
对话陈佳玉:从核聚变到机器人,是攀登AI珠峰的过程
对话陈佳玉:从核聚变到机器人,是攀登AI珠峰的过程本科毕业于北大工学院,早期研究聚焦于自动驾驶;博士后期间在卡内基梅隆大学,利用强化学习解决核聚变反应堆控制问题。陈佳玉的科研生涯,始终围绕着复杂系统的智能控制展开。
来自主题: AI资讯
7959 点击 2025-12-08 09:45
 搜索
搜索
本科毕业于北大工学院,早期研究聚焦于自动驾驶;博士后期间在卡内基梅隆大学,利用强化学习解决核聚变反应堆控制问题。陈佳玉的科研生涯,始终围绕着复杂系统的智能控制展开。
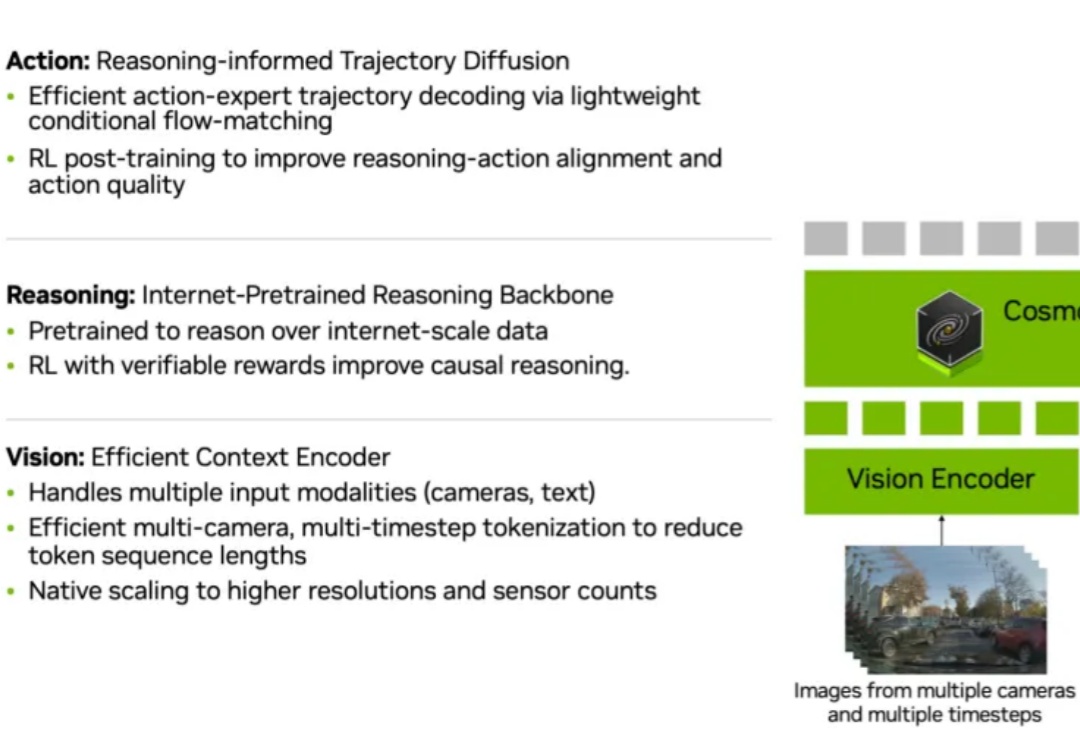
当今自动驾驶模型越来越强大,摄像头、雷达、Transformer 网络一齐上阵,似乎什么都「看得见」。但真正的挑战在于:模型能否像人一样「想明白」为什么要这么开?
