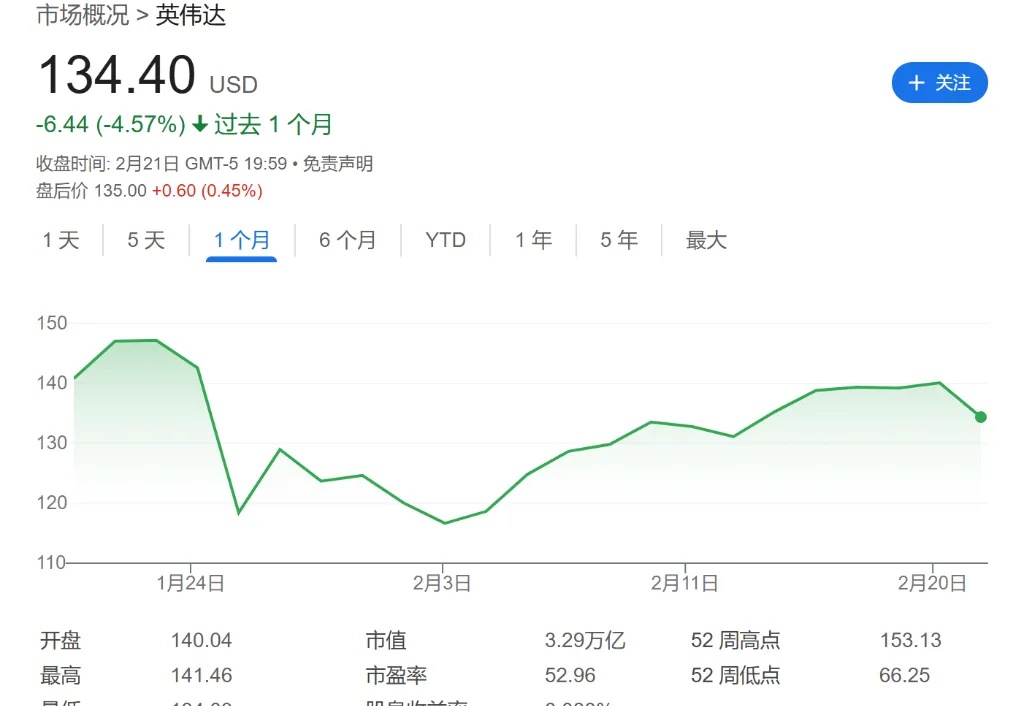
黄仁勋:市场对DeepSeek的理解完全搞反了
黄仁勋:市场对DeepSeek的理解完全搞反了DeepSeek的横空出世引发大模型算力逻辑的质疑,英伟达股价一度暴跌。然而,黄仁勋却在最新访谈中表示,市场对DeepSeek的理解“完全搞反了”。
来自主题: AI资讯
8282 点击 2025-02-23 11:33
 搜索
搜索
DeepSeek的横空出世引发大模型算力逻辑的质疑,英伟达股价一度暴跌。然而,黄仁勋却在最新访谈中表示,市场对DeepSeek的理解“完全搞反了”。
美国AI云服务商Together AI宣布完成3.05亿美元B轮融资,估值高达33亿美元!该公司押注开源模型,提供包括DeepSeek-R1在内的200多个模型API服务,并出租GPU算力,年收入已超1亿美元。

在AI计算资源日益稀缺的时代,Lambda凭借其独特的云GPU解决方案迅速崛起,成为资本市场的宠儿。最近,这家成立于2012年的AI云计算公司宣布完成4.8亿美元D轮融资,累计融资额达到8.63亿美元,跻身AI创投榜云科技赛道第二位,仅次于Coreweave。此次投资阵容强大,包括英伟达、AI技术大牛Andrej Karpathy,以及和硕、超微、纬创、纬颖等行业巨头的战略入股。

