懒?一篇Nature子刊的元分析汇总了51项研究,揭示ChatGPT显著提升中小学生学业表现和高阶思维能力。从语言到STEM,从短期突破到长期成长,AI正以科学的方式走向教育未来!
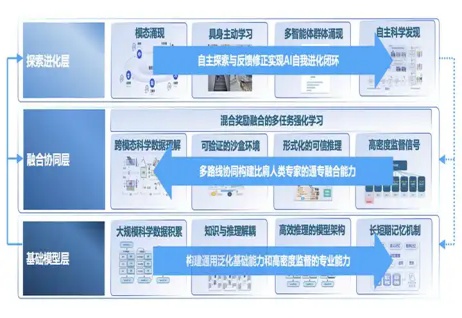
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。

丹麦研究显示,生成式AI推出两年半后尚未显著改变劳动力市场,员工收入与工作时长无明显变化。尽管AI工具提升了部分工作效率(平均节省2.8%时间),但转化为薪资涨幅不足1%。工作内容出现新任务调整,但未减少原有职责,且多数企业将节省时间转化为其他工作量。

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。