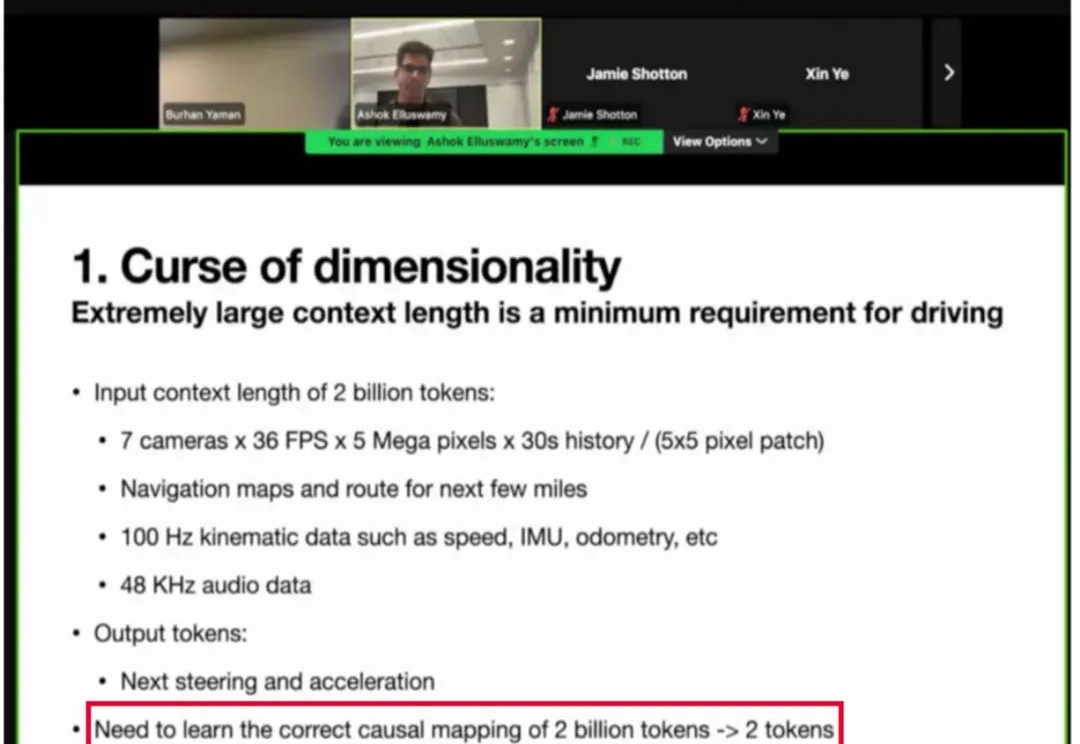
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。

智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。

在北京时间凌晨举办的英伟达 GTC 大会上,黄仁勋用一系列人类历史创新的剪影开场,并把英伟达与 AI 创新直接拔高定调为「下一个阿波罗时刻」。除了展示下一代超级芯片 Vera Rubin,黄仁勋还大谈 6G、量子计算,机器人和自动驾驶,同时宣布要投资新的巨头,舞台大屏上英伟达的「合作」对象名单可以说是密密麻麻。
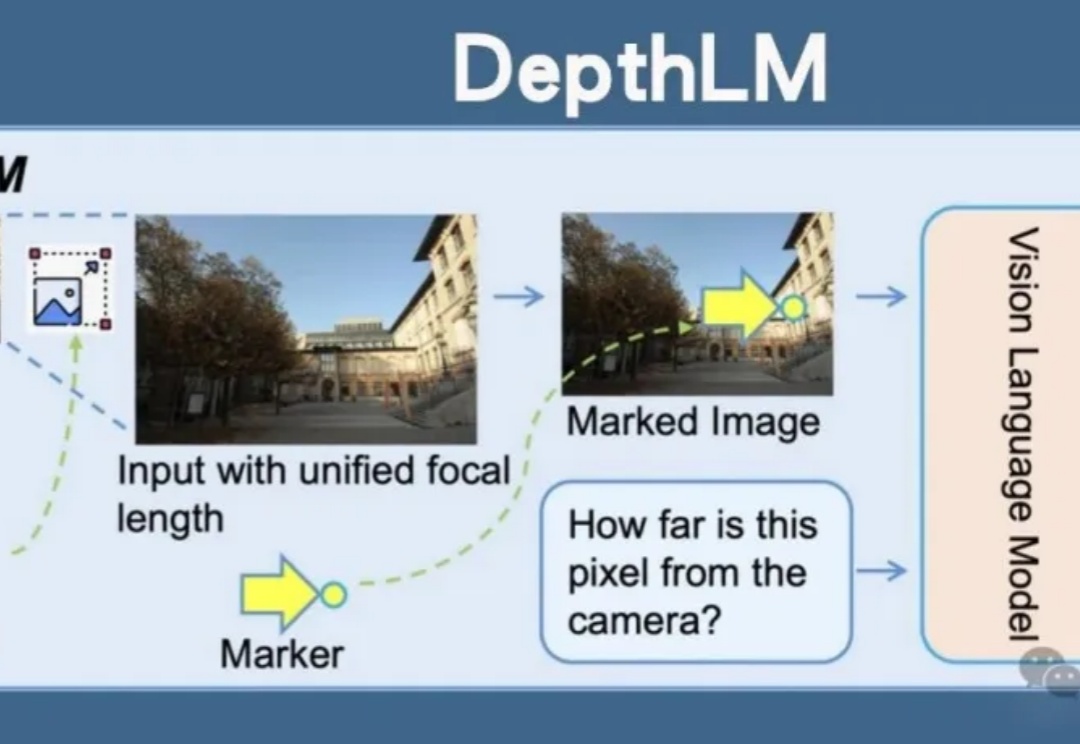
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
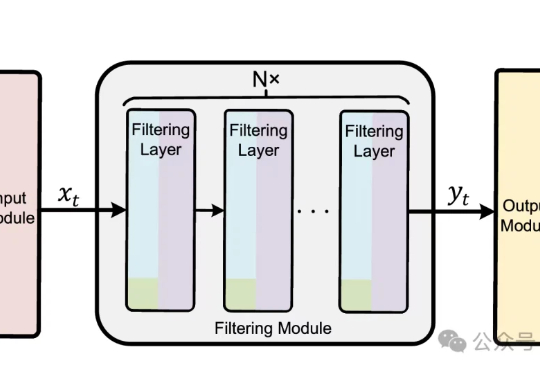