想象一下,一个放在手掌上的芯片,能解决当今地球上所有计算机加起来都无法解决的问题。

AI算力耗费的电能超出想象。
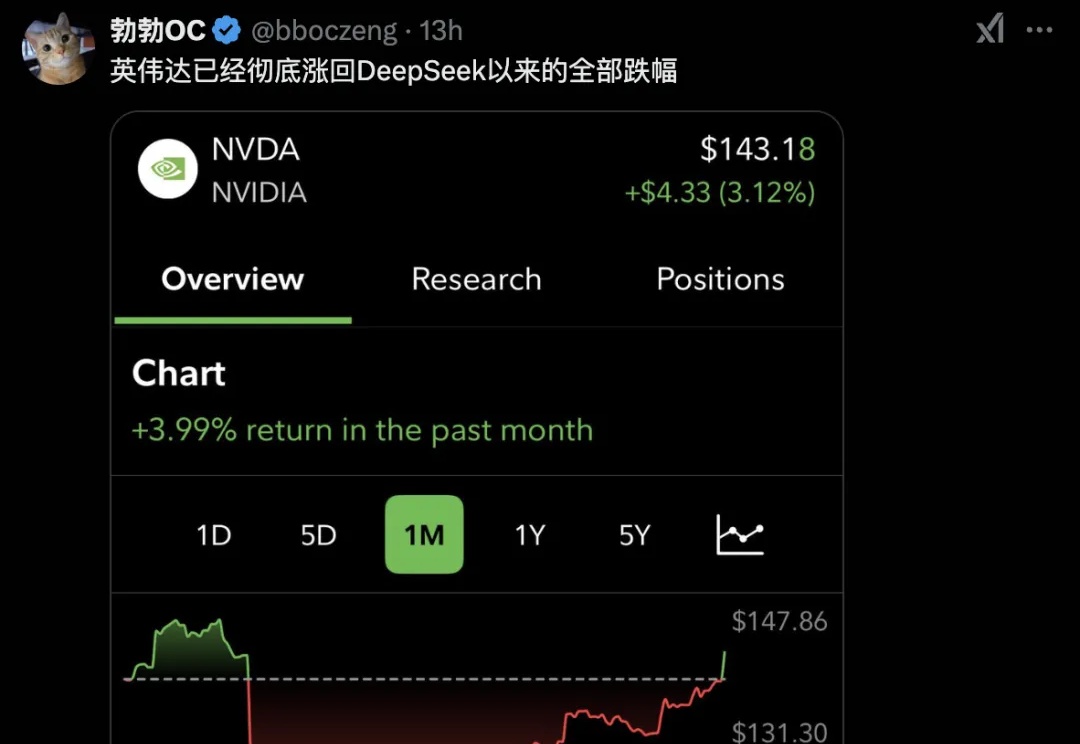
一度狂跌的英伟达股价,又被Grok-3盘活了?20万块GPU训出的模型超越DeepSeek和OpenAI,证明Scaling Law还在继续增长!Ai2研究者大佬直言:Grok-3,就是DeepSeek给美国AI企业压力的又一力证。
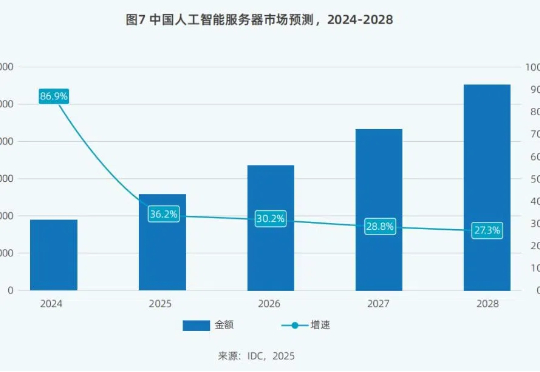
DeepSeek热潮将在预训练、后训练(二次训练)和推理三大细分市场都带来巨大改变。
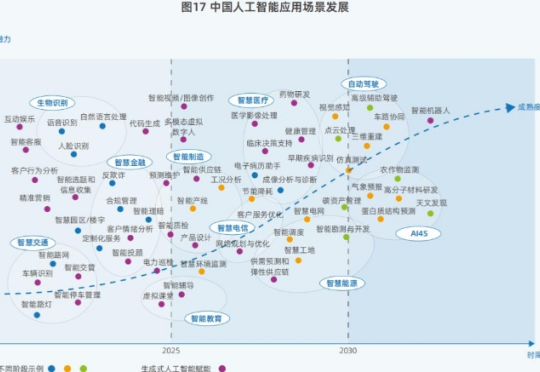
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。
唯一限制超级应用吞噬 AI 生态的,可能只有算力了。
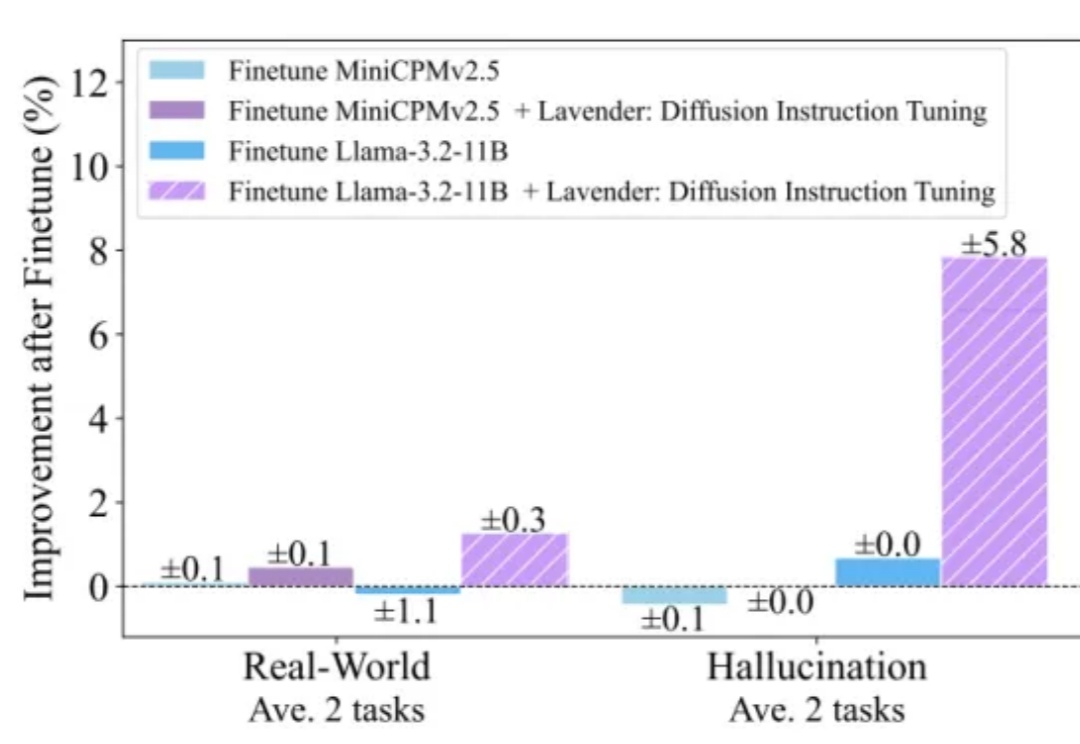
这次不是卷参数、卷算力,而是卷“跨界学习”——