小米模型实现声音理解新SOTA!数据吞吐效率暴增20倍,推理速度快4倍 | 全量开源
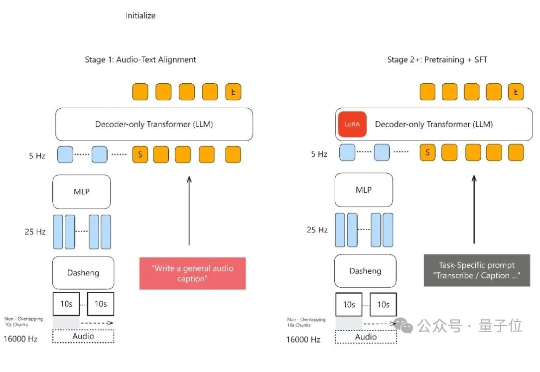
小米模型实现声音理解新SOTA!数据吞吐效率暴增20倍,推理速度快4倍 | 全量开源声音理解能力新SOTA,小米全量开源了模型。 MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
来自主题: AI技术研报
7838 点击 2025-08-06 12:11