在机器人与自动驾驶领域,由强化学习训练的控制策略普遍存在控制动作不平滑的问题。这种高频的动作震荡不仅会加剧硬件磨损、导致系统过热,更会在真实世界的复杂扰动下引发系统失稳,是阻碍强化学习走向现实应用的关键挑战。

刚刚,加州大学洛杉矶分校(UCLA)副教授周博磊官宣加入机器人初创公司 Coco Robotics,专注于人行道自动驾驶这一难题!
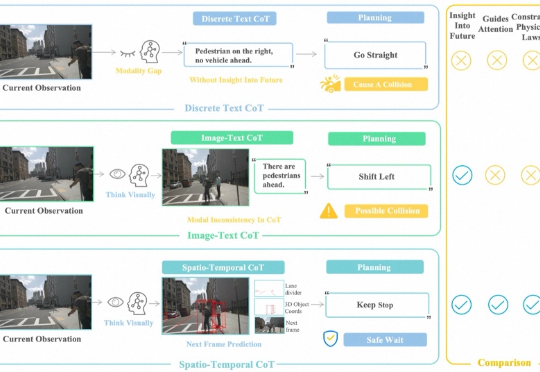
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
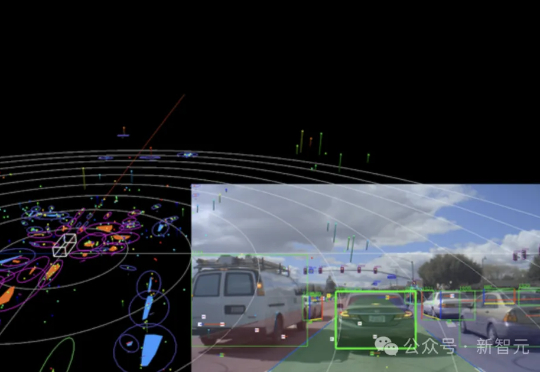
从重庆魔幻山城到全球Robotaxi布局,千里科技展现出将AI融入物理世界的雄心。董事长印奇的「千里计划」——One Brain, One OS, One Agent——勾勒出跨场景智能生态,让汽车成为高效、安全的现实世界入口和未来的人类伙伴。